
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Implementing dynamic Lookups in CPI using Hashmap ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
KarthikBangeraM
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-09-2018
5:54 AM
You would often have come across a requirement to perform lookups dynamically to an external cloud OData service entity and fetch the details and modify existing payloads in CPI. We had a similar requirement in one of our C4C Data Migration Implementations.
We were required to lookup a Customer Table exposed by OData, provide it the External ID from our main business payload coming from a Legacy CRM and fetch the corresponding C4C Internal ID and update the same in our original payload before feeding it finally to C4C.
Initially, we planned to use a content enricher to achieve this, however we wished to persist those values by storing them in data store for subsequent calls on the same day to improve the iflow performance and also there was a requirement in the same iflow to perform lookups with multiple primary keys for another C4C entity which wouldn't have been possible with content enricher. Therefore, we decided to give Hashmap object a try in CPI along with XMLSlurper and XMLParser for parsing and modifying the XMLs since these are lightweight xml parsers and therefore highly recommended.
There are 2 parts to the below scenario-
In the first part, we will fill the Hashmap object with all the Key Value pairs which are present in XML format. In the real-life scenario this xml is fetched from C4C OData call. We would test this with around 0.3 million records to see how good its performance is.
Below is the iFlow screenshot-
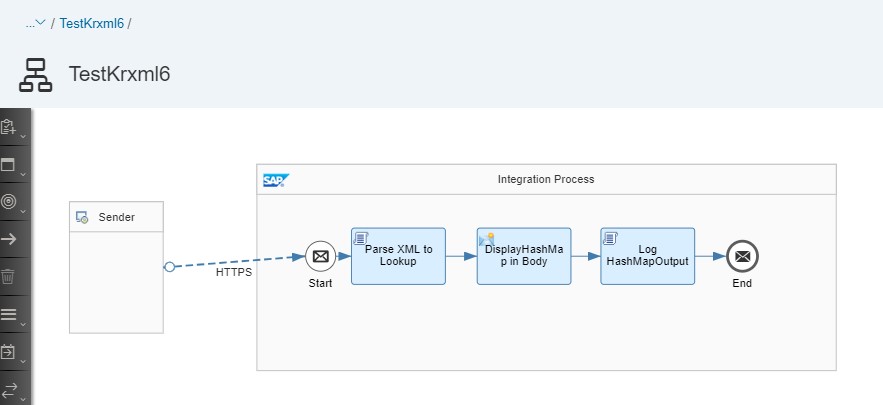
Simple groovy script for parsing the lookup XML into the HashMap object-
In the next 2 steps we are just logging the hashmap output.
The test payload with around 0.3 million key value pairs will be triggered to the iFlow.

Within 30 seconds we can get the output.
Message Processing in CPI-

The HashMap output with 0.3 million records will be stored in Properties in the below format-

Often we commit the mistake of looping XMLSlurper object using our conventional and favourite ‘For’ statement. This drastically impacts the performance of the iFlow as shown below. This may not be an issue when your lookup size is within say 15000 records. The processing time increases exponentially for higher numbers and impacts iFlow performance.
Below is an example-

Code Snippet-
As we can see below the performance of this interface was affected and it took almost 2 hours to process these records-

2nd Part of the scenario would be using the previously stored HashMap in Property to do a lookup to get the InternalID for the corresponding ExternalID in each of the records.
Below is the updated iFlow-

We would be using the XMLParser class instead of XMLSlurper since we wish to Read as well as Modify the XML at the same time. This isn’t possible in XMLSlurper since it has a Lazy way of Parsing xml files, i.e., if you update any field while in the loop, you must parse the whole document again, therefore this isn’t performance efficient. Using XMLParser, you can read and modify a XML at the same time with a single line of code.
Code Snippet-
Once ready, again the xml containing the 0.3 million key pair values are triggered to the iFlow-

Again the processing is seen to be quite efficient at close to 59 seconds. It should be noted that within this timeframe an xml of around 0.3 million records was read and parsed into a HashMap variable and then the HashMap was looked up against an xml with 30K business data records to update field (InternalID) of each record. This involved Read and Update operation on each of these records.

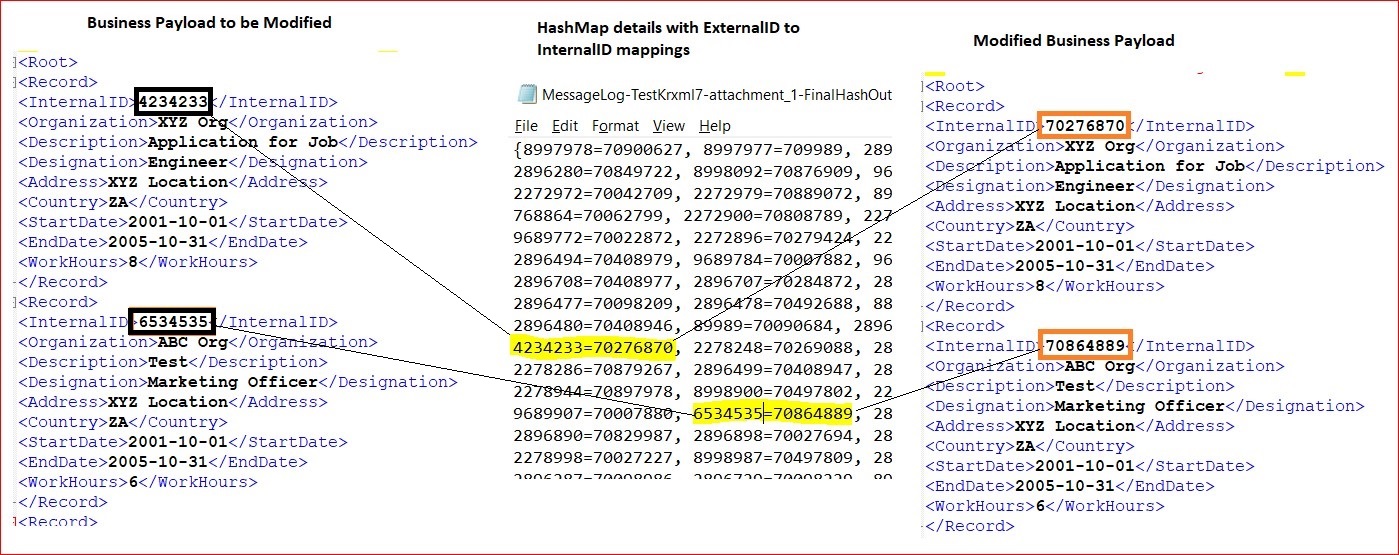
Logged Payloads-

Below is the sample of 2 of the records from the business payload which were modified (around 30K records in total).
Advantages as compared to Content Enricher-
In the next blog I will cover the Json Parser method which can be used in cases where the response from your lookup service is in JSON format and you wish to avoid converting large payloads from XML to JSON format.
Regards,
Karthik Bangera
Requirement-
We were required to lookup a Customer Table exposed by OData, provide it the External ID from our main business payload coming from a Legacy CRM and fetch the corresponding C4C Internal ID and update the same in our original payload before feeding it finally to C4C.
Options-
Initially, we planned to use a content enricher to achieve this, however we wished to persist those values by storing them in data store for subsequent calls on the same day to improve the iflow performance and also there was a requirement in the same iflow to perform lookups with multiple primary keys for another C4C entity which wouldn't have been possible with content enricher. Therefore, we decided to give Hashmap object a try in CPI along with XMLSlurper and XMLParser for parsing and modifying the XMLs since these are lightweight xml parsers and therefore highly recommended.
Test Scenario-
There are 2 parts to the below scenario-
In the first part, we will fill the Hashmap object with all the Key Value pairs which are present in XML format. In the real-life scenario this xml is fetched from C4C OData call. We would test this with around 0.3 million records to see how good its performance is.
Below is the iFlow screenshot-
Simple groovy script for parsing the lookup XML into the HashMap object-
import com.sap.gateway.ip.core.customdev.util.Message;
import java.util.HashMap;
import groovy.xml.*;
import java.util.regex.*;
import java.io.*;
def Message processData(Message message) {
def body = message.getBody(java.io.Reader);
HashMap<Integer, String> hmap1 = new HashMap<Integer, String>();
map = message.getProperties();
def Root = new XmlSlurper().parse(body);
Root.Record.each{
try{
hmap1.put(Integer.parseInt(it.ExternalID.text().toString()), it.InternalID.text().toString());
}
catch(Exception ex){
//do nothing, skip the record
}
}
message.setProperty("hashmapOutput", hmap1);
return message;
}In the next 2 steps we are just logging the hashmap output.
The test payload with around 0.3 million key value pairs will be triggered to the iFlow.
Within 30 seconds we can get the output.
Message Processing in CPI-
The HashMap output with 0.3 million records will be stored in Properties in the below format-
Don’ts of XMLSlurper Parsing!!!
Often we commit the mistake of looping XMLSlurper object using our conventional and favourite ‘For’ statement. This drastically impacts the performance of the iFlow as shown below. This may not be an issue when your lookup size is within say 15000 records. The processing time increases exponentially for higher numbers and impacts iFlow performance.
Below is an example-
Code Snippet-
import com.sap.gateway.ip.core.customdev.util.Message;
import java.util.HashMap;
import groovy.xml.*;
import java.util.regex.*;
import java.io.*;
def Message processData(Message message) {
def body = message.getBody(java.io.Reader);
HashMap<Integer, String> hmap1 = new HashMap<Integer, String>();
map = message.getProperties();
def Root = new XmlSlurper().parse(body);
for(int j=0; j<Root.Record.size(); j++){
hmap1.put(Integer.parseInt(Root.Record.ExternalID[j].text()), Root.Record.InternalID[j].text());
}
message.setProperty("hashmapOutput", hmap1);
return message;
}As we can see below the performance of this interface was affected and it took almost 2 hours to process these records-
2nd Part of the scenario would be using the previously stored HashMap in Property to do a lookup to get the InternalID for the corresponding ExternalID in each of the records.
Below is the updated iFlow-
Advantages of XMLParser over XMLSlurper-
We would be using the XMLParser class instead of XMLSlurper since we wish to Read as well as Modify the XML at the same time. This isn’t possible in XMLSlurper since it has a Lazy way of Parsing xml files, i.e., if you update any field while in the loop, you must parse the whole document again, therefore this isn’t performance efficient. Using XMLParser, you can read and modify a XML at the same time with a single line of code.
Code Snippet-
import com.sap.gateway.ip.core.customdev.util.Message;
import java.util.HashMap;
import groovy.xml.*;
import java.util.regex.*;
import java.io.*;
def Message processData(Message message) {
def body = message.getBody(java.lang.String);
def messageLog = messageLogFactory.getMessageLog(message);
map = message.getProperties();
def hmap1 = map.get("hashmapOutput");
def Root = new XmlParser().parseText(body);
Root.Record.each{r->r.InternalID[0].value =
hmap1.get(Integer.parseInt(r.InternalID[0].text().toString()))}
message.setBody(XmlUtil.serialize(Root));
messageLog.addAttachmentAsString("FinalOutput:", body.toString(), "text/plain");
return message;
}
Once ready, again the xml containing the 0.3 million key pair values are triggered to the iFlow-
Again the processing is seen to be quite efficient at close to 59 seconds. It should be noted that within this timeframe an xml of around 0.3 million records was read and parsed into a HashMap variable and then the HashMap was looked up against an xml with 30K business data records to update field (InternalID) of each record. This involved Read and Update operation on each of these records.
Logged Payloads-
Below is the sample of 2 of the records from the business payload which were modified (around 30K records in total).
Advantages as compared to Content Enricher-
- Multiple Key values can be concatenated and stored in the Key variable of a Hashmap.
- Can be used after a Looping process to add the collated values into a Hashmap to be referred anywhere in the iFlow
- Can be stored in Data stores to be accessible across iFlows
In the next blog I will cover the Json Parser method which can be used in cases where the response from your lookup service is in JSON format and you wish to avoid converting large payloads from XML to JSON format.
Regards,
Karthik Bangera
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
281 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Augmenting SAP BTP Use Cases with AI Foundation: A Deep Dive into the Generative AI Hub in Technology Blogs by SAP
- Unlocking Hashmap Magic: Efficient Bulk Data Lookup with Value Mapping in SAP CI using Groovy/XSLT in Technology Blogs by SAP
- Deliver real-life use cases with SAP BTP – Returnable Packaging in Technology Blogs by SAP
- Rate Limiter Implementation in an SAP CAP Application in Technology Blogs by SAP
- Part 2: How to build an Integration Architecture for the Intelligent Enterprise in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |