
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Hub Orchestrierung von SAP Data Services
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-17-2018
11:55 AM
SAP Data Hub ist ein Tool womit z.B. externe Prozesse, Tools und andere Systeme sehr gut orchestriert werden können. Ein Use Case ist es bsp. das SAP Data Services (ein mächtiges ETL Werkzeug) anzubinden und ein bereits bestehenden Prozess (in Data Services nennt man das "Job") orchestrieren kann. In diesem Blog widme ich mich diesem Szenario und starte einen ganz einfachen Data Services Job mit Hilfe von Data Hub. Im reellen Leben würde man natürlich noch deutlich mehr machen und Data Hub nicht nur nutzen um einen Data Services Job zu triggern, aber hier soll es primär nur um die Machbarkeit gehen bzw. um zu zeigen, wie die Anbindung funktioniert bzw. aussieht.
Als Basis verwende ich SAP Data Hub in der Version 2.3 und SAP Data Services in der Version 4.2.
In meinem Fall habe ich eine CAL Landschaft verwendet. Als Kunde muss natürlich sichergestellt werden, dass Data Hub auf Data Services zugreifen kann (über das Netzwerk). Über einen Ping und Portscanner kann das zuerst überprüft werden um sicher zu gehen, dass diese Kommunikation auch funktionieren wird.
Data Services:
In Data Services habe ich einen sehr einfachen Prozess erstellt, der eine csv Datei mit Adressdaten ausliest und diese 1:1 in eine Datenbanktabelle schreibt. Data Hub soll diesen Job starten.
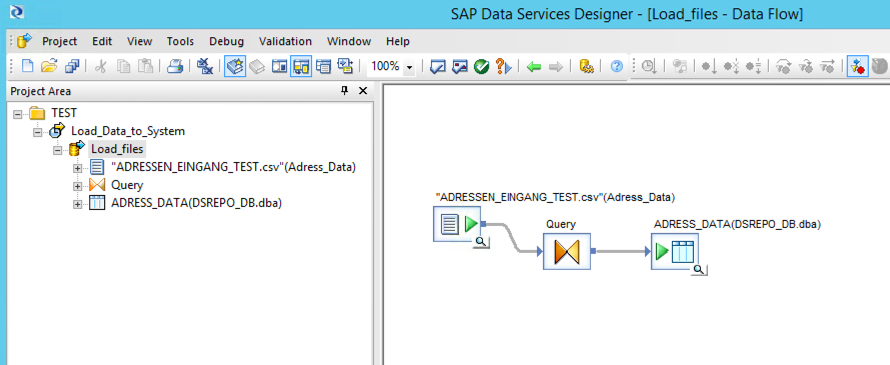
Falls der ein oder andere mehr wissen möchte über den erstellten Prozess, hier die Screenshots der Quelle, des Query und des Ziels (nachdem der Job schon gelaufen ist...):
Die Quelldatei:

Das Query dazwischen:
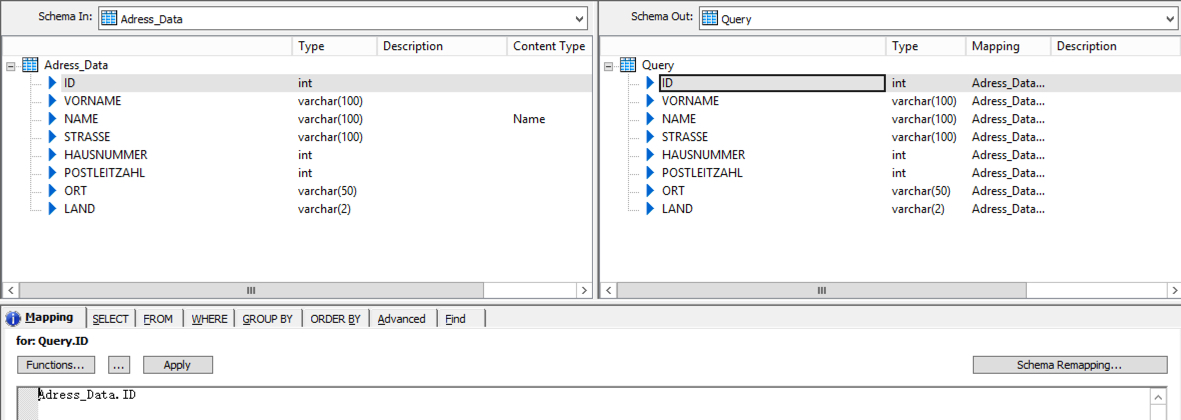
und die beschriebene DB (Template Tabelle erstellt in Data Services):

SAP Data Hub:
So nun zurück zur Integration:
Jeder Batchprozess in Data Services kann, via Data Hub, angetriggert werden. Technisch gesehen, ist das ein Webservice Aufruf.
Um das zu realisieren, müssen wir zuerst in Data Hub eine Verbindung zum System Data Services herstellen. Sobald diese Verbindung hergestellt ist, kann man die Batchprozesse sehen, die dieser User in Data Services nutzen/starten kann.
Zuerst erstellen wir also die Verbindung in Data Hub. Dazu gehen wir in das "Connection Management":

und klicken hier auf "create":

Anschließend erscheint ein leeres Feld:

Hier müssen wir nun die Verbindungsparameter zu Data Services eintragen:

In meinem Beispiel habe ich den Namen "Data Services" gewählt, als Connection Typ "DATASERVICES" selektiert und anschließend den Hostname / IP, Port, CMS Host, CMS Port, Username und Passwort um auf Data Services Prozesse zuzugreifen, eingegeben. Das Passwort wird nicht dargestellt um anderen Usern keine Möglichkeit zu geben darauf zuzugreifen.
(Wer sich nicht sicher ist zwecks Hostname, kann versuchen sich mit dem Data Services Client anzumelden, dann steht bei der Anmeldung an Data Services (technisch an der CMC) sowohl der Hostname wie auch der Port. Alternativ den Link zur CMC.)
Anschließend kann man in der Übersicht der verbundenen Systeme den neuen Eintrag sehen:

Die Verbindung kann man nun testen, in dem man bei der Verbindung (in diesem Fall DATASERVICES) rechts auf die 3 Punkte klickt und "Check Status" anklickt:

Dann sollte folgendes angezeigt werden:

Wenn man einen Fehler hat, erhält man wahrscheinlich folgenden Screenshot angezeigt:

Wenn alles ok ist kann man mit dem Designen in Data Hub weitermachen:
In Data Hub habe ich also einen "Graph" designed (durch Drag&Drop), um den erstellten Data Services Job anzutriggern. Das sieht dann folgendermaßen aus:

Im Data Services Operator kann man nun selektieren, welcher Job angetriggert werden soll:
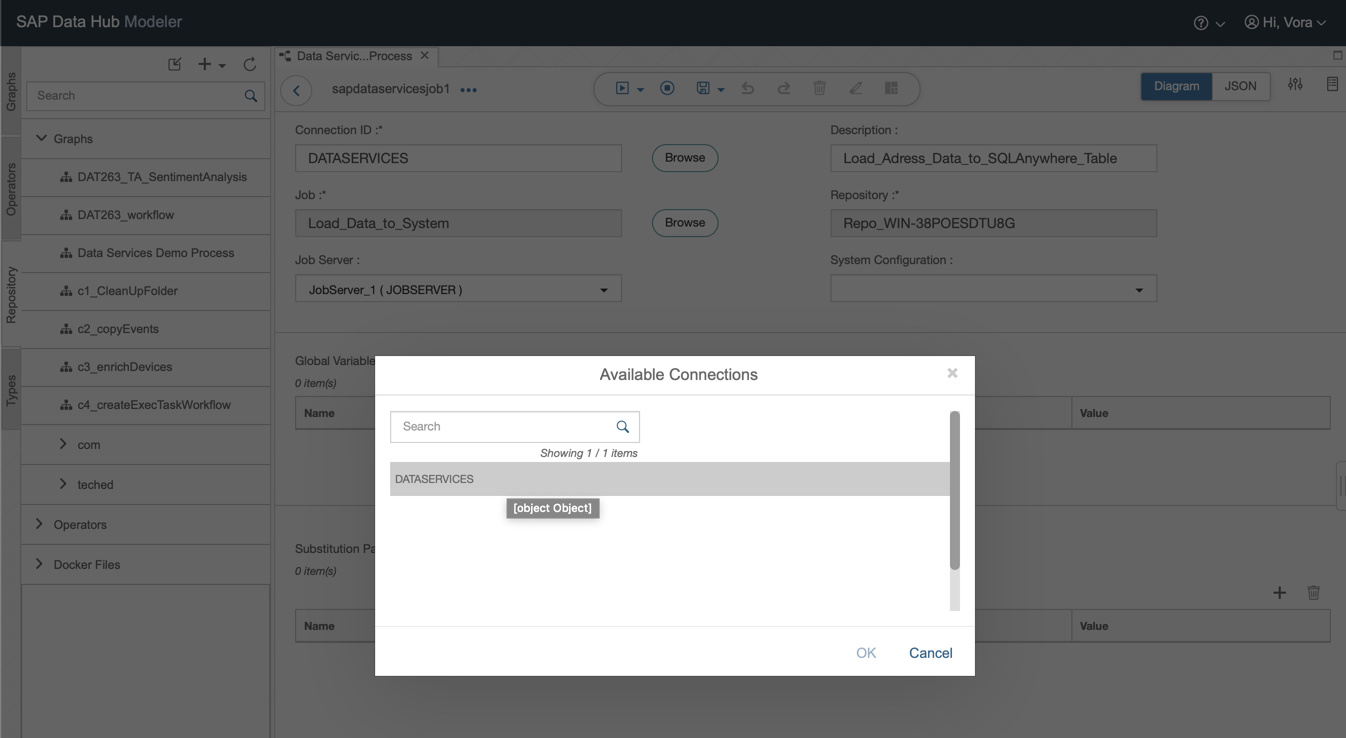
Zuerst muss man die Verbindung selektieren (es kann ja gut sein, dass verschiedene Data Services Systeme angeschlossen sind, bsp. Dev, Qual und Prod). Anschließend selektiert man den Job, den man in dem aktuellen Operator orchestrieren möchte (zuerst das Repository in dem der Job gespeichert ist und anschließend den Job selbst):

Nun muss nur noch der Jobserver selektiert werden, denn es ist häufig so, dass man mehrere Jobserver nutzt, um die Last zu verteilen. Sollte man nur einen verwenden, wird nur dieser angezeigt:

Wenn man den Job selektiert hat, sieht das dann so aus:

Wenn man im Data Services Job "Variablen" oder "Substitution Parameter" verwendet, werden diese hier angezeigt. Werden Systemkonfigurationen verwendet, werden diese als "System Configuration" zur Selektion zur Verfügung gestellt.
Der optionale Terminal Operator ist nur als Anzeige, ob der Data Services Job gestartet wurde. Wenn das der Fall ist, sieht das folgendermaßen aus:
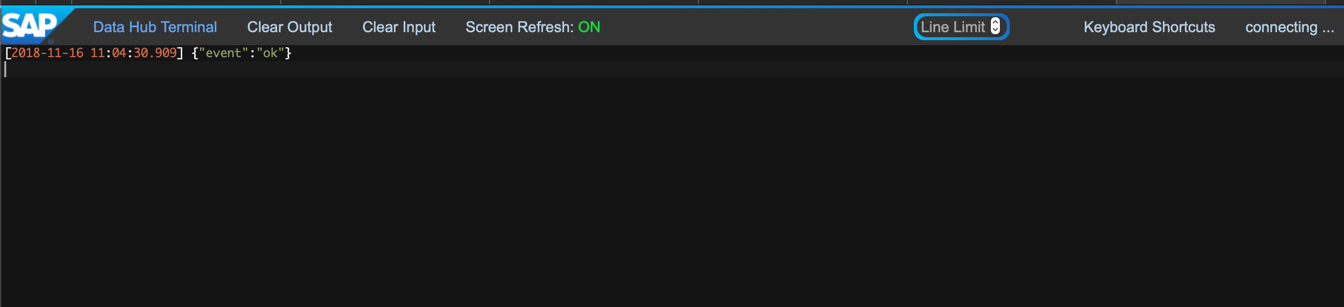
Wenn man sich nun in der Data Services Management Console anmeldet, sieht man den Batchjob als gestartet und beendet (erkennbar an dem grünen Häkchen für erfolgreich und das eine Endzeit angegeben ist):

Bei Bedarf kann man natürlich noch in das Errorlog schauen um den Grund für einen Abbruch zu identifizieren. In meinem Fall sind die Daten ohne Probleme in die Datenbank geflossen.
In Data Hub kann ich mir nun ebenfalls ansehen, das der Data Services Job erfolgreich angetriggert und beendet wurde:

Anhand der grünen Häkchen sieht man, das alles erfolgreich durchgeführt wurde.
Damit ist die Orchestrierung bereits beendet und die Integration erfolgreich durchgeführt.
Um diese Integration von Data Hub und Data Services nachzustellen, kann man genau die gleichen Steps durchführen (natürlich angepasst um die entsprechenden Hostnames, bzw. Verlinkungen). Damit kann die Integration durchgeführt werden zwischen beiden Tools.
Viel Spaß dabei!
Als Basis verwende ich SAP Data Hub in der Version 2.3 und SAP Data Services in der Version 4.2.
In meinem Fall habe ich eine CAL Landschaft verwendet. Als Kunde muss natürlich sichergestellt werden, dass Data Hub auf Data Services zugreifen kann (über das Netzwerk). Über einen Ping und Portscanner kann das zuerst überprüft werden um sicher zu gehen, dass diese Kommunikation auch funktionieren wird.
Data Services:
In Data Services habe ich einen sehr einfachen Prozess erstellt, der eine csv Datei mit Adressdaten ausliest und diese 1:1 in eine Datenbanktabelle schreibt. Data Hub soll diesen Job starten.
Falls der ein oder andere mehr wissen möchte über den erstellten Prozess, hier die Screenshots der Quelle, des Query und des Ziels (nachdem der Job schon gelaufen ist...):
Die Quelldatei:
Das Query dazwischen:
und die beschriebene DB (Template Tabelle erstellt in Data Services):
SAP Data Hub:
So nun zurück zur Integration:
Jeder Batchprozess in Data Services kann, via Data Hub, angetriggert werden. Technisch gesehen, ist das ein Webservice Aufruf.
Um das zu realisieren, müssen wir zuerst in Data Hub eine Verbindung zum System Data Services herstellen. Sobald diese Verbindung hergestellt ist, kann man die Batchprozesse sehen, die dieser User in Data Services nutzen/starten kann.
Zuerst erstellen wir also die Verbindung in Data Hub. Dazu gehen wir in das "Connection Management":
und klicken hier auf "create":
Anschließend erscheint ein leeres Feld:
Hier müssen wir nun die Verbindungsparameter zu Data Services eintragen:
In meinem Beispiel habe ich den Namen "Data Services" gewählt, als Connection Typ "DATASERVICES" selektiert und anschließend den Hostname / IP, Port, CMS Host, CMS Port, Username und Passwort um auf Data Services Prozesse zuzugreifen, eingegeben. Das Passwort wird nicht dargestellt um anderen Usern keine Möglichkeit zu geben darauf zuzugreifen.
(Wer sich nicht sicher ist zwecks Hostname, kann versuchen sich mit dem Data Services Client anzumelden, dann steht bei der Anmeldung an Data Services (technisch an der CMC) sowohl der Hostname wie auch der Port. Alternativ den Link zur CMC.)
Anschließend kann man in der Übersicht der verbundenen Systeme den neuen Eintrag sehen:
Die Verbindung kann man nun testen, in dem man bei der Verbindung (in diesem Fall DATASERVICES) rechts auf die 3 Punkte klickt und "Check Status" anklickt:
Dann sollte folgendes angezeigt werden:
Wenn man einen Fehler hat, erhält man wahrscheinlich folgenden Screenshot angezeigt:
Wenn alles ok ist kann man mit dem Designen in Data Hub weitermachen:
In Data Hub habe ich also einen "Graph" designed (durch Drag&Drop), um den erstellten Data Services Job anzutriggern. Das sieht dann folgendermaßen aus:
Im Data Services Operator kann man nun selektieren, welcher Job angetriggert werden soll:
Zuerst muss man die Verbindung selektieren (es kann ja gut sein, dass verschiedene Data Services Systeme angeschlossen sind, bsp. Dev, Qual und Prod). Anschließend selektiert man den Job, den man in dem aktuellen Operator orchestrieren möchte (zuerst das Repository in dem der Job gespeichert ist und anschließend den Job selbst):
Nun muss nur noch der Jobserver selektiert werden, denn es ist häufig so, dass man mehrere Jobserver nutzt, um die Last zu verteilen. Sollte man nur einen verwenden, wird nur dieser angezeigt:
Wenn man den Job selektiert hat, sieht das dann so aus:
Wenn man im Data Services Job "Variablen" oder "Substitution Parameter" verwendet, werden diese hier angezeigt. Werden Systemkonfigurationen verwendet, werden diese als "System Configuration" zur Selektion zur Verfügung gestellt.
Der optionale Terminal Operator ist nur als Anzeige, ob der Data Services Job gestartet wurde. Wenn das der Fall ist, sieht das folgendermaßen aus:
Wenn man sich nun in der Data Services Management Console anmeldet, sieht man den Batchjob als gestartet und beendet (erkennbar an dem grünen Häkchen für erfolgreich und das eine Endzeit angegeben ist):
Bei Bedarf kann man natürlich noch in das Errorlog schauen um den Grund für einen Abbruch zu identifizieren. In meinem Fall sind die Daten ohne Probleme in die Datenbank geflossen.
In Data Hub kann ich mir nun ebenfalls ansehen, das der Data Services Job erfolgreich angetriggert und beendet wurde:
Anhand der grünen Häkchen sieht man, das alles erfolgreich durchgeführt wurde.
Damit ist die Orchestrierung bereits beendet und die Integration erfolgreich durchgeführt.
Um diese Integration von Data Hub und Data Services nachzustellen, kann man genau die gleichen Steps durchführen (natürlich angepasst um die entsprechenden Hostnames, bzw. Verlinkungen). Damit kann die Integration durchgeführt werden zwischen beiden Tools.
Viel Spaß dabei!
- SAP Managed Tags:
- SAP Data Intelligence,
- SAP Data Services,
- Training
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
470 -
Workload Fluctuations
1
Related Content
- How to Install SAP Cloud Connector on a Mac M2 chipset in Technology Q&A
- How to Install SAP Cloud Connector on a Mac M2 Processor in Technology Q&A
- Import Data Connection to SAP S/4HANA in SAP Analytics Cloud : Technical Configuration in Technology Blogs by Members
- How to consume one capm service in another capm service? in Technology Q&A
- Automated check for SAP HANA Cloud availability with SAP Automation Pilot in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 13 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |