
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- Monday morning thoughts: considering GraphQL
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-03-2018
11:16 AM
In this post, I think about GraphQL, and its relationship with existing ideas for managing data and structured exposure to that data over a wire protocol.
Update: This post is now available in audio format too - see the episode on Tech Aloud.
Last week, chris.paine shared with us on Twitter some comments about GraphQL and how it compared with OData. It was an intriguing thought and led to all sorts of discussions. I didn't know much about GraphQL so I took a bit of time to look into it. Not too much time so far, so please take these thoughts as coming from someone with a very limited exposure to GraphQL itself.
What is GraphQL?
GraphQL is an open sourced specification that originated from one of Facebook's engineering teams. One of the pieces I consumed was a talk by one of GraphQL's creators, Lee Byron: "Lessons from 4 years of GraphQL", and one of the takeaways for me was the clear passion that has provided GraphQL with the early success it has been seeing. Beyond the specification, there's a reference implementation in JavaScript, and over time, more than a dozen implementations have emerged, in different languages.

The sample on GraphQL's homepage is a nice overview of what it looks and feels like
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. Like many combinations of specification and implementation, it's also a community, with developers creating implementations of server-side components as well as client-side libraries.
One of the pieces of software you'll see everywhere is Graphiql, a browser-based REPL*-like explorer where you can enter GraphQL queries on the left hand side (see the "Ask for what you want" in the image above) and see the results of those queries on the right hand side (see the "Get predictable results" in the image above). Queries and response are in the form of JSON-like structures, which is nice.
*REPL stands for Read Evaluate Print Loop and in many languages is a simple realtime environment in which you can interact with the language or service directly, to manually program or explore the possibilities it offers.
A fundamentally different data store
One of the core features of GraphQL is the shape of the data store. It's not hierarchical, it's not relational, it's graphical. Entities persisted are generally either nodes - things - or arcs - relationships between things. I'm using the words "nodes" and "arcs" because the data store is nothing new - certainly not in my experience.
Back in the day, even before the SAP Community Network was born (which was in 2003), there was a lot of activity and thinking around the theme of the Semantic Web, the idea that the content of what was stored and retrieved via HTTP could be described in a separate, rich, semantic layer that could bring meaning to entities on the Web. Meaning in terms of what types of things the resources represented, and meaning in terms of how they were related.
This meaning was expressed in terms of nodes (the resources) and arcs (the relationships between those nodes), and the language that was used to describe these nodes and arcs was the Resource Description Framework (RDF), and the various ontological languages that were based on and used in conjunction with RDF (OWL - the "Web Ontology Language" is one of the more well known of those, along with Dublin Core).
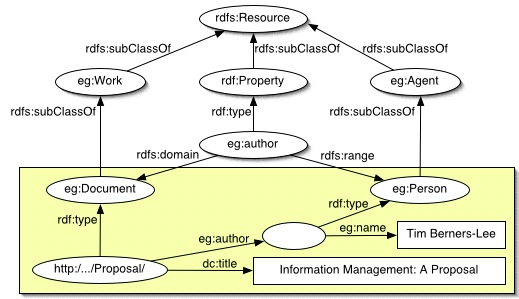
RDF nodes and arcs
I have been fascinated by RDF for a long time, and dabbled in various aspects in the early 2000's - see the RDF related posts on my blog for some ramblings on that subject. Of course, RDF can be seen as one of the ancestors* of OData, which in a way is rather ironic.
*RSS was originally an RDF-based language (RSS stood for RDF Site Summary at the time), Atom was a successor to RSS, and OData was an extension of Atom (along with the Atom Publishing Protocol). But that's a story for another time.
RDF and graph databases
RDF information is expressed in so-called "triples" in the form:
where "subject" and "object" entities are nodes and "predicates" are arcs - the lines between them. Triples are stored in "triplestores", and a more generalised form of a triplestore is ... wait for it ... a graph database.
To me, there is a fundamental beauty in the tension between the simple structure of triples, and the unstructured, or perhaps unrestricted nature of what you can store with triples. It's quite far from the schema-restrained model of relational data stores. With a graph data store you can store information you hadn't planned for, and ask questions of the data that you could have never foreseen at the outset. You can imagine an ever-growing network of arcs and nodes, of differing types and properties, being added to a graph database, and new queries being made on that database, filtering on properties and relationships that weren't even around at the outset.
GraphQL, as a data store, then, is rather powerful. There are of course other examples of graph data stores - one that comes to mind immediately is Neo4j, which has been around for a long time.
Irony
Why is it ironic that RDF, with its closely related graph data store concept and link to GraphQL, is an ancestor of OData?
Because when you move up the stack from the data store to the protocol, things could hardly be more different. Here's a quick summary of the major differences I see between OData and GraphQL, at a protocol level.
In some ways GraphQL at the protocol level reminds me of web services. Not the entire WS-Deathstar panoply of specifications -- rather, the way that there's a single endpoint for all operations and all queries. This makes me somewhat uncomfortable. Not because it feels like a return to the bad old days of web services, but because it just doesn't feel right to me, as an advocate of what HTTP is (an application protocol and arguably the best example of a powerful, distributed web service, but that's a story for another time).
Comparing and contrasting
The OData protocol treats data (entities) as first class citizens, in that it gives each resource a URL, a URL that can then be semantically described, a URL that is part of a near infinite set of resources (nouns), with a very finite and predictable set of methods (verbs). Moreover, it comes with a built-in metadata and annotation layer, which can be used by consuming clients to great effect.
GraphQL, on the other hand, seems to treat data as merely the by-product of a query. If I want to point to some data which I want to describe with its own address, and then further annotate that (even at the RDF level, but perhaps that's going too far), I'm not sure how I'd do it with the GraphQL protocol.
Talking of GraphQL queries, it would also seem that there's a URL encoding of the query which to my eyes is rather unappealing. Yes, URLs should be opaque, we've touched on that in a previous Monday morning thoughts post, but I still maintain that there's a pragmatic aspect that means, at least for me, human readable URLs are super useful at the practical level.
And talking of pragmatism and practicality, there's been a question about GraphQL implementation in SAP systems. The SAP systems with which I'm most acquainted -- the successors to the R/2 and R/3 line of products -- are based on a hierarchical database design, not a graph design. That's not to say that things can't change ... indeed, we moved from hierarchical to relational in the late 1980's when SAP introduced the support for IBM's (then) new relational data store DB/2, which eventually superseded IMS DB's hierarchical data store DL/1. Moreover, the power and simplicity that HANA brings is not graph store based, it's column store based. So I can't imagine any straightforward conversion any time soon, even if it was the right decision.
That doesn't mean, however, that we can't embrace the ideas of GraphQL in different areas. While I can't imagine a straightforward replacement at the enterprise data store level, I can, for example, more easily imagine an annotation model in UI5 that would support data driven UIs with Fiori elements, based on a GraphQL powered backend.
As I said at the start of this post, it's still very early days for me with GraphQL, and I have a lot more to learn. Rather than see GraphQL as any sort of competitor to the status quo, or as simply the new kid on the block that's better than anything that's been before, by default, I see GraphQL as something wonderful in how it challenges our thinking, reminds us of our past, and adds to the richness of how we consider data and protocol architecture at a high level.
What are your thoughts about GraphQL and what it can bring to our architectural and development landscape? I'd love to hear what they are.

Our canal boat, moored this morning between Altrincham and Dunham Massey
This post was brought to you from the peace and quiet of a Monday morning here on the Bridgewater Canal, where I'm spending time on a canal boat with M on my birthday today.
Read more posts in this series here: Monday morning thoughts.
Update 07 Sep 2018: This is the tweet from Chris Paine that started it off: https://twitter.com/wombling/status/1034949320519245824, referring to a tweet by Jeff Handley.
Update 14 Sep 2018: Jeff published a very interesting blog post yesterday: GraphQL is not OData. It's a super read, with lots of history and balanced thoughts, and I enjoyed it very much. I will have to read it at least one more time for the thoughts to sink in. I'd recommend it heartily.
I certainly agree with the post's premise - GraphQL is certainly not OData, as you can see from Jeff's post, but perhaps also from this one. The key takeaway for me so far from Jeff's post (apart from the title) is that GraphQL and OData can actually live side by side, as GraphQL's fit seems to be as an intermediary. I need to think about that some more, but for now, let the conversation and education continue!
Update: This post is now available in audio format too - see the episode on Tech Aloud.
Last week, chris.paine shared with us on Twitter some comments about GraphQL and how it compared with OData. It was an intriguing thought and led to all sorts of discussions. I didn't know much about GraphQL so I took a bit of time to look into it. Not too much time so far, so please take these thoughts as coming from someone with a very limited exposure to GraphQL itself.
