
- SAP Community
- Products and Technology
- CRM and Customer Experience
- CRM and CX Blogs by Members
- SAP CAR - POS transactions aggregation
CRM and CX Blogs by Members
Find insights on SAP customer relationship management and customer experience products in blog posts from community members. Post your own perspective today!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
maciej_jarecki
Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-15-2018
1:18 PM
The main purpose of aggregation is to increase of performance and reduce time of processing and volume of data generated and sent to target system. Additionally data sent to target system is already conformed at sender side to the format of receiver system.
SAP CAR provides two options for aggregation of POS transactions. Simpler solution would be to set up automatic aggregation for processing of tasks that are processed with the single-step procedure. More complex and as well efficient (when number of transactions) is to set up form of aggregates that first stores data in the database and then aggregates are processed by a subsequent step.
Alike simple and complex aggregations are performed by tasks.
Common configuration for both methods.
Both aggregation methods have few configuration settings that are used in common. At the beginning it's worth to mention that for most of operations, activities you can implement parameters that could be later on used in BADIs to achieve greater flexibility of the solution.

As an entrance for both of types of aggregations is configuration of aggregation period and aggregation method.
Aggregation Period allows more detailed split of POS transactions based on for example period of time. Time unit is not mandatory here as separator, it could be freely defined implementation of BADI: /POSDW/BADI_GET_AGGR_GROUP
Aggregation Method

Aggregation method ZMA1 shows that data for aggregation is split by Sales Item and Material number by standard BADI (/POSDW/COMPRESSION) implementation – 0001. To achieve finer grouping criteria, aggregation period can be taken into account like posting date etc (as described in aggregation period).This ensures that only POS transactions that are in the same aggregation period are aggregated together via Badi implementation (example of method Z001). In my example aggregation is done only with content of transaction and summarization period is not taken into account.
One-step specific configuration
Next step is to create a task for generating data to follow-on system and include grouping.

Start of task is manual as aggregation is executed for multiple POS transactions. Filter for BADI is 0010 – Create Idoc WPUBON. 0010 is simple an implementation of Badi (/POSDW/TASK) that process task. If you would like to aggregate data (one-step) field ‘code for aggregation method’ is where you place previously configured aggregation method. As mentioned before to achieve greater flexibility parameter group might be assigned and used by Badi implementation.
Next part of customization is common for One-step and Two-Steps task processing. Each POS transaction could be assigned to task group.
First task group is defined and then tasks are assigned to it like presented below.


By this assignment we indicate that for transaction ZMT1 all tasks from task group ZTG1 are valid (if task processing is set to including). Additionally for the purpose of aggregation I can set three grouping keys and use them in Badi implementation.
Testing
For the testing purpose I will create (via inbound Idoc) four POS transactions. All will have same transaction type (ZMT1: MJ: Sales1), same shops (as follow-on Idoc is created per store in this Badi implementation) and two different materials. Additionally transactions are registered on two posting dates.

By executing task (where aggregation is applied or not) from transaction: /POSDW/PDIS new Idoc has been created to follow-on system that contains information about aggregated sales.

Two-steps specific configuration
Two-steps aggregation splits process into two phases: aggregation and outbound processing. During first step, task creates aggregate package. The system forms a new aggregate package if no open one exists for the chosen aggregation method. If another aggregate exists with aggregated data records, which has not yet been completed, the system aggregates the data of the POS transactions to be processed in this aggregate. Aggregation package is an input data for second task which is called outbound task. During this task, data is converted to receiving system specific format and is sent to follow-on systems.
Configuration starts with aggregation level.
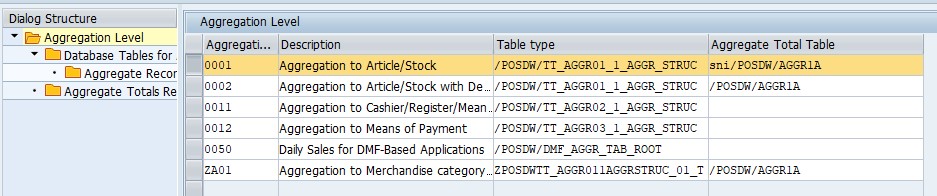
Table type column describes structure that is used during aggregation processing. Total Table is a database table used for storing summarized information about aggregation. All these dictionary elements can be created by user and later used in aggregation processing. In case of aggregation level 0001 structure used in aggregation processing is /POSDW/TT_AGGR01_1_AGGR_STRUC and summary of aggregations is stored in table /POSDW/AGGR1A.
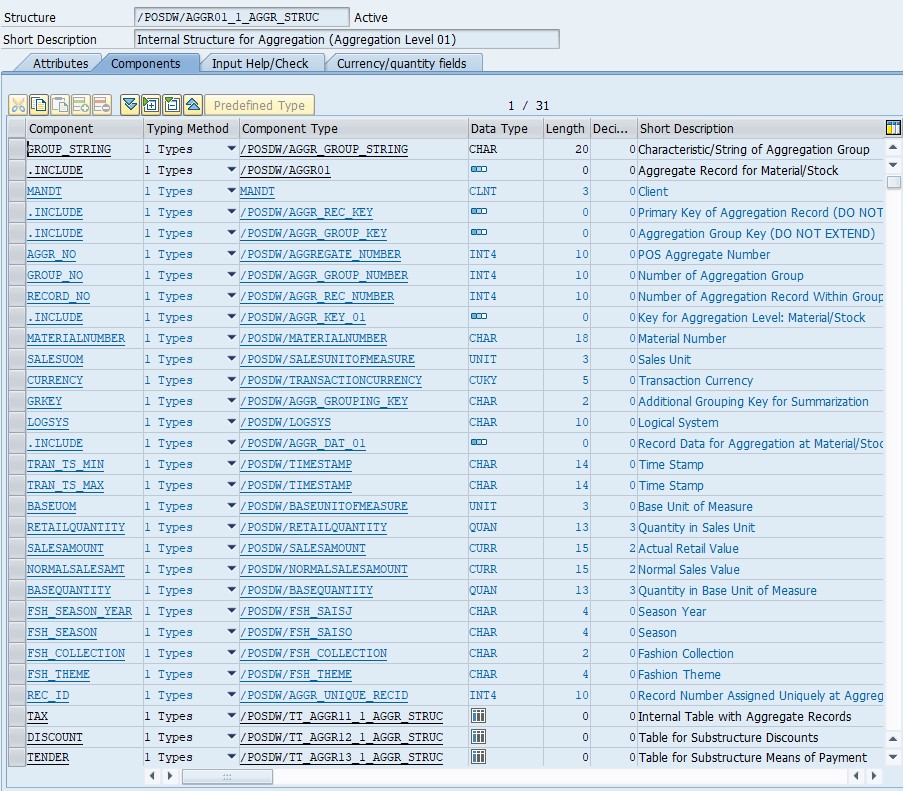

By default aggregations are stored on single level of aggregation in table /POSDW/AGGR01. Group name RECORD contains the entire record of the actual database table <Root> as an include of structure used for aggregation processing (previous screenshot). Additionally there is a possibility to split data per multiple database table. As it's in case of aggregation level 0002, Tax data is stored in /POSDW/AGGR11 table and discounts in /POSDW/AGGR12. Field name of table describe include from aggregation processing structure (/POSDW/TT_AGGR01_1_AGGR_STRUC) that contains data to be stored.

Last step of the configuration for aggregation levels is to decide how some non-key fields are going to be processed if record already exists, override, add, max or min.
Very useful is SAP Note: 980272 - Implementing tasks for two-step processing, which describes step by step how to create custom structures, tables and configure it.
Aggregation task
Next step is to create aggregation task for two step processing. Generally idea is the same but only few different fields exist.

Type of task needs to be always 1 – Collective processing. Beside of that comparing to previous one-step configuration only aggregation level and aggregation period (this parameter is described in common part of the article) are needed.
Outbound task

This is the last configuration required to be configured. Tasks – Badi (Filter) specifies implementation of Badi to execute operation on previously aggregated data (usually it’s sending data to follow-on system). Because our aggregation task ZAG1 uses different structure then implementation of Badi that process the data (3001 uses /POSDW/TT_AGGR_SALES_W_DETAILS) mapping between structures is required. Table type describes target structure, source structure is in aggregation level and mapping is done by implementation if Badi specified in transfer filter field.
Testing:
For the testing purpose I would like to use similar testing data as in previous example.
After running aggregation task with transaction /POSDW/PDIS new aggregation package has been created.

If you browse total table set at aggregation level you can find corresponding entry.

And more details about recorded and grouped transactions in /POSDW/AGGR01 as used by my task aggregation level is single hierarchy.

Last step for this processing is to run Outbound processing task for aggregations. This is done by transaction /POSDW/ODIS. For this particular Outbound task with badi implementation 3001 Idoc WPUUMS has been created and sent to follow-on system.

Btw, two Idocs were created because Outbound task use aggregation period 11 which is posting data and transactions were recorded with two different dates.
SAP CAR provides two options for aggregation of POS transactions. Simpler solution would be to set up automatic aggregation for processing of tasks that are processed with the single-step procedure. More complex and as well efficient (when number of transactions) is to set up form of aggregates that first stores data in the database and then aggregates are processed by a subsequent step.
Alike simple and complex aggregations are performed by tasks.
- One-Step processing – aggregation is performed in the same task for sending data to follow-on system, means after aggregation the system sends the summarized data within the task processing, for which the aggregation was performed on to the corresponding follow-on system.
- Two-Steps processing – aggregation is split into forming aggregation (one task) and outbound processing (second separate task). POS transactions are in first formatted, cumulated and then aggregates are created and stored in database. All those activates are done in special task with processing type - collective processing that does not have follow-up functions for sending summarized to the corresponding receiving system. As an outcome of first task is aggregate object stored in database. This object is an entry value for second step which is task for sending data, summarized in the form of POS aggregates and updated to the database, to follow-on systems in order to be able to process it further there.
Common configuration for both methods.
Both aggregation methods have few configuration settings that are used in common. At the beginning it's worth to mention that for most of operations, activities you can implement parameters that could be later on used in BADIs to achieve greater flexibility of the solution.
As an entrance for both of types of aggregations is configuration of aggregation period and aggregation method.
Aggregation Period allows more detailed split of POS transactions based on for example period of time. Time unit is not mandatory here as separator, it could be freely defined implementation of BADI: /POSDW/BADI_GET_AGGR_GROUP
Aggregation Method
Aggregation method ZMA1 shows that data for aggregation is split by Sales Item and Material number by standard BADI (/POSDW/COMPRESSION) implementation – 0001. To achieve finer grouping criteria, aggregation period can be taken into account like posting date etc (as described in aggregation period).This ensures that only POS transactions that are in the same aggregation period are aggregated together via Badi implementation (example of method Z001). In my example aggregation is done only with content of transaction and summarization period is not taken into account.
One-step specific configuration
Next step is to create a task for generating data to follow-on system and include grouping.
Start of task is manual as aggregation is executed for multiple POS transactions. Filter for BADI is 0010 – Create Idoc WPUBON. 0010 is simple an implementation of Badi (/POSDW/TASK) that process task. If you would like to aggregate data (one-step) field ‘code for aggregation method’ is where you place previously configured aggregation method. As mentioned before to achieve greater flexibility parameter group might be assigned and used by Badi implementation.
Next part of customization is common for One-step and Two-Steps task processing. Each POS transaction could be assigned to task group.
First task group is defined and then tasks are assigned to it like presented below.
By this assignment we indicate that for transaction ZMT1 all tasks from task group ZTG1 are valid (if task processing is set to including). Additionally for the purpose of aggregation I can set three grouping keys and use them in Badi implementation.
Testing
For the testing purpose I will create (via inbound Idoc) four POS transactions. All will have same transaction type (ZMT1: MJ: Sales1), same shops (as follow-on Idoc is created per store in this Badi implementation) and two different materials. Additionally transactions are registered on two posting dates.
- Transaction 82
- 12/07 - Material MJ1 – 1 PC - 20 PLN
- 12/07 - Material MJ2 – 2PC – 50 PLN
- Transaction 83
- 13/07 - Material MJ1 – 1 PC - 20 PLN
- 13/07 - Material MJ2 – 2PC – 50 PLN
By executing task (where aggregation is applied or not) from transaction: /POSDW/PDIS new Idoc has been created to follow-on system that contains information about aggregated sales.
Two-steps specific configuration
Two-steps aggregation splits process into two phases: aggregation and outbound processing. During first step, task creates aggregate package. The system forms a new aggregate package if no open one exists for the chosen aggregation method. If another aggregate exists with aggregated data records, which has not yet been completed, the system aggregates the data of the POS transactions to be processed in this aggregate. Aggregation package is an input data for second task which is called outbound task. During this task, data is converted to receiving system specific format and is sent to follow-on systems.
Configuration starts with aggregation level.
Table type column describes structure that is used during aggregation processing. Total Table is a database table used for storing summarized information about aggregation. All these dictionary elements can be created by user and later used in aggregation processing. In case of aggregation level 0001 structure used in aggregation processing is /POSDW/TT_AGGR01_1_AGGR_STRUC and summary of aggregations is stored in table /POSDW/AGGR1A.
By default aggregations are stored on single level of aggregation in table /POSDW/AGGR01. Group name RECORD contains the entire record of the actual database table <Root> as an include of structure used for aggregation processing (previous screenshot). Additionally there is a possibility to split data per multiple database table. As it's in case of aggregation level 0002, Tax data is stored in /POSDW/AGGR11 table and discounts in /POSDW/AGGR12. Field name of table describe include from aggregation processing structure (/POSDW/TT_AGGR01_1_AGGR_STRUC) that contains data to be stored.
Last step of the configuration for aggregation levels is to decide how some non-key fields are going to be processed if record already exists, override, add, max or min.
Very useful is SAP Note: 980272 - Implementing tasks for two-step processing, which describes step by step how to create custom structures, tables and configure it.
Aggregation task
Next step is to create aggregation task for two step processing. Generally idea is the same but only few different fields exist.
Type of task needs to be always 1 – Collective processing. Beside of that comparing to previous one-step configuration only aggregation level and aggregation period (this parameter is described in common part of the article) are needed.
Outbound task
This is the last configuration required to be configured. Tasks – Badi (Filter) specifies implementation of Badi to execute operation on previously aggregated data (usually it’s sending data to follow-on system). Because our aggregation task ZAG1 uses different structure then implementation of Badi that process the data (3001 uses /POSDW/TT_AGGR_SALES_W_DETAILS) mapping between structures is required. Table type describes target structure, source structure is in aggregation level and mapping is done by implementation if Badi specified in transfer filter field.
Testing:
For the testing purpose I would like to use similar testing data as in previous example.
After running aggregation task with transaction /POSDW/PDIS new aggregation package has been created.
If you browse total table set at aggregation level you can find corresponding entry.
And more details about recorded and grouped transactions in /POSDW/AGGR01 as used by my task aggregation level is single hierarchy.
Last step for this processing is to run Outbound processing task for aggregations. This is done by transaction /POSDW/ODIS. For this particular Outbound task with badi implementation 3001 Idoc WPUUMS has been created and sent to follow-on system.
Btw, two Idocs were created because Outbound task use aggregation period 11 which is posting data and transactions were recorded with two different dates.
- SAP Managed Tags:
- SAP Customer Activity Repository,
- SAP Point-of-Sale
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP
1 -
API Rules
1 -
CRM
1 -
Custom Key Metrics
1 -
Customer Data
1 -
Determination
1 -
Determinations
1 -
Introduction
1 -
KYMA
1 -
Kyma Functions
1 -
open SAP
1 -
Sales and Service Cloud Version 2
1 -
Sales Cloud v2
1 -
SAP
1 -
SAP Community
1 -
SAP CPQ
1 -
SAP CRM Web UI
1 -
SAP Customer Data Cloud
1 -
SAP Customer Experience
1 -
SAP Integration Suite
1 -
SAP Sales Cloud v2
1 -
SAP Service Cloud v2
1 -
SAP Service Cloud Version 2
1 -
Service Cloud v2
1 -
Validation
1 -
Validations
1
Related Content
- SAP Commerce Cloud Q1 ‘24 Release Highlights in CRM and CX Blogs by SAP
- SAP Customer Checkout 2.0 Feature Pack 19 (Released on 26-MARCH-2024) in CRM and CX Blogs by SAP
- CRM Basic Technical Info for ABAPers in CRM and CX Blogs by Members
- Image is not showing in Interaction Center in CRM/SSF and Formatting is losing in SOIN transaction in CRM and CX Questions
- SAP and SalesForce Custom Integration flows in CRM and CX Questions