
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hoeffding Tree Overview – Creating a Scoring Proje...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
aaron_patkau
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-28-2018
7:11 PM

Welcome to the final installment of the Hoeffding Tree machine learning series, where you build a streaming project in SAP HANA studio that can execute a scoring model. The fourth video is now available:
To see how we got here, check out the previous content:
- Creating a Training Model (Part 1) – video and blog
- Creating a Training Project (Part 2) – video and blog
- Creating a Scoring Model (Part 3) - video and blog
Here’s a summary of part 4, and then a quick review of the series.
Summary
Part 4 involves creating and building a project that uses the scoring model you created earlier to predict if financial claims are likely to be fraudulent. The scoring model stream applies what it learned from the training data to make these predictions.
Like before, you’ll build the project using a CCL code snippet, and you’ll upload the financial claims data from a CSV file. You can download these from https://github.com/saphanaacademy/SDS. As mentioned in a previous blog post, the code in GitHub is not official SAP code, it is sample code that you’ll use for this tutorial series.
You can get your scoring data from the CLAIMS_SCORE.csv file. This file contains data from the input stream, ‘in1’, which includes:
- ID,
- policy type,
- age of the claimant, and
- department of the claimant.
Here’s a look at the data:

Before uploading this data, you need to create and build a project.
Creating and building a project
In studio or Web IDE, create a new project. Then, copy the CCL from the sha_hoeffding_score.ccl file and replace the default CCL in your project with the CCL you just copied.
The CCL structure is the same as what we saw in the training phase:
- Create the input and output schemas.
- Declare the model.
- Set the schemas and data service connection.
- Create any number of input and output streams you require. Again, one input stream needs to gather the data, and one output stream needs to execute the model.
Here’s what the CCL looks like:
CREATE SCHEMA schema_in (ID integer, POLICY string, AGE integer, AMOUNT integer, OCCUPATION string);
CREATE SCHEMA schema_out (ID integer, FRAUD string, PROBABILITY double);
DECLARE MODEL hoeffdingscore
TYPE MACHINE_LEARNING
INPUT SCHEMA schema_in
OUTPUT SCHEMA schema_out
PROPERTIES dataservice = 'hanaservice'
;
CREATE INPUT STREAM in1
SCHEMA schema_in
;
CREATE OUTPUT STREAM model_stream AS
EXECUTE MODEL hoeffdingscore
FROM in1
;
CREATE OUTPUT STREAM out1 AS
SELECT * FROM model_stream
;These input and output schemas mirror the schemas you used in the previous blog, where you created your scoring model. The ‘DECLARE MODEL’ statement sets the name of the model, the input and output schemas, and the data service. The input stream, ‘in1’, collects the scoring data, and the output stream, ‘model_stream’, collects this data from ‘in1’ and executes the scoring model. Another output stream, ‘out1’, collects all results. You can write ‘out1’ to a HANA table, or stream it to wherever you want.
Note: The names of the scoring model and data service must match the names in your landscape. For us, the model name is ‘hoeffdingscore’ and the data service name is ‘hanaservice’.
The project’s built, so now you can compile and run it on your workspace.
Once running, open the input and output streams so you can see the data when it uploads.
Uploading data and viewing the output
Via the File Upload view, browse for the CLAIMS_SCORE.csv file. Choose which project you want your input stream to be sent to by hitting the Select Project
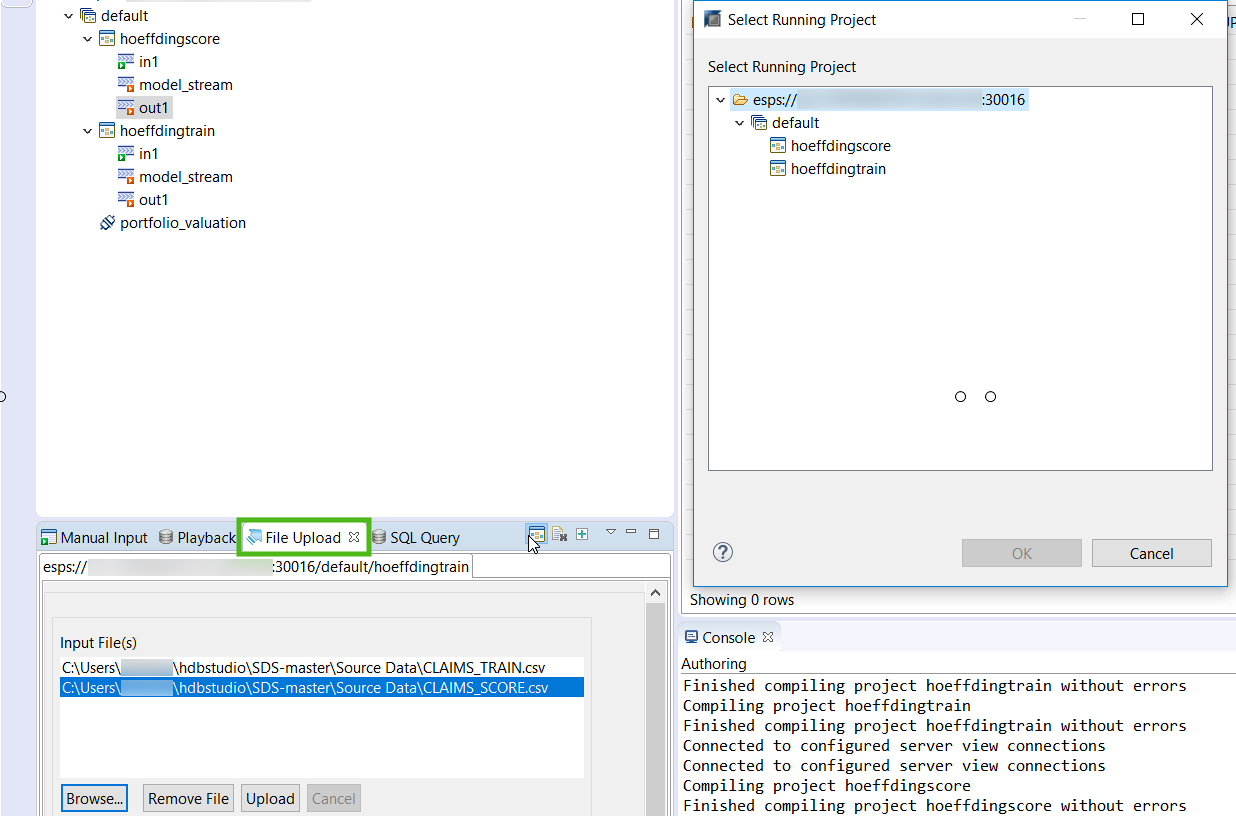
With the scoring file selected, hit Upload.
The input tab shows 5 rows:

The output tab shows the results. As seen below, none of the transactions are identified as being potentially fraudulent:

Thankfully, there’s nearly an 80 percent probability that the scoring model stream is correct with its predictions. But, if there were a fraudulent claim and you needed to know about it, then you could set up an alert system. All you’d have to do is filter fraudulent claims into a derived window and then use an adapter to output that info somewhere, like to a dashboard or email account. For details on generating alerts using a derived window, check out this tutorial.
Review
To sum up this series, we began with the training phase where you created a training model and executed it in a project. This model is continually updated as new data arrives in the input stream. Next was the scoring phase, where you built a scoring model to score new data in a project. You used the training data to identify whether transactions are likely to be fraudulent or legitimate.
For more on machine learning models, check out the Model Management section of the Streaming Analytics Developer Guide. If you’re interested in creating machine learning models in Web IDE, then check out this blog post.
- SAP Managed Tags:
- SAP HANA streaming analytics,
- SAP Business Technology Platform
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- Easy way to automate and configure the setup of a BTP account and Cloud Foundry using Terraform. in Technology Blogs by Members
- Accelerate Business Process Development with SAP Build Process Automation Pre-Built Content in Technology Blogs by SAP
- Comprehensive Guideline to SAP VMS in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 36 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |