
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Using Private Data in Hyperledger Fabric
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member23
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-01-2019
3:57 AM
I recently stumbled across the Using SideDB to Store Private Data SAP Help article and decided to try out the described functionality. It turned out that the example code provided in the article was created for Hyperledger Fabric v1.2 and can actually be simplified for the current version 1.3 available on the SAP Cloud Platform.
Let's have a closer look.
In order to get the right context of the task, please have a look at this document explaining the terminology and use cases for private data. Here in this blog we would just like to create our own implementation of the service deployed on the SAP Cloud Platform, which would save and retrieve the private data passed inside transient fields. We would also like to check how to configure access to the private data.
As you can see in the original article already mentioned above, the access control logic for the private data has to be implemented by developers themselves. This is despite the fact that developers also have to describe access by organisations in the collection-config.json file.
According to the v1.4 release notes, Hyperledger Fabric service is able to automatically enforce access control based on the collection-config.json definition only.
However, the current Hyperledger Fabric service version deployed to the SAP Cloud Platform is 1.3. Still, v1.3 does support private collections separation between different organisations.
Let's check it out by removing the implicit code checks provided in the SAP Help example.
In order to check the functionality, I used a trial Hyperledger Fabric service instance. I've also published the code in my repository. So you can use your SAP Cloud Platform account to clone&deploy the project and play around with the settings.
The files and folders structure has remained same as before:
I have removed the permissions checks for collections in the main.go and left only the read/write methods for the channels and collections:
As you already aware, the private data for the collections is passed via transient fields and is retrieved by the GetTransient method.
The collections are read and written by the GetPrivateData and PutPrivateData methods as below:
Before we define the collections, let's have a look into the blockchain network available for the trial Hyperledger Fabric instance:

As we can see, the "dev" plan offers only the single "devMSP" organisation in the network. We will be using it for the config just a few lines below.
To illustrate usage of private data, let's create two collections in the collection-config.json:
Here the first collection named "collection1" has the following properties:
The second collection "collection2" has similar settings with the most significant one being the "policy". We've assigned the "collection2" to a non-existent organisation "devMSP2" just in order to check that we won't have access to it as members of organisation "devMSP". The "blockToLive" value is set to "0" meaning the collection items will be kept on the private database indefinitely.
We deploy our chaincode as a zip archive consisting of the following files including the src folder:
The collection-config.json file is added to the network separately after installation when the chaincode is being instantiated or upgraded. Please see the screen captures below:

Once initially installed, it can be instantiated:

And the collection config is provided:

So now we've got the instance with its Id highlighted below:

Let's see how it works.
So now we can jump to the SAP API Hub and log in there. Once the API call environment is configured, the service invocations can be performed as per below screen captures (please also see Step 2 in my previous blog for a quick reference).
Let's post some dummy "test value" via the "value" transient field:

The received response is "200":

That was the payload used:
Side note. If you had a couple of JSON objects passed as a parameter and a transient object, your payload would look as follows:
Let's read the contents of the private data:

The recorded dummy value is returned successfully:

Now if we press the Execute button three more times, the data will become unavailable on the fourth invocation. This is because the "blockToLive" property value was set to "3" in the collection definition. It actually means that the private data will live in the side db for only 3 subsequent blockchain transactions (newly created blocks), after which it gets purged. The Query API calls do not create new transactions on the ledger and, therefore, can be executed unlimited number of times to return the private data values if they were not removed.
As you remember, we have the "collection2" defined in our collection-config.json file. That collection is associated with the non-existent organisation "devMSP2". Unfortunately, we cannot switch our organisation under the trial account. Let's try to write and read a couple of private data samples belonging to the "collection2" while being a member of the "devMSP".
Theoretically speaking, we should not be allowed to perform any operation on the collection. However, the "writeCollection" invocation with the following payload succeeds:

Once we try to read the same piece of private data, the access is forbidden.
We're only able to see the public hash of the private data belonging to a different organisation, which is exactly what we would like to see:
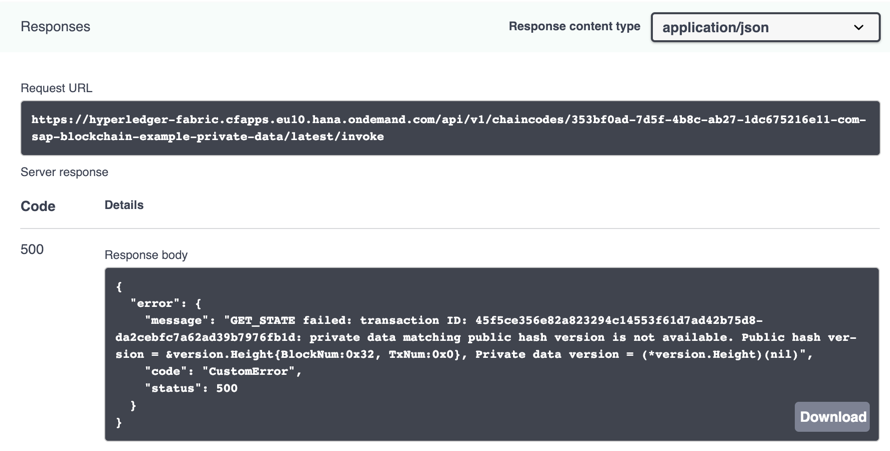
This actually proves our initial statement that access to the private data can be controlled by the collections configuration without writing explicit access control logic in chaincode.
Storing sensitive data off-chain is a very useful feature for potential customers. Here we have tried out the private data tools provided by the Hyperledger Fabric service. The solution looks usable and secure if implemented properly. Please bear in mind that it's developing rapidly, so a lot of cool features will be introduced in the nearest releases. Stay tuned!
Let's have a closer look.
Prerequisites
In order to get the right context of the task, please have a look at this document explaining the terminology and use cases for private data. Here in this blog we would just like to create our own implementation of the service deployed on the SAP Cloud Platform, which would save and retrieve the private data passed inside transient fields. We would also like to check how to configure access to the private data.
As you can see in the original article already mentioned above, the access control logic for the private data has to be implemented by developers themselves. This is despite the fact that developers also have to describe access by organisations in the collection-config.json file.
According to the v1.4 release notes, Hyperledger Fabric service is able to automatically enforce access control based on the collection-config.json definition only.
However, the current Hyperledger Fabric service version deployed to the SAP Cloud Platform is 1.3. Still, v1.3 does support private collections separation between different organisations.
Let's check it out by removing the implicit code checks provided in the SAP Help example.
The code
In order to check the functionality, I used a trial Hyperledger Fabric service instance. I've also published the code in my repository. So you can use your SAP Cloud Platform account to clone&deploy the project and play around with the settings.
The files and folders structure has remained same as before:
- collection-config.json
- chaincode.yaml
- src
-- main.goI have removed the permissions checks for collections in the main.go and left only the read/write methods for the channels and collections:
// Invoke is called to update or query the ledger in a proposal transaction.
func (cc *privateWorld) Invoke(stub shim.ChaincodeStubInterface) peer.Response {
function, args := stub.GetFunctionAndParameters()
switch function {
case "readCollection":
transient, err := stub.GetTransient()
if err != nil {
return shim.Error(err.Error())
}
return cc.readCollection(stub, transient)
case "writeCollection":
transient, err := stub.GetTransient()
if err != nil {
return shim.Error(err.Error())
}
return cc.writeCollection(stub, transient)
case "read":
return cc.read(stub, args)
case "write":
return cc.write(stub, args)
default:
return shim.Error("Valid methods are 'writeCollection|readCollection|write'!")
}
}As you already aware, the private data for the collections is passed via transient fields and is retrieved by the GetTransient method.
The collections are read and written by the GetPrivateData and PutPrivateData methods as below:
// Read text by ID from private collection
func (cc *privateWorld) readCollection(stub shim.ChaincodeStubInterface, transient map[string][]byte) peer.Response {
col := string(transient["collection"])
id := strings.ToLower(string(transient["id"]))
if value, err := stub.GetPrivateData(col, id); err == nil {
if value != nil {
return shim.Success(value)
}
return shim.Error("Not Found")
} else {
return shim.Error(err.Error())
}
}
// Write text into private collection
func (cc *privateWorld) writeCollection(stub shim.ChaincodeStubInterface, transient map[string][]byte) peer.Response {
col := string(transient["collection"])
id := strings.ToLower(string(transient["id"]))
txt := string(transient["value"])
if err := stub.PutPrivateData(col, id, []byte(txt)); err != nil {
return shim.Error(err.Error())
}
return shim.Success(nil)
}Collections configuration
Before we define the collections, let's have a look into the blockchain network available for the trial Hyperledger Fabric instance:
As we can see, the "dev" plan offers only the single "devMSP" organisation in the network. We will be using it for the config just a few lines below.
To illustrate usage of private data, let's create two collections in the collection-config.json:
[{
"name": "collection1",
"policy": "OR('devMSP.member')",
"requiredPeerCount": 0,
"maxPeerCount": 2,
"blockToLive": 3
},{
"name": "collection2",
"policy": "OR('devMSP2.member')",
"requiredPeerCount": 0,
"maxPeerCount": 3,
"blockToLive": 0
}]Here the first collection named "collection1" has the following properties:
- "policy" and "memberOnlyRead" define the collection accessibility by only the members of the "devMSP" organisation.
- the "requiredPeerCount" property is set to "0" meaning there is no need to disseminate the private data to other peers. This setting is not significant for our scenario.
- the "maxPeerCount" is set to "2" to indicate how many peers will keep the data redundantly. It's also not of the great significance for this case.
- the "blockToLive" value is set to "3" in order to test that the records are purged after 3 subsequent ledger invocations (we will check this option below).
The second collection "collection2" has similar settings with the most significant one being the "policy". We've assigned the "collection2" to a non-existent organisation "devMSP2" just in order to check that we won't have access to it as members of organisation "devMSP". The "blockToLive" value is set to "0" meaning the collection items will be kept on the private database indefinitely.
Deployment
We deploy our chaincode as a zip archive consisting of the following files including the src folder:
- chaincode.yaml
- src
-- main.goThe collection-config.json file is added to the network separately after installation when the chaincode is being instantiated or upgraded. Please see the screen captures below:
Once initially installed, it can be instantiated:
And the collection config is provided:
So now we've got the instance with its Id highlighted below:
Let's see how it works.
Calling the API
So now we can jump to the SAP API Hub and log in there. Once the API call environment is configured, the service invocations can be performed as per below screen captures (please also see Step 2 in my previous blog for a quick reference).
Let's post some dummy "test value" via the "value" transient field:
The received response is "200":
That was the payload used:
{
"function": "writeCollection",
"transient": {
"collection": "collection1",
"id": "1122",
"value": "test value"
}
}Side note. If you had a couple of JSON objects passed as a parameter and a transient object, your payload would look as follows:
{
"function": "createOrder",
"arguments": [
"{\"agreementNumber\": \"01234567\",\"invoiceNumber\": \"1234\",\"invoiceDate\": \"2020-01-14T10:02:33Z\",\"deliveryAddress\": \"484 St Kilda Road, St Kilda\"}"
],
"transient": {
"privateDetails": {
"invoiceAmount": 2000,
"paymentDueDate": "2020-01-24T10:02:33Z",
"customer": {
"number": "0123456789",
"account": "12345678",
"name": "SAP SE"
}
}
}
}Let's read the contents of the private data:
The recorded dummy value is returned successfully:
Now if we press the Execute button three more times, the data will become unavailable on the fourth invocation. This is because the "blockToLive" property value was set to "3" in the collection definition. It actually means that the private data will live in the side db for only 3 subsequent blockchain transactions (newly created blocks), after which it gets purged. The Query API calls do not create new transactions on the ledger and, therefore, can be executed unlimited number of times to return the private data values if they were not removed.
Calling the API for the second private collection
As you remember, we have the "collection2" defined in our collection-config.json file. That collection is associated with the non-existent organisation "devMSP2". Unfortunately, we cannot switch our organisation under the trial account. Let's try to write and read a couple of private data samples belonging to the "collection2" while being a member of the "devMSP".
Theoretically speaking, we should not be allowed to perform any operation on the collection. However, the "writeCollection" invocation with the following payload succeeds:
{
"function": "writeCollection",
"transient": {
"collection": "collection2",
"id": "1215",
"value": "test value 5"
}
}Once we try to read the same piece of private data, the access is forbidden.
{
"function": "readCollection",
"transient": {
"collection": "collection2",
"id": "1215"
}
}We're only able to see the public hash of the private data belonging to a different organisation, which is exactly what we would like to see:
This actually proves our initial statement that access to the private data can be controlled by the collections configuration without writing explicit access control logic in chaincode.
Conclusion
Storing sensitive data off-chain is a very useful feature for potential customers. Here we have tried out the private data tools provided by the Hyperledger Fabric service. The solution looks usable and secure if implemented properly. Please bear in mind that it's developing rapidly, so a lot of cool features will be introduced in the nearest releases. Stay tuned!
- SAP Managed Tags:
- Blockchain,
- SAP Business Technology Platform
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Recap — SAP Data Unleashed 2024 in Technology Blogs by Members
- Join the upcoming CEI project in 2024 for SAP Integration Suite in Technology Blogs by SAP
- AI Foundation, SAP’s all-in-one AI toolkit for developers in Technology Blogs by SAP
- Top 10 takeaways #SAPTeched 2023 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |