
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Smart Data Integration: Increase Initial Load Perf...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-01-2018
1:41 PM
Hello Community,
this Blog Post aim is to assist you in your daily work using Smart Data Integration and the Replication Task.
In some situations i faced performance issue and i want to use this Blog as a central sweat spot for Best Practices and Lessons learned about performance issues surrounding SDI and the initial Load Replication Task.
To show the advantages of the tweaks i use a testing environment to implement them straight ahead and show the results.
To summarize this Blog take a view on the below Table. It gives you a quick view on the implemented tasks and their expected Impact.
Best Performance is achieved by Best Replication Task Design as we can see. Do not leave the other areas out of scope as they are part of the Big Picture but you should stick your broad efforts into the Design of the Replication Task.
As a result of this Workshop we can see that our RT01 Replication Task started with a Run time of about 186.000 ms and ended, after all Tweaks have been applied, at about 67.000 ms. This is an increase of performance in the area of ~ 60 %.
If you had a similar situation and are aware of even more tweaks i would like to know them. Please feel free to add them into the comments.
I am using the following architecture as test Environment:

As you can see this is pretty straight forward. A MS SQL Server 2017 is acting as the source Database having the SAP HANA SDI DP Agent 2.0 installed. Destination Database is a SAP HANA 2.0 Database.
I am using the following Versions of Software Applications.
Source System
Target System
In Scope of this Blog are Performance Tips and Tricks on the following Layer
It will cover Database Indexes and Views, SAP HANA SDI DP Agent Parameters as well as Tips and Tricks in the Replication Task design and SAP HANA Parameter settings.
Everything that is not listed here is out of Scope!
The approach will look as follows:
On source System Level we have the Sale Table from the sample Data. Structure looks as follows:
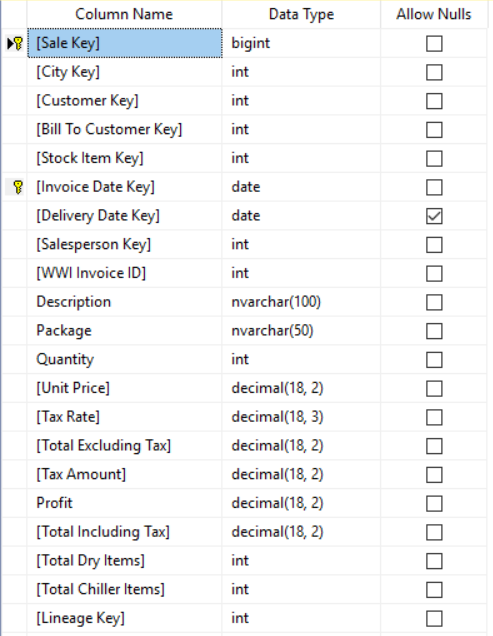
Row count is about 12 Mill. records

On the Target System we have a standard Replication Task configured for Initial Load. No performance tweaks applied so far.
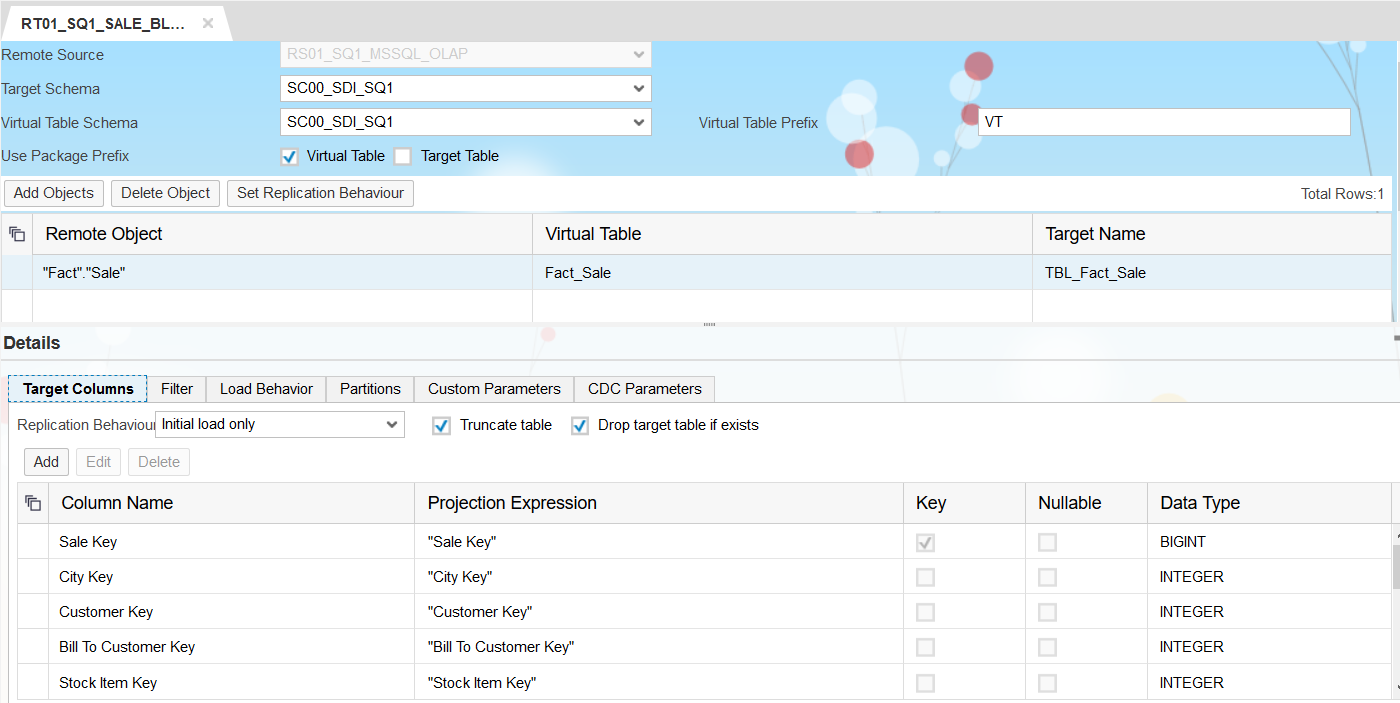
Having the setup running, and no tweaks have been performed so far, the run time for our RT01 Replication Task is at ~ 186.000 ms.

See SAP SDI Best Practices as Guideline.
I want to give you a restricted view on the source Database tweaks as they always differ from your source Database vendor.
Most of the tweaks here were already shipped by the demo Data, but generally spoken you should consider the following Tweaks:
Already shipped with the Demo Content are some Indexes created on the Table.

Especially important is the Index on the Primary Key. The PK should always be a Part of your Replication Task.
Here you have to contact your source System DBA and let them create your Indexes. Depending on the kind of source system the process differs.
Also here, already shipped with the Demo content. We can see the Statistics on the Table.
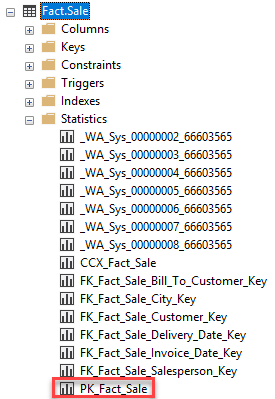
Parallel to your Index, your DBA should create up-to-date Statistics. It is one solution to create Statistics, and performance will increase instant. Over time the advantage will vanish if your statistics are not up-to-date. Therefore make sure that they are updated automatically.

Use a Database View to encapsulate only your Business requirements within the View. Maybe you don`t have to consume the full table but only some columns, maybe you need a JOIN or UNION to another table, you could filter the Data directly in the View and so on.
Filtering could also be done within the Replication Task. But having this kind of logic on the lowest Layer in our overall architecture is the best for your performance.
Databases sent their Query into the Query Optimizer in order to ensure the Best Performance available. As these Query Optimizer are some kind of a black box, we have no insight what happens inside.
You can pass along "Hints" within the View to manually adjust the handling of the Query Optimizer. Also here you need the help of your DBA as this task can get complex and varies from source System kind.
Here i created an example Database View that only takes the columns into account that i actually need for my (artificial) business scenario as well as a Filter. The Views takes 12 out of the 21 columns an retrieves only half of the 12 mill. records.

I now created a simple Replication Task on top of this View and guess what - it was quite fast. Only makes sense as we have fewer columns and fewer rows as from the base "Sale" Table.
The result is at ~ 44.000 ms.

Always consider the impact when you implement a Database View. In our overall Architecture this is another Layer. It includes logic, needs to be maintained and developed. Often development is out of scope within the project team as this has to be done by the DBA.
Remember these organisational challenges.
As already mentioned, in my case the source Database tweaks have already been applied as part of the shipped Demo Content from the WideWorldImportersDW Database. So we wont see much progress here.
If you don`t have these on your source Database and you apply these tweaks, you can expect an performance boost.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 187.000 ms.

Lets have a look into our second Layer - The SDI DP Agent.
A general rule of thumb is to place the DP Agent as close as possible to the source System. Ideally installed on the same Host as the source System. For sure i had more situation where this was not possible due to IT guidelines as situation were it was.
At least the SDI DP Agent should be in the same Sub net and geographically very very close to the source System.
See 2459953
For very large Initial Loads please configure an adequat "-Xmx" Setting in the "dpagent.ini" config File under "<SDI_DP_AGENT_INSTALL_DIR>\dataprovagent".
This Setting really depends on the Size of your Tables that you want to load in an Initial Load szenario. If the Tables contain millions of rows, a setting between 16 - 24 GB is recommended.

I would recommend that you play a little with this Parameter until it fits your purpose.
See 2546216
The general rule of thumb with regards to SAP Parameter`s is: Leave it as it is!
Only when you face an issue and the solution is to change a parameter, change the parameter. Solutions are documented in the official SAP Documentation, SAP Note or by a SAP Support Engineer.
Tweak two is to verify two parameters out of the "dpagentconfig.ini" File under "<SDI_DP_AGENT_INSTALL_DIR>\dataprovagent".
The Parameters "framework.serializerPoolSize" and "framework.responsePoolSize" need to have a lower value as the "-Xmx" Parameter.

See 2362235
When you use Partitions within your Replication Task...and i encourage you to do so...this Parameter comes into account.
Only when you use a large Number of Partitions this Parameter has to be adjusted manually.
We will learn about Partitioning in Replication Tasks later.
Honestly, i didn`t expect a large performance increase after applying these tweaks. Why? I only run this one replication task and all the resources belong to this one.
Setting Xmx values for java based processes comes always into account when we have a heavy parallel processing, which we don`t have while running these tests.
But in a productive Environment with many large tables that you want to load in parallel you will have a positive result out of these tweaks.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 185.000 ms

At the end of the day a slight improvement.
Our final Layer is the Target System. Especially the Replication Task design is crucial here. By having the best Replication Task design we get major performance improvements.
See SDI Documentation
An absolute Must- Have! By using Task Partitioning you cut one large SQL Statement into many small SQL Statements. These will be handled in parallel by the source Database and hence we gain a greater performance.
I would recommend to create the Replication Task Partitions based on the Primary Key. Why? Because in a well fitting Environment we will have an Index and Statistics on our Primary Key. In addition, the PK should always be part of the Replication Task. In that case the PK is our red line through the whole Workflow.
You have a lot of options by using Replication Task Partitioning. I would recommend you check the SDI documentation for the scenario that fits the most.
I usually start with a Range Partition set on the PK and a parallelization of 4.

Whats the correct value for the parallel partitions? No one can tell you! Always keep in mind that those four SQL Statements have to be joined to one at the end of the Workflow. This takes some additional time.
Creating Partitions is like the SDI DP Agent parameters. You have to play a little with the values until you get a satisfied result.
My PK is a BIGINT and the max value is something around 12 Mill. I created four partitions splitting those 12 Mill. records into groups looking like this

"PART_00" Partition fetches all Data until the "Sale Key" 4000000.
"PART_01" Partition fetches all Data from the "Sale Key" 4000001 until 8000000.
And so on...
When i start the Replication Task i can see the process in my DP Task Monitor and also the SQL Statements of the partitions.

Alright. Lets play a little with the partitions and run the RT01 Replication Task a few times.
(*) Remember Note 2362235 when having more than 8 Partitions!
As we can see run time increases at a certain point in Time. We get the best Performance with six Partitions. Having more Partitions the run time increases as we produce more overhead for the merge.
So lets stick to the six Partitions with a run time of ~ 93.000 ms.
See SAP HANA Documentation
Create Data statistic objects that allow the query optimizer to make better decisions for query plans.
And in our case we can even create statistics on Virtual Tables that will help us to improve the performance of our initial Load.
We run the following Statement in our HANA Database:
Here we follow our red line. As column i recommend the usage of your Primary Key as we did on DB Layer with the Index and the Statistics.
REFRESH TYPE should be set to AUTO as in this case HANA decides whats the best refresh type.
ENABLE ON and INITIAL REFRESH are meanwhile the default options.
Having set the statistics on our Virtual Table, the Run time of our RT01 Replication Task is at ~ 81.000 ms.
See 2044468
Partitioning the Target Table brings us the performance gain in a way that the SDI Table Writer can write the Data in parallel into multiple partitions of the Table.
Please be aware that this tweak speeds up the writing processes but can come along with a performance degradation in the reading processes. This is due to the fact that the Query needs to be merged after running over multiple Table partitions. Especially on simple Queries the Table Partitioning can have negative impact.
Therefore i highly recommend that you check the above Note.
In our scenario we will use the Target Table Partitioning being in sync. with our Replication Task Partitions. The recommendation is to have the same amount of Target Table partitions as of Replication Task Partitions and the usage of the PK. If you are running a Scale- Out Scenario it is recommended to split the partitions over all available Nodes.
For the sake of this Blog we will try two types of Partitions. The HASH Partition and the RANGE Partition. The HASH Partition is the most easiest and fastest way to set up partitioning. For the RANGE Partition we need a little more complex setup.
SQL Syntax for setting up the HASH Partition:
SQL Syntax for setting up the RANGE Partition:
Result:
We can see that there is not much difference between both Partition types. In that case i would recommend the usage of the HASH partition as this is the one with the easier setup and it requires less maintenance.
For the sake of this Blog i will use the RANGE Partition which results in a run time of or RT01 Replication Task of ~ 67.000 ms.
This one is quite obvious as in chapter 4.1.3. In the beginning double- check your business requirements. Do you really require all columns from the source Table in your target? Do you really require all rows from the source Table in your target?
Verify these questions with your business department in order to minimize the data transferred over the wire. The less Data, the quicker - Nothing new.
For Demo purpose is added a Filter to our RT01 Replication Task. I`m filtering the Data based on a Date Field. In my case the "Invoice Date Key" Field. I have Demo data from 2012 to 2016. I want to get all the Data from the last three years (2014-2016).
So my Replication Task Filter looks like:

And (again) guess what - quite fast. Meridian run time was at ~ 2800 ms. This is due to the fact that we massively decreased the amount of data that we transfer over the wire. Instead of transferring our 12 mill. records, we transferred ~ 167.000 records.
So i really encourage you to use Replication Task Filter.
For the sake of this Blog i remove the Filter so that we are back on our 12 Mill. records.
Tweaking our Replication Task gave us the best results and most out of the Performance. I was expecting this result.
Replication Task Partitioning, Replication Task Filters and Statistics on our Virtual Table are a Must Have! Think twice of using Target Table Partitioning. It could be a draw bag for your analytical scenarios and processes.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 67.000 ms

Additional Information related to this Topic.
See 2000003 (Point 17)
Timeouts are always an important setting. When you are dealing with long running Replication Tasks i recommend the above SAP Note to you. Especially the "dpserver.ini" Timeouts are relevant for SDI.
Even after applying all these tweaks it is likely possible that your initial load Replication Task runs for hours due to the massive amount of data based on the business requirements.
In any case, check the SDI timeout settings.
See 2363544
I`ll recommend to set the prefetchTimeout Parameter but with a high value. Something about 10800.
this Blog Post aim is to assist you in your daily work using Smart Data Integration and the Replication Task.
In some situations i faced performance issue and i want to use this Blog as a central sweat spot for Best Practices and Lessons learned about performance issues surrounding SDI and the initial Load Replication Task.
To show the advantages of the tweaks i use a testing environment to implement them straight ahead and show the results.
1. Summary and Conclusion
To summarize this Blog take a view on the below Table. It gives you a quick view on the implemented tasks and their expected Impact.
| Layer | Performance Tweak | Expected Impact |
| Database | Source Table Index | Moderate |
| Source Table Statistics | Moderate | |
| Logical View | High | |
| DP Agent | Increase Heap Size | Low |
| Adjust framework Parameter | Low | |
| Replication Task | Replication Task Partitioning | High |
| Virtual Table Statistics | Moderate | |
| Target Table Partitioning | Moderate | |
| Replication Task Filter | High |
Best Performance is achieved by Best Replication Task Design as we can see. Do not leave the other areas out of scope as they are part of the Big Picture but you should stick your broad efforts into the Design of the Replication Task.
As a result of this Workshop we can see that our RT01 Replication Task started with a Run time of about 186.000 ms and ended, after all Tweaks have been applied, at about 67.000 ms. This is an increase of performance in the area of ~ 60 %.
If you had a similar situation and are aware of even more tweaks i would like to know them. Please feel free to add them into the comments.
2. Introduction
2.1 History
| Version | Date | Adjustments |
| 0.1 | 2018.11.01 | Initial creation |
2.2 Architecture
I am using the following architecture as test Environment:
As you can see this is pretty straight forward. A MS SQL Server 2017 is acting as the source Database having the SAP HANA SDI DP Agent 2.0 installed. Destination Database is a SAP HANA 2.0 Database.
2.3 Versioning
I am using the following Versions of Software Applications.
Source System
- Microsoft SQL Server 2017 Developer Edition
- Using the WideWorldImportersDW sample Data
- SAP HANA SDI DP Agent in Version 2.0 SPS 03 Patch 3 (2.3.3)
Target System
- SAP HANA 2.0 SPS 03 Database
2.4 Scope
In Scope of this Blog are Performance Tips and Tricks on the following Layer
- The Source System (Restricted)
- The SAP HANA SDI DP Agent
- The SAP HANA SDI Replication Task
It will cover Database Indexes and Views, SAP HANA SDI DP Agent Parameters as well as Tips and Tricks in the Replication Task design and SAP HANA Parameter settings.
Everything that is not listed here is out of Scope!
2.5 Approach
The approach will look as follows:
- Tweak will be applied
- Replication Task will run three times
- Meridian Run time value out of these three times will be taken as Benchmark
2.6 Application Setup
On source System Level we have the Sale Table from the sample Data. Structure looks as follows:
Row count is about 12 Mill. records
On the Target System we have a standard Replication Task configured for Initial Load. No performance tweaks applied so far.
3. Initial Position
Having the setup running, and no tweaks have been performed so far, the run time for our RT01 Replication Task is at ~ 186.000 ms.
4. Performance Tweaks
See SAP SDI Best Practices as Guideline.
4.1 On Source Database
I want to give you a restricted view on the source Database tweaks as they always differ from your source Database vendor.
Most of the tweaks here were already shipped by the demo Data, but generally spoken you should consider the following Tweaks:
- Create Indexes
- Create Statistics
- Create Database Views
4.1.1 Source Tweak 01 - Create an Index
Already shipped with the Demo Content are some Indexes created on the Table.
Especially important is the Index on the Primary Key. The PK should always be a Part of your Replication Task.
Here you have to contact your source System DBA and let them create your Indexes. Depending on the kind of source system the process differs.
4.1.2 Source Tweak 02 - Create Statistics
Also here, already shipped with the Demo content. We can see the Statistics on the Table.
Parallel to your Index, your DBA should create up-to-date Statistics. It is one solution to create Statistics, and performance will increase instant. Over time the advantage will vanish if your statistics are not up-to-date. Therefore make sure that they are updated automatically.
4.1.3 Source Tweak 03 - Create Database Views
Use a Database View to encapsulate only your Business requirements within the View. Maybe you don`t have to consume the full table but only some columns, maybe you need a JOIN or UNION to another table, you could filter the Data directly in the View and so on.
Filtering could also be done within the Replication Task. But having this kind of logic on the lowest Layer in our overall architecture is the best for your performance.
Databases sent their Query into the Query Optimizer in order to ensure the Best Performance available. As these Query Optimizer are some kind of a black box, we have no insight what happens inside.
You can pass along "Hints" within the View to manually adjust the handling of the Query Optimizer. Also here you need the help of your DBA as this task can get complex and varies from source System kind.
Here i created an example Database View that only takes the columns into account that i actually need for my (artificial) business scenario as well as a Filter. The Views takes 12 out of the 21 columns an retrieves only half of the 12 mill. records.
I now created a simple Replication Task on top of this View and guess what - it was quite fast. Only makes sense as we have fewer columns and fewer rows as from the base "Sale" Table.
The result is at ~ 44.000 ms.
Always consider the impact when you implement a Database View. In our overall Architecture this is another Layer. It includes logic, needs to be maintained and developed. Often development is out of scope within the project team as this has to be done by the DBA.
Remember these organisational challenges.
4.1.4 Source Tweak - Run time
As already mentioned, in my case the source Database tweaks have already been applied as part of the shipped Demo Content from the WideWorldImportersDW Database. So we wont see much progress here.
If you don`t have these on your source Database and you apply these tweaks, you can expect an performance boost.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 187.000 ms.
4.2 On SDI DP Agent
Lets have a look into our second Layer - The SDI DP Agent.
A general rule of thumb is to place the DP Agent as close as possible to the source System. Ideally installed on the same Host as the source System. For sure i had more situation where this was not possible due to IT guidelines as situation were it was.
At least the SDI DP Agent should be in the same Sub net and geographically very very close to the source System.
4.2.1 SDI DP Agent Tweak 01 - Setting the Heap Size
See 2459953
For very large Initial Loads please configure an adequat "-Xmx" Setting in the "dpagent.ini" config File under "<SDI_DP_AGENT_INSTALL_DIR>\dataprovagent".
This Setting really depends on the Size of your Tables that you want to load in an Initial Load szenario. If the Tables contain millions of rows, a setting between 16 - 24 GB is recommended.
I would recommend that you play a little with this Parameter until it fits your purpose.
4.2.2 SDI DP Agent Tweak 02 - Adjusting Parameters
See 2546216
The general rule of thumb with regards to SAP Parameter`s is: Leave it as it is!
Only when you face an issue and the solution is to change a parameter, change the parameter. Solutions are documented in the official SAP Documentation, SAP Note or by a SAP Support Engineer.
Tweak two is to verify two parameters out of the "dpagentconfig.ini" File under "<SDI_DP_AGENT_INSTALL_DIR>\dataprovagent".
The Parameters "framework.serializerPoolSize" and "framework.responsePoolSize" need to have a lower value as the "-Xmx" Parameter.
4.2.3 SDI DP Agent Tweak 03 - Adjusting for partitions
See 2362235
When you use Partitions within your Replication Task...and i encourage you to do so...this Parameter comes into account.
Only when you use a large Number of Partitions this Parameter has to be adjusted manually.
We will learn about Partitioning in Replication Tasks later.
4.2.4 SDI DP Agent Tweak - Runtime
Honestly, i didn`t expect a large performance increase after applying these tweaks. Why? I only run this one replication task and all the resources belong to this one.
Setting Xmx values for java based processes comes always into account when we have a heavy parallel processing, which we don`t have while running these tests.
But in a productive Environment with many large tables that you want to load in parallel you will have a positive result out of these tweaks.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 185.000 ms
At the end of the day a slight improvement.
4.3 On Target HANA Database
Our final Layer is the Target System. Especially the Replication Task design is crucial here. By having the best Replication Task design we get major performance improvements.
4.3.1 Target Tweak 01 - Replication Task Partition
See SDI Documentation
An absolute Must- Have! By using Task Partitioning you cut one large SQL Statement into many small SQL Statements. These will be handled in parallel by the source Database and hence we gain a greater performance.
I would recommend to create the Replication Task Partitions based on the Primary Key. Why? Because in a well fitting Environment we will have an Index and Statistics on our Primary Key. In addition, the PK should always be part of the Replication Task. In that case the PK is our red line through the whole Workflow.
You have a lot of options by using Replication Task Partitioning. I would recommend you check the SDI documentation for the scenario that fits the most.
I usually start with a Range Partition set on the PK and a parallelization of 4.
Whats the correct value for the parallel partitions? No one can tell you! Always keep in mind that those four SQL Statements have to be joined to one at the end of the Workflow. This takes some additional time.
Creating Partitions is like the SDI DP Agent parameters. You have to play a little with the values until you get a satisfied result.
My PK is a BIGINT and the max value is something around 12 Mill. I created four partitions splitting those 12 Mill. records into groups looking like this
"PART_00" Partition fetches all Data until the "Sale Key" 4000000.
"PART_01" Partition fetches all Data from the "Sale Key" 4000001 until 8000000.
And so on...
When i start the Replication Task i can see the process in my DP Task Monitor and also the SQL Statements of the partitions.
Alright. Lets play a little with the partitions and run the RT01 Replication Task a few times.
| Partition Count | Meridian Run time |
| 4 | ~ 111.000 ms |
| 6 | ~ 93.000 ms |
| 8 | ~ 94.000 ms |
| 10(*) | ~ 116.000 ms |
(*) Remember Note 2362235 when having more than 8 Partitions!
As we can see run time increases at a certain point in Time. We get the best Performance with six Partitions. Having more Partitions the run time increases as we produce more overhead for the merge.
So lets stick to the six Partitions with a run time of ~ 93.000 ms.
4.3.2 Target Tweak 02 - Create Statistics
See SAP HANA Documentation
Create Data statistic objects that allow the query optimizer to make better decisions for query plans.
And in our case we can even create statistics on Virtual Tables that will help us to improve the performance of our initial Load.
We run the following Statement in our HANA Database:
CREATE STATISTICS "<STATISTIC_NAME>" ON
"<SCHEMA>"."<VIRTUAL_TABLE>" (<COLUMN>)
TYPE HISTOGRAM
REFRESH TYPE AUTO
ENABLE ON
INITIAL REFRESH
;Here we follow our red line. As column i recommend the usage of your Primary Key as we did on DB Layer with the Index and the Statistics.
REFRESH TYPE should be set to AUTO as in this case HANA decides whats the best refresh type.
ENABLE ON and INITIAL REFRESH are meanwhile the default options.
Having set the statistics on our Virtual Table, the Run time of our RT01 Replication Task is at ~ 81.000 ms.
4.3.3 Target Tweak 03 - Target Table Partition
See 2044468
Partitioning the Target Table brings us the performance gain in a way that the SDI Table Writer can write the Data in parallel into multiple partitions of the Table.
Please be aware that this tweak speeds up the writing processes but can come along with a performance degradation in the reading processes. This is due to the fact that the Query needs to be merged after running over multiple Table partitions. Especially on simple Queries the Table Partitioning can have negative impact.
Therefore i highly recommend that you check the above Note.
In our scenario we will use the Target Table Partitioning being in sync. with our Replication Task Partitions. The recommendation is to have the same amount of Target Table partitions as of Replication Task Partitions and the usage of the PK. If you are running a Scale- Out Scenario it is recommended to split the partitions over all available Nodes.
For the sake of this Blog we will try two types of Partitions. The HASH Partition and the RANGE Partition. The HASH Partition is the most easiest and fastest way to set up partitioning. For the RANGE Partition we need a little more complex setup.
SQL Syntax for setting up the HASH Partition:
ALTER TABLE "<SCHEMA>"."<TARGET_TABLE>"
PARTITION BY HASH ("<COLUMN>")
PARTITIONS <PARTITION_COUNT>
;SQL Syntax for setting up the RANGE Partition:
ALTER TABLE "<SCHEMA>"."<TARGET_TABLE>"
PARTITION BY RANGE ("<COLUMN>")
(USING DEFAULT STORAGE (
PARTITION 1 <= VALUES < 100,
PARTITION 100 <= VALUES < 200,
PARTITION 200 <= VALUES < 300,
PARTITION 300 <= VALUES < 400,
PARTITION 400 <= VALUES < 500,
PARTITION 500 <= VALUES < 600
)
);Result:
| Partition Type | Meridian Run time |
| HASH | ~ 69.000 ms |
| RANGE | ~ 67.000 ms |
We can see that there is not much difference between both Partition types. In that case i would recommend the usage of the HASH partition as this is the one with the easier setup and it requires less maintenance.
For the sake of this Blog i will use the RANGE Partition which results in a run time of or RT01 Replication Task of ~ 67.000 ms.
4.3.4 Target Tweak 04 - Using Filters
This one is quite obvious as in chapter 4.1.3. In the beginning double- check your business requirements. Do you really require all columns from the source Table in your target? Do you really require all rows from the source Table in your target?
Verify these questions with your business department in order to minimize the data transferred over the wire. The less Data, the quicker - Nothing new.
For Demo purpose is added a Filter to our RT01 Replication Task. I`m filtering the Data based on a Date Field. In my case the "Invoice Date Key" Field. I have Demo data from 2012 to 2016. I want to get all the Data from the last three years (2014-2016).
So my Replication Task Filter looks like:
TO_DATE("Invoice Date Key")
BETWEEN
'2014-01-01' AND '2016-12-31'And (again) guess what - quite fast. Meridian run time was at ~ 2800 ms. This is due to the fact that we massively decreased the amount of data that we transfer over the wire. Instead of transferring our 12 mill. records, we transferred ~ 167.000 records.
So i really encourage you to use Replication Task Filter.
For the sake of this Blog i remove the Filter so that we are back on our 12 Mill. records.
4.3.5 Target Tweak - Run time
Tweaking our Replication Task gave us the best results and most out of the Performance. I was expecting this result.
Replication Task Partitioning, Replication Task Filters and Statistics on our Virtual Table are a Must Have! Think twice of using Target Table Partitioning. It could be a draw bag for your analytical scenarios and processes.
After applying these Tweaks the Run time of my RT01 Replication Task is at ~ 67.000 ms
5. Appendix
Additional Information related to this Topic.
5.1 SAP HANA SDI Timeout Parameter Settings
See 2000003 (Point 17)
Timeouts are always an important setting. When you are dealing with long running Replication Tasks i recommend the above SAP Note to you. Especially the "dpserver.ini" Timeouts are relevant for SDI.
Even after applying all these tweaks it is likely possible that your initial load Replication Task runs for hours due to the massive amount of data based on the business requirements.
In any case, check the SDI timeout settings.
See 2363544
I`ll recommend to set the prefetchTimeout Parameter but with a high value. Something about 10800.
- SAP Managed Tags:
- SAP HANA,
- SAP HANA smart data integration
Labels:
12 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
294 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 14 | |
| 13 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 |