
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Introducing SAP Data Hub
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member27
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-27-2018
9:27 AM

In this article I would like introduce SAP Data Hub as a modern data platform that combines raw data and with data from enterprise landscapes together to address a common problem. With the massive generation of information from the advent of the internet and the increasing digitization of business, there is tremendous opportunity in the new amounts and types of data collected. But this increase has also dramatically increased the complexity of the enterprise data landscape, with multiple data lakes, data warehouses, operational applications, eCommerce, online interactions, and so on.
IT is under tremendous pressure to respond to business needs - an increasing number of internal customers who want new analytics, new applications, and better data sharing with partners quickly.
SAP Data Hub is a data operations (DataOps) management solution that enables agile management of data in a diverse landscape across the organization. This enterprise-ready solution provides governance and orchestration for data refinement and enrichment, using pipelining of many complex data processing operations, like machine learning (ML).
For more information watch the video.
https://www.sap.com/assetdetail/2018/04/566834fa-fe7c-0010-87a3-c30de2ffd8ff.html
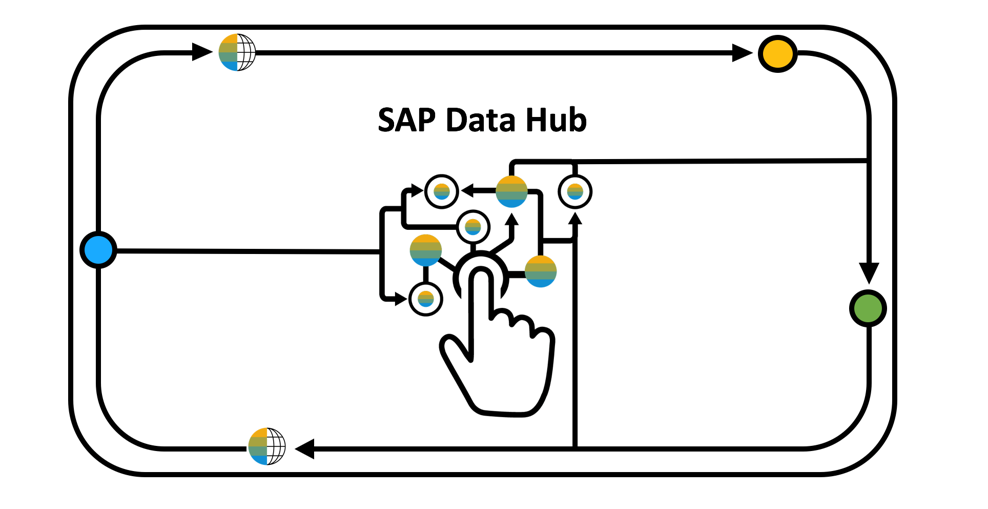
Today, enterprise customers are finding it too slow, expensive, and challenging to move data to where it needs to go. This is due to:
Rapidly evolving and expanding data landscapes, with more data silos than ever.
- Increasing number of ways to create data – more applications, digital interactions, sensors, social media, web-based sources
- Quick rise in data volume growth and data diversity – driving the data silo proliferation
- Increasing number of data consumption endpoints – analytics, enterprise apps, mobile apps, cloud apps
Data silos are reinforced by organizational silos
- For example, the Big Data teams managing the Hadoop data lakes are not the same as the people managing the EDW. They use different tools and don’t interact often. Also, business departments often have their own data and their own people managing them. At the overall landscape level, it’s hard to look across all of the systems and information.
To be able to better meet the needs of business and the fast pace of today’s demands, the landscape needs to overcome three challenges:
1. Governance challenge: Lack of visibility. Who changed the data? What was changed? Who is accessing it?
- Example: Where did this strange result come from? Who did it? Financial manager reviews a table, finds an unusual result, traces it back to see that someone mistakenly averaged two averages together from different systems.
2. Data Pipeline challenge: Too hard to refine and enrich data across multiple systems.
- Refine: running computations to move from raw data to candidate data.
- Enrich: append data from different sources together to create a more robust compilation of information
IOT example:
- Enrich data by appending information from other systems, such as connecting sensor data with the asset ID and asset profile information, held in a different system.
- Refine the data by taking the temperature information from the asset sensors to determine how many times assets have gone above the recommended temperature maximum. That takes data from a high volume data store, processes it, and passes that structured result on, where it goes ultimately to an executive’s analytical dashboard, or even to a mobile field rep’s smartphone app, so they can investigate quickly
Social product feedback example:
- Refinement: You’ve launched a new, colorful, line of Instagram-friendly products. From raw social media feeds, count the number that are positive versus the amount that are negative.
- Enrich: Harmonize with a product ID, so that you can line up positive/negative comment totals with what people are praising or complaining about.
- Results can be passed along to product managers, who can use it to evolve the future product, to the services team, to address any negative reviews, or to marketing, to capitalize on a positive trend.
3. Data sharing challenge:
Integration is manual, point-to-point, painful, and slow. If you want to change an integration point or add more points to an integration path, good luck. Get in the IT line and wait for six months.
New challenges require new technologies: Distributed systems in a distributed landscape

Unify your data to achieve scalable visibility and control

Single system view – for data pipelining, orchestration, monitoring, and governance
No centralization of data – no mass data movement to a single data store
Distributed native processing – executes pipeline activities quickly, where the data resides
SAP Data Hub UI:

The VISION for SAP Data Hub is to provide the ability to understand, connect, and drive processes across the multiple data sources and endpoints with which the enterprise struggles today. By providing visibility into the landscape of data opportunities, as well as providing an easy way to connect data sources and easily create powerful data pipelines that hop across the landscape, businesses can better achieve the data agility and business value that they seek.
It is an open architecture, which means that it manages data no matter where it is, in the cloud, on premises, in an SAP system like HANA or in a non-SAP solution like Hadoop or cloud object storage.
Control hybrid landscapes, connections:

Pipelining with Connectivity, Integration & Machine Learning operators along with the flexibility to write your custom Python and R.

Example use case:
In simple terms, Raw data + Enterprise data = Intelligent Insights & Decision Making

Example pipeline built to modernize and derive meaningful insights from raw data(coming from smart devices), combined with enterprise data and further the data is fed into a Continuous Machine Learning cluster model to identify running groups based on various patterns of running behavior also further gives us information on application usage statistics which then can be used to introduce new features into those smart devices.

SAP Data Hub – machine learning (ML) and predictive analytics use case
SAP Data Hub Capabilities:
- Apply machine learning and predictive algorithms to any data set
- Operationalize ML processes rather than serializing individual algorithms manually
- Insert ML and predictive processing to any scenarios within use cases like Big Data warehousing, IoT, and enterprise information management
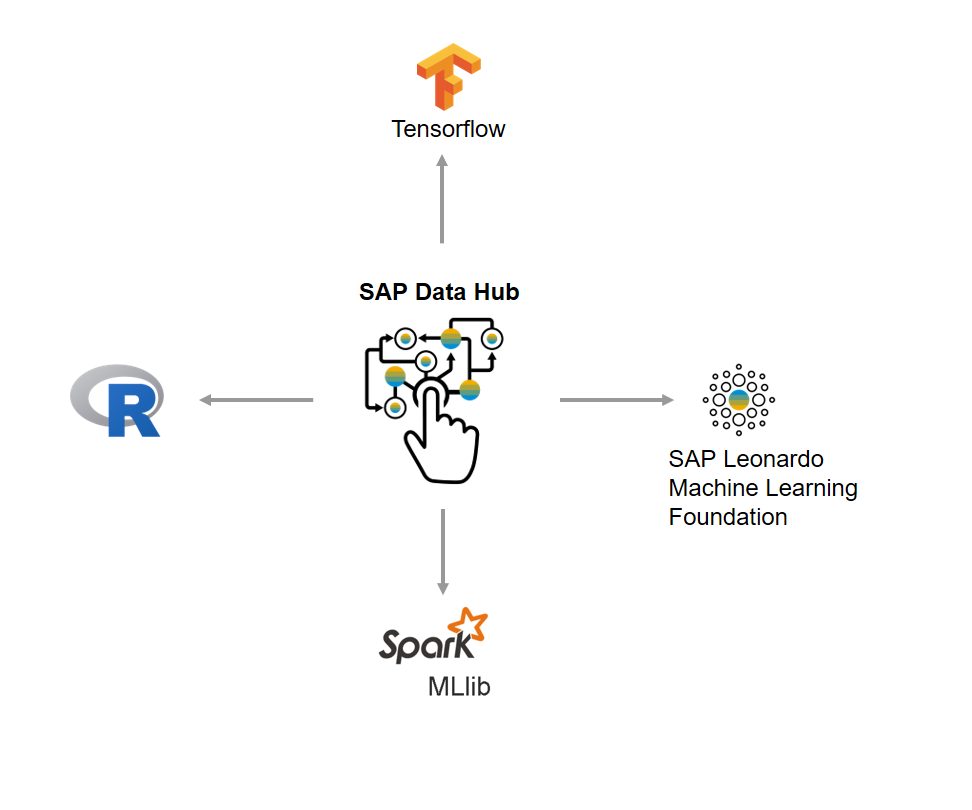
Examples:
Insurance industry risk profiling, Credit analysis and automated scoring models and Machine failure prediction leading to automated preventative maintenance.
Overall SAP Data Hub is winning hearts and gaining confidence. I will try to cover more industry use cases in my next articles. For more updates stay tuned.
SAP Data Hub : https://www.sap.com/india/products/data-hub.html
- SAP Managed Tags:
- SAP Data Intelligence
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Extend Your Crystal Reports Solutions in the DHTML Viewer With a Free Function Library in Technology Blogs by Members
- I created a table function, but in amdp I am not able to create table using sqlscript to append data in Technology Q&A
- OS compatibility in Technology Q&A
- I have a date column and I want to derive Week range in Technology Q&A
- ABAP2XLSX problem downloading file in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |