
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data Lifecycle Manager (DLM) Database Artifacts an...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-05-2018
6:51 PM
Data Lifecycle Manager Database Artifacts and Data Relocation Use Cases
My recent post on the SAP Data Lifecycle Manager (DLM) provides an overview on how the tool eliminates the need for manual data management by automating the execution of a DLM profile to support better query performance and lower TCO for organizations using large scale SAP HANA deployments.
Today’s post goes into more depth on the database artifacts that can be generated within a DLM profile and provides more detail on the data relocation direction use cases for moving hot data to cold data storage, cold to hot data storage or bi-directional movement of data between hot and cold data stores. Let’s dive right in:
Data Movement Rule
The DLM Data Movement Rule specifies which data should be moved from the source table to the target table/structure. DLM XS-Classic offers pure SQL Logic including a function library to specify the Data Movement Rules, while DLM XS-Advanced offers pure SQL Logic with integration for function library support underway. Integrating functions from the library to the Data Movement Rule supports the unattended/scheduled execution of the DLM Profile. A rolling window / fixed dataset can be kept in the source table(s) without applying constant changes to the DLM Data Movement Rule. If you apply this example of rolling window logic: “DATEFROM” < ADD_DAYS (CURRENT_DATE, -1095) AND “STATUS” = ‘C’, all “closed/completed” records older than ~3 years (1095 days) will be moved to the defined data storage destination.
The DLM Movement Rule also supports a clash strategy—which specifies how DLM handles unique key constraint violations—to control record update scenarios. The rule allows for either the support of record UPDATE behavior (for an application that supports both record INSERT and record UPDATE behavior) or for the prevention of record UPDATE behavior (for an application that supports record INSERT-only behavior).
The bi-directional movement of data is also supported while ensuring that data is only visible within a single storage destination, even while the data is in movement. For DLM to move data between a (column-store) source table and target table, the table structures must be identical.
DLM Modeled Persistence Object
The DLM Modeled Persistence Object (MPO) supports scenarios where the consistent movement of data from a set of connected source tables into a set of target tables or structures is required. The DLM Data Movement Rule is applied to the complete set of source tables where records can be identified based on the granularity and content of the connected tables. For example, “Header” – “Item” connected tables. DLM XS-Classic supports MPO Table-Hierarchy, based on a HANA Calculation View logic to connect tables, and table group, based on identical column names to connect tables. DLM XS-Advanced supports the table group concept.
DLM Generated Views
DLM Generated Views provide access to the complete and distributed data set between DLM source-table and DLM Storage Destination. If an application requires continued access to both hot and cold data, leveraging DLM Generated Views is recommended. To start, the existing application replaces the existing source table access with one of the DLM Generated Views. The primary relocation should occur within a HANA Calculation View, Database View or supported Front Ends. Other options are in development to help redirect access from the source table to DLM Generated Views.
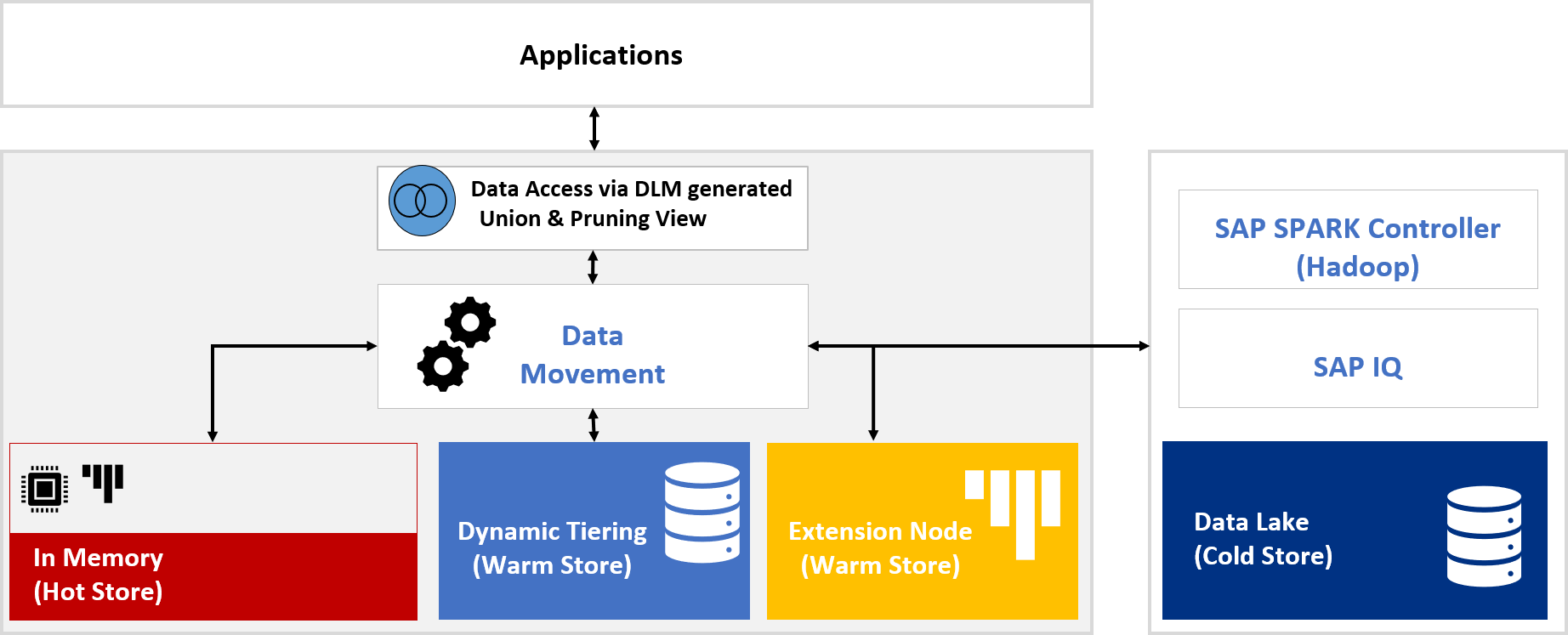
Figure 1: DLM Generated Views
Let’s look at both DLM Generated Views options by using the following scenario example:
Let’s look at a query result set using DLM Database Union-All View (GVIEW):
The query is applied to the source and the target table/structure for access to data located in both the cold and hot storage locations. A UNION-ALL View requires no further logic to be applied to execute the query and for INSERT-only applications without UPDATE records, to ensure that records with an identical primary key are located in a single storage destination. This prevents incorrect query results—no duplicate records or mixing of initial and UPDATE record content can occur. The DLM Data Movement Rule with clash strategy “overwrite” must be enabled and no pruning capabilities are available. The query and WHERE condition filters are applied to both the source and target table/structure.
Now let’s map the Database UNION-ALL View to the original scenario:
How do we resolve for the error? The frequency of the DLM Data Movement Rule execution, with clash strategy “overwrite” enabled can be increased to move records with an identical primary key to a single data storage destination. Or, if no control exists on the source table record UPDATE frequency—during real-time data replication for example—the DLM Pruning View [PVIEW] can be leveraged.
Let’s take a closer look at the DLM Pruning View (PVIEW):
PVIEW is a HANA Calculation Scenario View of the data. A query is applied to both source and target table/structure and additional logic is used to interpret the data from the two tables as a single table that includes a primary key. Only the most recent record/values are returned. The primary use case for a PVIEW is for INSERT and UPDATE application behavior, as the PVIEW returns the most recent values or records. It’s also used for the distribution of INITIAL and UPDATE records between the source and target table/structure. It can be used for accessing data sets from cold and/or hot storage locations.
As with UNION-ALL Views, the DLM Data Movement Rule must enable clash strategy “overwrite”. Data pruning capabilities are also automatically enabled. The query accessing the PVIEW is validated against the existing DLM Data Movement Rule—once a column from the query is identified within a valid and already executed DLM Data Movement Rule, the PVIEW automatically selects the data from the target table/structure (as it’s clear that data matching the DLM Data Movement Rule has been moved here) and a second step is automatically executed to validate if there’s a more recent record (UPDATE record) available in the source table, following the same primary key. Only the most recent (single) record values are returned. Pruning only works once the query is not selecting any columns / data which are part of a valid and already executed DLM Data Movement Rule. In this case, the data is only available in the source table.
Now let’s map this PVIEW option to our original scenario:
This is currently a single-threaded process. Parallelizing the process for selecting the most recent record from the source table is under development. PVIEW relaxes the frequency of the DLM Data Movement Rule execution to move records with an identical primary key to a single data storage destination.
More Information on Data Lifecycle Manager
That covers the in-depth look at the key DLM database artifacts. If you’re looking for even more information on the Data Lifecycle Manager, check out the blogs and DLM help pages listed below. And please feel free to send any questions my way.
SAP HANA Data Warehousing Foundation Expert Page
SAP HANA Data Warehousing Foundation Blog-Page
SAP HANA Data Warehousing Foundation Help-Page
SAP HANA Data Warehousing Foundation XS-Classic Guide
SAP HANA Data Warehousing Foundation XS-Advanced Guide
My recent post on the SAP Data Lifecycle Manager (DLM) provides an overview on how the tool eliminates the need for manual data management by automating the execution of a DLM profile to support better query performance and lower TCO for organizations using large scale SAP HANA deployments.
Today’s post goes into more depth on the database artifacts that can be generated within a DLM profile and provides more detail on the data relocation direction use cases for moving hot data to cold data storage, cold to hot data storage or bi-directional movement of data between hot and cold data stores. Let’s dive right in:
Data Movement Rule
The DLM Data Movement Rule specifies which data should be moved from the source table to the target table/structure. DLM XS-Classic offers pure SQL Logic including a function library to specify the Data Movement Rules, while DLM XS-Advanced offers pure SQL Logic with integration for function library support underway. Integrating functions from the library to the Data Movement Rule supports the unattended/scheduled execution of the DLM Profile. A rolling window / fixed dataset can be kept in the source table(s) without applying constant changes to the DLM Data Movement Rule. If you apply this example of rolling window logic: “DATEFROM” < ADD_DAYS (CURRENT_DATE, -1095) AND “STATUS” = ‘C’, all “closed/completed” records older than ~3 years (1095 days) will be moved to the defined data storage destination.
The DLM Movement Rule also supports a clash strategy—which specifies how DLM handles unique key constraint violations—to control record update scenarios. The rule allows for either the support of record UPDATE behavior (for an application that supports both record INSERT and record UPDATE behavior) or for the prevention of record UPDATE behavior (for an application that supports record INSERT-only behavior).
The bi-directional movement of data is also supported while ensuring that data is only visible within a single storage destination, even while the data is in movement. For DLM to move data between a (column-store) source table and target table, the table structures must be identical.
DLM Modeled Persistence Object
The DLM Modeled Persistence Object (MPO) supports scenarios where the consistent movement of data from a set of connected source tables into a set of target tables or structures is required. The DLM Data Movement Rule is applied to the complete set of source tables where records can be identified based on the granularity and content of the connected tables. For example, “Header” – “Item” connected tables. DLM XS-Classic supports MPO Table-Hierarchy, based on a HANA Calculation View logic to connect tables, and table group, based on identical column names to connect tables. DLM XS-Advanced supports the table group concept.
DLM Generated Views
DLM Generated Views provide access to the complete and distributed data set between DLM source-table and DLM Storage Destination. If an application requires continued access to both hot and cold data, leveraging DLM Generated Views is recommended. To start, the existing application replaces the existing source table access with one of the DLM Generated Views. The primary relocation should occur within a HANA Calculation View, Database View or supported Front Ends. Other options are in development to help redirect access from the source table to DLM Generated Views.
Figure 1: DLM Generated Views
Let’s look at both DLM Generated Views options by using the following scenario example:
- An application triggers an initial record creation and the initial record is added to the DLM source table.
- With the clash strategy “overwrite” enabled as part of the DLM Data Movement Rule, the initial record is identified to be moved to the cold storage target table/structure.
- The DLM Data Movement Rule is executed.
- Result: A single (initial) record is now available in the target table/structure.
- The (initial) record only exists in the cold storage target table/structure.
- The application triggers an UPDATE record creation, represented as an INSERT/UPSERT action to the source table as the initial record has already been transferred to the target table/structure. The initial record values for UPDATE are selected from the application by using one of the DLM Generated Views to access the record. In this case, the record is selected from the target table/structure.
- Result: 2 records with an identical primary key are available and distributed across the source table and the target table/structure.
- An UPDATE/INSERT record is available in the hot source table and the (initial) record exists in the cold target table/structure.
Let’s look at a query result set using DLM Database Union-All View (GVIEW):
The query is applied to the source and the target table/structure for access to data located in both the cold and hot storage locations. A UNION-ALL View requires no further logic to be applied to execute the query and for INSERT-only applications without UPDATE records, to ensure that records with an identical primary key are located in a single storage destination. This prevents incorrect query results—no duplicate records or mixing of initial and UPDATE record content can occur. The DLM Data Movement Rule with clash strategy “overwrite” must be enabled and no pruning capabilities are available. The query and WHERE condition filters are applied to both the source and target table/structure.
Now let’s map the Database UNION-ALL View to the original scenario:
- The query result set contains two records since an UPDATE/INSERT record is available in the source table and the (initial) record exists in the target table/structure.
- The query result will be incorrect in most cases, as only most recent (UPDATE) record is expected by the application.
How do we resolve for the error? The frequency of the DLM Data Movement Rule execution, with clash strategy “overwrite” enabled can be increased to move records with an identical primary key to a single data storage destination. Or, if no control exists on the source table record UPDATE frequency—during real-time data replication for example—the DLM Pruning View [PVIEW] can be leveraged.
Let’s take a closer look at the DLM Pruning View (PVIEW):
PVIEW is a HANA Calculation Scenario View of the data. A query is applied to both source and target table/structure and additional logic is used to interpret the data from the two tables as a single table that includes a primary key. Only the most recent record/values are returned. The primary use case for a PVIEW is for INSERT and UPDATE application behavior, as the PVIEW returns the most recent values or records. It’s also used for the distribution of INITIAL and UPDATE records between the source and target table/structure. It can be used for accessing data sets from cold and/or hot storage locations.
As with UNION-ALL Views, the DLM Data Movement Rule must enable clash strategy “overwrite”. Data pruning capabilities are also automatically enabled. The query accessing the PVIEW is validated against the existing DLM Data Movement Rule—once a column from the query is identified within a valid and already executed DLM Data Movement Rule, the PVIEW automatically selects the data from the target table/structure (as it’s clear that data matching the DLM Data Movement Rule has been moved here) and a second step is automatically executed to validate if there’s a more recent record (UPDATE record) available in the source table, following the same primary key. Only the most recent (single) record values are returned. Pruning only works once the query is not selecting any columns / data which are part of a valid and already executed DLM Data Movement Rule. In this case, the data is only available in the source table.
Now let’s map this PVIEW option to our original scenario:
- The query result set contains a single / most recent record since the PVIEW represents the source and target table/structure as a single table following the same primary key no matter how the records (INITIAL and UPDATE) are distributed across the source- and target table/structure.
- The query result is always correct, as the most recent (UPDATE) record is expected by the application.
This is currently a single-threaded process. Parallelizing the process for selecting the most recent record from the source table is under development. PVIEW relaxes the frequency of the DLM Data Movement Rule execution to move records with an identical primary key to a single data storage destination.
More Information on Data Lifecycle Manager
That covers the in-depth look at the key DLM database artifacts. If you’re looking for even more information on the Data Lifecycle Manager, check out the blogs and DLM help pages listed below. And please feel free to send any questions my way.
SAP HANA Data Warehousing Foundation Expert Page
SAP HANA Data Warehousing Foundation Blog-Page
SAP HANA Data Warehousing Foundation Help-Page
SAP HANA Data Warehousing Foundation XS-Classic Guide
SAP HANA Data Warehousing Foundation XS-Advanced Guide
- SAP Managed Tags:
- SAP HANA,
- SAP HANA dynamic tiering
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
86 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
270 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
395 -
Workload Fluctuations
1
Related Content
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- Unlocking Full-Stack Potential using SAP build code - Part 1 in Technology Blogs by Members
- What’s New for SAP Integration Suite – February 2024 in Technology Blogs by SAP
- SAP Cloud ALM Implementation and Operations Configuration Webinar Series in Technology Blogs by SAP
- Safeguarding Quality: The Necessity and Strategic Usage of Quality Gates in Projects in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |