
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Training and Testing perspective on SAP Leonardo M...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member36
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-19-2018
12:00 PM
Introduction
In case you get engaged with a machine learning algorithm either directly or indirectly by utilizing some APIs, Services or Applications from SAP Leonardo Machine Learning Foundation you need to understand some basic strategies to successfully perform a training or testing of the algorithm or learned model.
This blog post does not provide a full foundation lecture for machine learning. But it should provide you the basic terminology and guidelines required to understand the common strategies to train and test your Application, Service or API.
We will use the Linear Regression algorithm to walk through the relevant terms and notations. Linear regression can be used to learn a function to predict some value for a given set of features.
All machine learning algorithms are trying to optimize/minimize a cost function J to find the best model for the given problem. The cost function for linear regression is
 .
.With m given training examples or data pairs (x, y) where x can be either a single feature or a set of n features. And y = f(x) is the function which the algorithm should learn.
The learned hypothesis h is noted as

in case of a single feature or

in case of n features.
In order to minimize the cost function gradient descent is used to optimize the model parameters Θ.

The learning rate noted as α belongs to the class of hyperparameters. To ensure that the algorithm does converge for a given constant learning rate, the cost function needs to be extended by a regularization term.

The regularization parameter λ is also a hyperparameter.
Now, we should be familiar with the required terminology for the next paragraphs.
Machine Learning Methodology
The input for any machine learning algorithm is data. The more data the better. Training and testing of the algorithm follows a simple phased approach.

Image: Phased approach to train and test your algorithm/model
First you train the algorithm and then you validate it. These two steps are usually executed a few times in a sequence to improve the model’s accuracy. Afterwards you test the model and in case its accuracy is above a certain acceptance level you deploy it.
The data which you use for training, validation and testing should come from the same distribution. You have to split your data into two parts. The first and bigger part you will use for training and validation. The smaller part you will use for testing. There is no best split valid for all learning and data domains. Usually you will use 80% of your data for training and validation and 20% for testing. But in case you have millions of data records a split like 90:10 or even 95:5 is also applicable.

Image: Split of data set
The data set which you want to use for training and validation you will have to split once more into two parts. And again, there is no best split relation valid for all domains. You can use splits like 80:20 or 90:10, just assuring that the majority is used for training.
In the training phase the model parameters are optimized. The validation data set you use to optimize the hyperparameters. You can iterate on those two steps by using e.g. randomly different data splits. This is also called cross-validation.
The most common cross-validation technique is called K-Fold where you split the training and validation data into K subsets of the same size. You run K iterations using K-1 of the subsets as training data and 1 subset as validation data. In each iteration you use a different one of these subsets for validation.
Once these two phases are finished you apply the model to your test data set. This must be data that the algorithm/model did not see before. The accuracy of the model on this test data set should be like the accuracy on any new data on which it will be applied. – Of course, only if the distribution of the data used for training, validation and testing is like the distribution of the data on which the algorithm/model is applied on.
Model Accuracy
Before you deploy your model, you want to know how well it is performing. Remember that your model has learned a hypothesis which should be as close as possible to the real function which determines the value on a set of given features which are characterizing the object on which you want to perform either a prediction or classification operation.
Therefore, you do calculate the error of your model on the training data set as well as on the validation data set. Doing this you may obtain the following results.
- Your model has a very low error on the training data set but a high error on the validation data set.
- Your model has a high error on the training data set and a high error on the validation data set.
- Your model has a low error on the training data set and a low error on the validation data set.

Image: Model in case 1.

Image: Model in case 2.

Image: Model in case 3.

Image: Legend for above images
In the first case 1. the model is over fitting. It has a low robustness. In the second case 2. the model is underfitting and has a high robustness. In both cases you have a model which is not performing well on new data.
In the third case 3. the model is robust, and this is a good model which can proceed to the test phase.
In the literature you will find the terms bias and variance to classify models. A model with a high bias is not complex enough for the given problem and tends to underfit (case 2.). A model with a high variance is overfitting the (training) data (case 1.).

Image: Bias and Variance
In case your model has a high bias, you can apply the following strategies to improve its accuracy:
- Get additional features
- Add polynomial features
- Decrease the regularization parameter
In case your model has a high variance, you can apply the following strategies to improve its accuracy:
- Get more training data
- Reduce the number of features
- Increase the regularization parameter
The (solution) universe is a saddle
You may remember from the math class that if you are trying to optimize a cost function you are in danger to end up in some local optima. Sometimes far away from the global optima which you are seeking for.

Image: Classical view on local optima
Now, recent studies are showing that the more parameters (or features as there is one model parameter per feature) are used in a model the more does the solution space looks like a saddle. In such a space you cannot fall into a local optimum. The only bad thing that can happen is that you arrive in a plateau and further progress is taking long time. The centers of such plateaus are also called saddle points and there is some paper with the hypothesis that deep neural networks converge at (degenerated) saddle points [1].

Image: Saddle of solution space
Retraining of customizable SAP Leonardo Machine Learning services
SAP Machine Learning Foundation provides a set of pretrained services for developers. These services are grouped based on the nature of the input data. Which can be images, speech, text or tabular/time series data. Currently these services are customizable:
- Image Classification
- Image Feature Extraction
- Image Object Detection
- Text Classification
- Text Feature Extraction
- Similarity Scoring
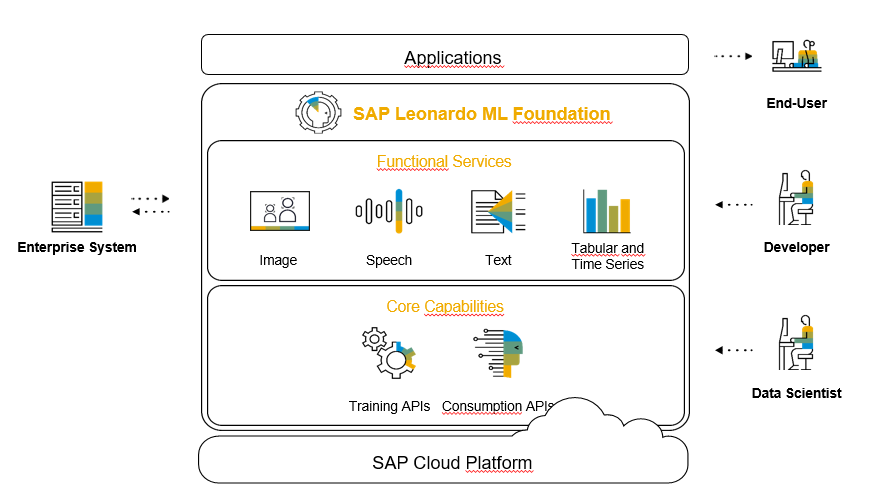
Image: SAP Leonardo Machine Learning Foundation
Customizable services can be retrained to perform best on customer data. These are the steps which need to be executed:
- Upload the training data
- Perform the retraining process
- Deploy the retrained model to use it for inference
- Use it for inference
Before you upload the training data you need to split it into training, validation and test sets like we have seen above. Once you call the APIs to perform the retraining you will also note that they contain some hyperparameters like the learning rate. These hyperparameters you can optimize by applying cross-validation and using one of the following techniques:
- Grid Search
- Random Search
- Bayesian Optimization
If the accuracy of the retrained model is satisfying you can finally deploy and use it in your application.
[1]: https://arxiv.org/pdf/1706.02052.pdf
- SAP Managed Tags:
- Machine Learning,
- SOLMAN Test Suite
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 5 in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- SAP Successfactors Implementation and Maintenance in Projects in 2024 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 36 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |