
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- Deep dive: Experimental serverless CI/CD with SAP ...
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-11-2019
10:01 AM
Disclaimer: The setup described in this post is highly experimental. I encourage you to try this out in a demo project, but be very cautions until further notice to use this on productive code. In this proof of concept, I'll use a public GitHub repository and the free open-source offering by TravisCI. This setup is not suitable for commercial software.
The SAP Cloud SDK Continuous Delivery Toolkit helps you to deliver high-quality SAP extension applications rapidly. With regards to operations, we minimized the need for care with the cx-server life-cycle management greatly. Still, you need to run that Jenkins server. This means you'll need to update the server and plugins (simplified by our life-cycle management), and scale as the number of builds grows. User administration and backups are also required in a productive setup.
Is this really required, or is there an alternative approach?
In this blog post, I'll introduce a prototype I did to get rid of that long running pet Jenkins instance. Rather, we'll have cattle Jenkins instances, created and destroyed on demand. "Serverless" Jenkins in the sense that we don't have to provision the server for Jenkins to run.
The pets vs cattle metaphor describes how approaches in managing servers differ. While you care for pets and treat them when they are unwell, cattle can be easily replaced. Your traditional Jenkins server is a pet because it is often configured manually, and replacing it is a major effort. For more background on this metaphor, click here.
Before we're getting into the technical details, let's discuss why we would want to try this out in the first place. Running Jenkins on arbitrary CI/CD services, such as TravisCI seems very odd on first sight. On such services you'll usually invoke your build tools like Maven or npm in a small script, and that will do your build. But in the enterprise world, both inside SAP and in the community, Jenkins has a huge market share. There are many shared libraries for Jenkins, providing pre-made build steps which would be expensive to re-implement for other platforms. Additionally, SAP Cloud SDK Pipeline is a ready to use pipeline based on Jenkins where you as the developer of an SAP S/4HANA extension application do not need to write and maintain the pipeline yourself. This means reduced costs and effort for you, while the quality of your application improves, for example due to the many cloud qualities which are checked out of the box.
Let me show you an experiment to see if we can get the best of both worlds. The goal is to get all the quality checks and the continuous delivery that the SAP Cloud SDK Pipeline provides us, without the need for a pet Jenkins server.
How do we do that? The Jenkins project has a project called Jenkinsfile runner. It is a command line tool that basically boots up a stripped-down Jenkins instance, creates and runs a single job, and throws away that instance once the job is done. As you might guess, there is some overhead in that process. This will add about 20 seconds to each build, which I found to be surprisingly fast, considering the usual startup time of a Jenkins server. For convenient consumption, we have packaged Jenkinsfile runner as a Docker image which includes the Jenkins plugins that are required for SAP Cloud SDK Pipeline.
We also utilize the quite new Configuration as Code plugin for Jenkins, which allows to codify the Jenkins configuration as YAML files. As you will see in a minute, both Jenkinsfile runner and Configuration as Code are a perfect match.
If you want to follow along, feel free to use our provided Address Manager example application. You may fork the repository, or create your own repository and activate it on TravisCI.
Take care: TravisCI has two builds enabled by default for pull requests, one on the PR branch, and one with that merged to master. As of now, this means that a productive deployment is triggered for pull request builds. To avoid this, go to the settings of your project and disable "build pushed pull requests", keed "build pushed branches" enabled like in this screenshot.

Based on the existing Address Manager, let's add a small
The script line has quite a few things going on, let's see what is there.
We run a Docker container based on the
You might need some secrets in the build, for example in integration tests or for deployment to SAP Cloud Platform. You can make use of the travis command line tool to encrypt them on your local machine as documented here. Take care that this might add your secret in plain text to the shell history on your machine.
This command will add a line to your
We'll also need to add a
You might add more configuration to this file as you need it.
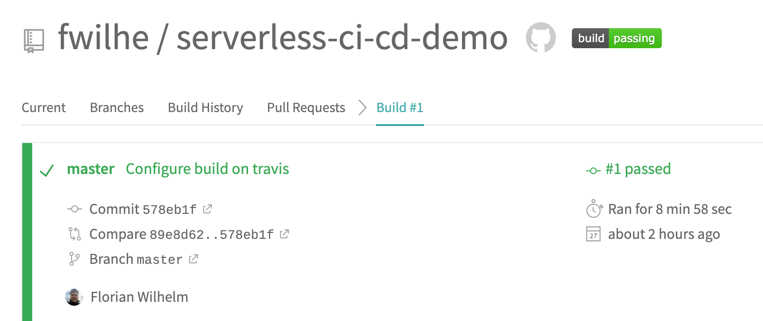
Commit both files to your repo and push. If the travis build works, you'll see the build integration on GitHub.

On travis, you can follow the progress of your build live, and get the full text log of your Jenkins build. If all went well, you will be greeted with a green build after a few minutes.

Congratulations. You're running a serverless Jenkins build with all the qualities checked by the SAP Cloud SDK Pipeline, without hosting your own Jenkins instance.
This setup also works in Microsoft's Azure Pipelines. To switch from Travis CI to Azure, we have to replace the
The resulting build is shown directly on GitHub:
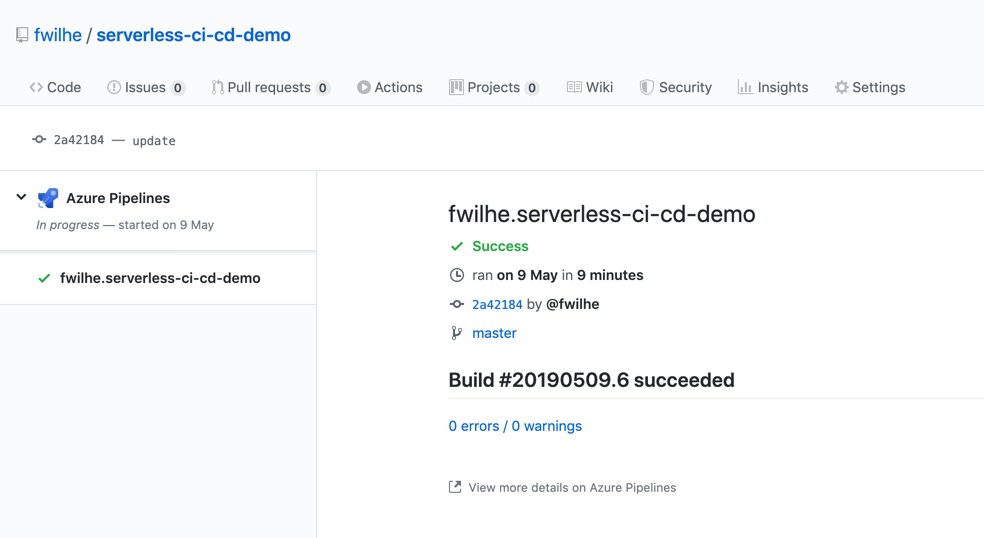
This shows that we're not locked into one provider for running our serverless Jenkins builds, both Travis CI and Azure Pipelines work for that use-case.
Keep in mind this is a proof of concept at this point. The serverless Jenkins ecosystem is currently evolving, and neither Jenkinsfile runner, nor Configuration as Code are in a mature state as of February 2019. One downside of this approach is that we lose the Jenkins user interface, so we can't see our pipeline in blue ocean, and we don't get the nice build summary. We can get the whole log output from TravisCI, so this can be mitigated, but this is arguable not the best user experience.
But on the contrary, we don't have to care for our pet Jenkins, we don't need to update plugins or backup the configuration or build logs.
So far, this is just a prototype. In following tests, it would be interesting to find out if operations costs can be decreased with such a setup in a real project. Getting this to run in more diverse environments (such as a Kubernetes cluster) might be a worthwhile and fun challenge, and could make sense from an economical perspective too. Also, some of the configuration details which are currently exposed to the user (like the Jenkins libraries and the mount of the tmp directory) could be packaged into the Docker image and thus make this setup more robust.
I'm very interested in your opinion about this. If you tried it out for yourself, be it in a public GitHub repo as I did, or in your companies' private infrastructure, please share your experiences in the comments. Do you think this could replace your pet Jenkins?
Disclaimer: The SAP Cloud SDK for Continuous Delivery and its features have been merged into project "Piper". Therefore we recommend to use the General Purpose Pipeline of project "Piper" instead of the SAP Cloud SDK pipeline. The reasoning for this change, as well as further information on how to adopt the General Purpose Pipeline are described in this guide.
The SAP Cloud SDK Continuous Delivery Toolkit helps you to deliver high-quality SAP extension applications rapidly. With regards to operations, we minimized the need for care with the cx-server life-cycle management greatly. Still, you need to run that Jenkins server. This means you'll need to update the server and plugins (simplified by our life-cycle management), and scale as the number of builds grows. User administration and backups are also required in a productive setup.
Is this really required, or is there an alternative approach?
In this blog post, I'll introduce a prototype I did to get rid of that long running pet Jenkins instance. Rather, we'll have cattle Jenkins instances, created and destroyed on demand. "Serverless" Jenkins in the sense that we don't have to provision the server for Jenkins to run.
The pets vs cattle metaphor describes how approaches in managing servers differ. While you care for pets and treat them when they are unwell, cattle can be easily replaced. Your traditional Jenkins server is a pet because it is often configured manually, and replacing it is a major effort. For more background on this metaphor, click here.
Before we're getting into the technical details, let's discuss why we would want to try this out in the first place. Running Jenkins on arbitrary CI/CD services, such as TravisCI seems very odd on first sight. On such services you'll usually invoke your build tools like Maven or npm in a small script, and that will do your build. But in the enterprise world, both inside SAP and in the community, Jenkins has a huge market share. There are many shared libraries for Jenkins, providing pre-made build steps which would be expensive to re-implement for other platforms. Additionally, SAP Cloud SDK Pipeline is a ready to use pipeline based on Jenkins where you as the developer of an SAP S/4HANA extension application do not need to write and maintain the pipeline yourself. This means reduced costs and effort for you, while the quality of your application improves, for example due to the many cloud qualities which are checked out of the box.
Let me show you an experiment to see if we can get the best of both worlds. The goal is to get all the quality checks and the continuous delivery that the SAP Cloud SDK Pipeline provides us, without the need for a pet Jenkins server.
How do we do that? The Jenkins project has a project called Jenkinsfile runner. It is a command line tool that basically boots up a stripped-down Jenkins instance, creates and runs a single job, and throws away that instance once the job is done. As you might guess, there is some overhead in that process. This will add about 20 seconds to each build, which I found to be surprisingly fast, considering the usual startup time of a Jenkins server. For convenient consumption, we have packaged Jenkinsfile runner as a Docker image which includes the Jenkins plugins that are required for SAP Cloud SDK Pipeline.
We also utilize the quite new Configuration as Code plugin for Jenkins, which allows to codify the Jenkins configuration as YAML files. As you will see in a minute, both Jenkinsfile runner and Configuration as Code are a perfect match.
If you want to follow along, feel free to use our provided Address Manager example application. You may fork the repository, or create your own repository and activate it on TravisCI.
Take care: TravisCI has two builds enabled by default for pull requests, one on the PR branch, and one with that merged to master. As of now, this means that a productive deployment is triggered for pull request builds. To avoid this, go to the settings of your project and disable "build pushed pull requests", keed "build pushed branches" enabled like in this screenshot.
Based on the existing Address Manager, let's add a small
.travis.yml file to instruct the build:language: minimal
services:
- docker
script: docker run -v /var/run/docker.sock:/var/run/docker.sock -v ${PWD}:/workspace -v /tmp -e CASC_JENKINS_CONFIG=/workspace/jenkins.yml -e CF_PW -e ERP_PW -e BRANCH_NAME=$TRAVIS_BRANCH ppiper/jenkinsfile-runner
The script line has quite a few things going on, let's see what is there.
We run a Docker container based on the
ppiper/jenkinsfile-runner image. We need to mount the Docker socket, so that our container can spawn sibling containers for tooling such as Maven or the CloudFoundry CLI. We also need to mount the current directory (root of our project) to /workspace, and tell the Jenkins Configuration as Code Plugin where to find the configuration file. We'll come to that file in a minute. Also be sure to pass your secret variables here. Travis will mask them, so they are not in plain text in your build log. Take note to change the names of the variables according to your requirements. You might wonder that we need a BRANCH_NAME environment variable. This is required for the Pipeline to check if you're working on the "productive branch", where a productive deployment to SAP Cloud Platform is supposed to happen. If you omit passing this variable, the pipeline will still run but never in the productive mode, and hence not deploy to SAP Cloud Platform.You might need some secrets in the build, for example in integration tests or for deployment to SAP Cloud Platform. You can make use of the travis command line tool to encrypt them on your local machine as documented here. Take care that this might add your secret in plain text to the shell history on your machine.
travis encrypt CF_PW=supersecret --addtravis encrypt ERP_PW=alsosupersecret --addThis command will add a line to your
.travis.yml file with the encrypted secret value. Be sure to commit this change. Also take note of the name of your variable, which must match the environment parameter, and your Jenkins configuration. Also take note of this TravisCI document on secrets.We'll also need to add a
jenkins.yml file to our project. Here we need to configure two shared libraries which are required for the SAP Cloud SDK Pipeline, and the credentials that are required for our pipeline. Be sure not to put your secrets in plain text in here, but use the variables you used before via the travis cli tool. TravisCI will decrypt the password on the fly for you.jenkins:
numExecutors: 10
unclassified:
globallibraries:
libraries:
- defaultVersion: "master"
name: "s4sdk-pipeline-library"
retriever:
modernSCM:
scm:
git:
remote: "https://github.com/SAP/cloud-s4-sdk-pipeline-lib.git"
- defaultVersion: "master"
name: "piper-library-os"
retriever:
modernSCM:
scm:
git:
remote: "https://github.com/SAP/jenkins-library.git"
credentials:
system:
domainCredentials:
- credentials:
- usernamePassword:
scope: GLOBAL
id: "MY-ERP"
username: MY_USER
password: ${ERP_PW}
- usernamePassword:
scope: GLOBAL
id: "cf"
username: P12344223
password: ${CF_PW}
You might add more configuration to this file as you need it.
Commit both files to your repo and push. If the travis build works, you'll see the build integration on GitHub.
On travis, you can follow the progress of your build live, and get the full text log of your Jenkins build. If all went well, you will be greeted with a green build after a few minutes.
Congratulations. You're running a serverless Jenkins build with all the qualities checked by the SAP Cloud SDK Pipeline, without hosting your own Jenkins instance.
This setup also works in Microsoft's Azure Pipelines. To switch from Travis CI to Azure, we have to replace the
.travis.yml file with this azure-pipelines.yml file, and configure the used credentials in the Azure user interface:trigger:
- master
pool:
vmImage: 'Ubuntu-16.04'
timeoutInMinutes: 0
steps:
- script: docker run -v /var/run/docker.sock:/var/run/docker.sock -v ${PWD}:/workspace -v /tmp -e CASC_JENKINS_CONFIG=/workspace/jenkins.yml -e CF_PW -e ERP_PW -e BRANCH_NAME=$(Build.SourceBranchName) ppiper/jenkinsfile-runner
displayName: 'Run pipeline'
env:
CF_PW: $(cfPassword)
ERP_PW: $(erpPassword)The resulting build is shown directly on GitHub:
This shows that we're not locked into one provider for running our serverless Jenkins builds, both Travis CI and Azure Pipelines work for that use-case.
Keep in mind this is a proof of concept at this point. The serverless Jenkins ecosystem is currently evolving, and neither Jenkinsfile runner, nor Configuration as Code are in a mature state as of February 2019. One downside of this approach is that we lose the Jenkins user interface, so we can't see our pipeline in blue ocean, and we don't get the nice build summary. We can get the whole log output from TravisCI, so this can be mitigated, but this is arguable not the best user experience.
But on the contrary, we don't have to care for our pet Jenkins, we don't need to update plugins or backup the configuration or build logs.
So far, this is just a prototype. In following tests, it would be interesting to find out if operations costs can be decreased with such a setup in a real project. Getting this to run in more diverse environments (such as a Kubernetes cluster) might be a worthwhile and fun challenge, and could make sense from an economical perspective too. Also, some of the configuration details which are currently exposed to the user (like the Jenkins libraries and the mount of the tmp directory) could be packaged into the Docker image and thus make this setup more robust.
I'm very interested in your opinion about this. If you tried it out for yourself, be it in a public GitHub repo as I did, or in your companies' private infrastructure, please share your experiences in the comments. Do you think this could replace your pet Jenkins?
- SAP Managed Tags:
- SAP S/4HANA
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
23 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
24 -
Expert Insights
114 -
Expert Insights
158 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
415 -
Life at SAP
2 -
Product Updates
4,684 -
Product Updates
218 -
Roadmap and Strategy
1 -
Technology Updates
1,502 -
Technology Updates
89
Related Content
- Streamlining Real-time Business Processes with SAP Event Mesh: A Prototype Exploration in Enterprise Resource Planning Blogs by SAP
- Safeguard your Investments with Red Hat OpenShift in Enterprise Resource Planning Blogs by Members
- Deep Dive with SAP Cloud SDK: Consuming Messages representing Business Events from SAP S/4HANA Cloud in Enterprise Resource Planning Blogs by SAP
- How ERP is Incorporating Blockchain Technology in Enterprise Resource Planning Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 4 | |
| 4 | |
| 4 |