What is GraphQL?
GraphQL is an open sourced specification that originated from one of Facebook's engineering teams. One of the pieces I consumed was a talk by one of GraphQL's creators, Lee Byron: "Lessons from 4 years of GraphQL", and one of the takeaways for me was the clear passion that has provided GraphQL with the early success it has been seeing. Beyond the specification, there's a reference implementation in JavaScript, and over time, more than a dozen implementations have emerged, in different languages.
The sample on GraphQL's homepage is a nice overview of what it looks and feels like
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. Like many combinations of specification and implementation, it's also a community, with developers creating implementations of server-side components as well as client-side libraries.
One of the pieces of software you'll see everywhere is Graphiql, a browser-based REPL*-like explorer where you can enter GraphQL queries on the left hand side (see the "Ask for what you want" in the image above) and see the results of those queries on the right hand side (see the "Get predictable results" in the image above). Queries and response are in the form of JSON-like structures, which is nice.
*REPL stands for Read Evaluate Print Loop and in many languages is a simple realtime environment in which you can interact with the language or service directly, to manually program or explore the possibilities it offers.
A fundamentally different data store
One of the core features of GraphQL is the shape of the data store. It's not hierarchical, it's not relational, it's graphical. Entities persisted are generally either nodes - things - or arcs - relationships between things. I'm using the words "nodes" and "arcs" because the data store is nothing new - certainly not in my experience.
Back in the day, even before the SAP Community Network was born (which was in 2003), there was a lot of activity and thinking around the theme of the Semantic Web, the idea that the content of what was stored and retrieved via HTTP could be described in a separate, rich, semantic layer that could bring meaning to entities on the Web. Meaning in terms of what types of things the resources represented, and meaning in terms of how they were related.
This meaning was expressed in terms of nodes (the resources) and arcs (the relationships between those nodes), and the language that was used to describe these nodes and arcs was the Resource Description Framework (RDF), and the various ontological languages that were based on and used in conjunction with RDF (OWL - the "Web Ontology Language" is one of the more well known of those, along with Dublin Core).
RDF nodes and arcs
I have been fascinated by RDF for a long time, and dabbled in various aspects in the early 2000's - see the RDF related posts on my blog for some ramblings on that subject. Of course, RDF can be seen as one of the ancestors* of OData, which in a way is rather ironic.
*RSS was originally an RDF-based language (RSS stood for RDF Site Summary at the time), Atom was a successor to RSS, and OData was an extension of Atom (along with the Atom Publishing Protocol). But that's a story for another time.
RDF and graph databases
RDF information is expressed in so-called "triples" in the form:
[subject] ---[predicate]---> [object]where "subject" and "object" entities are nodes and "predicates" are arcs - the lines between them. Triples are stored in "triplestores", and a more generalised form of a triplestore is ... wait for it ... a graph database.
To me, there is a fundamental beauty in the tension between the simple structure of triples, and the unstructured, or perhaps unrestricted nature of what you can store with triples. It's quite far from the schema-restrained model of relational data stores. With a graph data store you can store information you hadn't planned for, and ask questions of the data that you could have never foreseen at the outset. You can imagine an ever-growing network of arcs and nodes, of differing types and properties, being added to a graph database, and new queries being made on that database, filtering on properties and relationships that weren't even around at the outset.
GraphQL, as a data store, then, is rather powerful. There are of course other examples of graph data stores - one that comes to mind immediately is Neo4j, which has been around for a long time.
Irony
Why is it ironic that RDF, with its closely related graph data store concept and link to GraphQL, is an ancestor of OData?
Because when you move up the stack from the data store to the protocol, things could hardly be more different. Here's a quick summary of the major differences I see between OData and GraphQL, at a protocol level.
| OData | GraphQL |
| Treats HTTP as an application protocol and aims for rough parity between OData operations and HTTP methods | Treats HTTP mainly as a transport protocol |
| Operations are transparent at an HTTP level | Operations are opaque at an HTTP level |
| Static schema-based data structures fixed at design time | Dynamic schema-less data structures |
| Fixed query options | Powerful query options |
| Easy to reason about from a security perspective | Harder to reason about because of the opaque nature of the protocol implementation |
| Endpoints that represent the business data | Single endpoint that represents the query "socket" |
In some ways GraphQL at the protocol level reminds me of web services. Not the entire WS-Deathstar panoply of specifications -- rather, the way that there's a single endpoint for all operations and all queries. This makes me somewhat uncomfortable. Not because it feels like a return to the bad old days of web services, but because it just doesn't feel right to me, as an advocate of what HTTP is (an application protocol and arguably the best example of a powerful, distributed web service, but that's a story for another time).
Comparing and contrasting
The OData protocol treats data (entities) as first class citizens, in that it gives each resource a URL, a URL that can then be semantically described, a URL that is part of a near infinite set of resources (nouns), with a very finite and predictable set of methods (verbs). Moreover, it comes with a built-in metadata and annotation layer, which can be used by consuming clients to great effect.
GraphQL, on the other hand, seems to treat data as merely the by-product of a query. If I want to point to some data which I want to describe with its own address, and then further annotate that (even at the RDF level, but perhaps that's going too far), I'm not sure how I'd do it with the GraphQL protocol.
Talking of GraphQL queries, it would also seem that there's a URL encoding of the query which to my eyes is rather unappealing. Yes, URLs should be opaque, we've touched on that in a previous Monday morning thoughts post, but I still maintain that there's a pragmatic aspect that means, at least for me, human readable URLs are super useful at the practical level.
And talking of pragmatism and practicality, there's been a question about GraphQL implementation in SAP systems. The SAP systems with which I'm most acquainted -- the successors to the R/2 and R/3 line of products -- are based on a hierarchical database design, not a graph design. That's not to say that things can't change ... indeed, we moved from hierarchical to relational in the late 1980's when SAP introduced the support for IBM's (then) new relational data store DB/2, which eventually superseded IMS DB's hierarchical data store DL/1. Moreover, the power and simplicity that HANA brings is not graph store based, it's column store based. So I can't imagine any straightforward conversion any time soon, even if it was the right decision.
That doesn't mean, however, that we can't embrace the ideas of GraphQL in different areas. While I can't imagine a straightforward replacement at the enterprise data store level, I can, for example, more easily imagine an annotation model in UI5 that would support data driven UIs with Fiori elements, based on a GraphQL powered backend.
As I said at the start of this post, it's still very early days for me with GraphQL, and I have a lot more to learn. Rather than see GraphQL as any sort of competitor to the status quo, or as simply the new kid on the block that's better than anything that's been before, by default, I see GraphQL as something wonderful in how it challenges our thinking, reminds us of our past, and adds to the richness of how we consider data and protocol architecture at a high level.
What are your thoughts about GraphQL and what it can bring to our architectural and development landscape? I'd love to hear what they are.
Our canal boat, moored this morning between Altrincham and Dunham Massey
This post was brought to you from the peace and quiet of a Monday morning here on the Bridgewater Canal, where I'm spending time on a canal boat with M on my birthday today.
Read more posts in this series here: Monday morning thoughts.
Update 07 Sep 2018: This is the tweet from Chris Paine that started it off: https://twitter.com/wombling/status/1034949320519245824, referring to a tweet by Jeff Handley.
Update 14 Sep 2018: Jeff published a very interesting blog post yesterday: GraphQL is not OData. It's a super read, with lots of history and balanced thoughts, and I enjoyed it very much. I will have to read it at least one more time for the thoughts to sink in. I'd recommend it heartily.
I certainly agree with the post's premise - GraphQL is certainly not OData, as you can see from Jeff's post, but perhaps also from this one. The key takeaway for me so far from Jeff's post (apart from the title) is that GraphQL and OData can actually live side by side, as GraphQL's fit seems to be as an intermediary. I need to think about that some more, but for now, let the conversation and education continue!
- SAP Managed Tags:
- Research and Development
32 Comments
Related Content
- Late Coming and Early Departure Detection for Double Shifts on the same day - SF Time Tracking in Human Capital Management Blogs by Members
- Learn Content Structure Changes after Item Revision by Item Connector in Human Capital Management Q&A
- Freight Generation in Data Collation Document using Freight Rate Table or Pricing Multireference in Supply Chain Management Blogs by Members
- Long Awaited Transformation for Your Credentials in Technology Blogs by Members
- SAP Premium Engagement Session 'Accelerate Business Transformation with AI' (May 16, 2024) in CRM and CX Blogs by SAP