

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA 2.0 SPS 03: New Developer Features; Datab...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-11-2018
6:40 PM
In this blog, I would like to introduce you to the new features for the database developer in SAP HANA 2.0 SPS 03. We will focus on the database development topic including Core Data Services, as well as SQLScript.
Given that SAP HANA Dynamic Tiering is correctly installed and running, and extended storage is configured and available, CDS now allows you to partition column entities into both default storage and extended storage as well as fully in extended storage.
For more information on Core Data Services, please see the Core Data Services Reference Guide.
Exception handling in SQLScript is designed to allow you catch general SQL error codes, or even specific ones, but not all SQL error codes are catchable. For example, if you tried to catch SQL error code 146 which is an error for UPDATE NOWAIT failure, you would get an error message saying that the feature is not supported. As of SAP HANA 2.0 SPS03, we’ve added support for defining an exit handler for this specific error code.

We continue to add language elements to SQLScript that simplify the programming model and improve the readability and maintainability of the code. For example, in some cases, you might have a requirement to determine if a value is within a certain range. Of course, you could write this simply as IF VALUE > 0 and VALUE < 100. But in an effort to simplify the code, we now offer the BETWEEN operator to check the value. You also see in the following example the use of the BOOLEAN type for the output parameter which we can set to true or false. This is also a new feature as of SAP HANA 2.0 SPS03.

Another new language feature is the ability to declare variables using the LIKE keyword. For example, if we wanted an intermediate table variable that was exactly like a persistent table or even an intermediate table variable, we can use the LIKE keyword instead of having to define the columns of the variable.

Previously we introduced the ability to exchange scalar values with dynamic SQL, meaning that we could do a SELECT * INTO a variable inside of EXEC or EXECUTE IMMEDIATE statements, and even pass parameters into it as well. We have now extended this capability to include table variables as well, so you can now extract the result sets of SELECT statements into table variables. In this example, I pass in the table name as well as a multiplier which is then used to construct the SELECT statement within dynamic SQL. The multiplier is passed in with the USING keyword. The INTO keyword puts the results of the SELECT into the intermediate table variable LT_RESULTS.


In some cases, we might expect a SELECT INTO statement to fail and not return the scalar value. We can now assure that in those cases, the scalar variables will contain a value by using the DEFAULT keyword.
In a previous support package, we introduced intermediate table operators such as INSERT, UPDATE, and DELETE. In SAP HANA 2.0 SPS03, we have added a new SEARCH operator for enabling efficient search by key-value pairs in table variables. In this example, you can see that I am doing an IF statement, which is searching for a particular PRODUCTID in the LT_PRODUCTS intermediate table variable.

We now support ROW type variables. This gives us the ability to have a collection of scalar variables with different types, very much like a structure in ABAP. This is useful for storing a single row of table data. For example, in the code below, LS_EMPLOYEES is a ROW type, and then I do a SELECT * INTO LS_EMPLOYEES FROM “MD.Products” WHERE EMPLOYEEID = the input parameter. So now LS_EMPLOYEES has all the data of that row, which I can then reference each field of that row, for example LS_EMPLOYEES.SALARYAMOUNT.

In some cases, we need to iterate over a cursor and update the table it is currently pointed to. We use the FOR UPDATE when defining the cursor to acquire a lock on the effected rows. We then use the WHERE CURRENT OF <name_of_cursor> in the UPDATE statement. Keep in mind we have several restrictions associated with the use of this, for example, you currently can not use this for tables which contain associations, or partitioned tables.

In SAP HANA 2.0 SPS02, we introduced the ability to do CREATE OR REPLACE for procedures and functions, but there was a limitation where you could not change the signature. In SAP HANA 2.0 SPS03, we now allow you to make such changes to the signature of the procedure or function when using the CREATE or REPLACE statement.

MapReduce is a programming model which allows easy development of scalable parallel applications which processes large amounts of data. In SAP HANA 2.0 SPS00, we introduced the MAP_MERGE operator which is a specialized version of the MAP_REDUCE operator, a sort of Reducer-less MapReduce. In SAP HANA 2.0 SPS03, we now support the MAP_REDUCE operator. Please note that both MAP_MERGE and MAP_REDUCE operators work only on single node configuration and scale-out support is to be planned for a future release. I’ll try to explain this using a simple use case. For example, lets say you have a table which contains IDs and a column containing string data, this string data consists of letters separated by commas. The requirement is to count the number of strings that contains each character, and we need to count the number of occurrences of each character in the table. Here the “Mapper” function, processes each row of the input table and returns a table for each row processed. When all rows of the input table are processed by the “Mapper”, the output tables are aggregated into a single table(this is exactly what MAP_MERGE operator does).

Now the rows in the aggregated table are grouped by key-columns, which are defined in our code. For each group, we separate key values from the table. We call the group table without key columns, the “value table”. Now we use the “Reducer” function to process each group(or each value table ), which then returns a table or multiple tables containing the STATEMENT_FREQ, and the TOTAL_FREQ. When all groups are processed by the “Reducer” function, the output tables of the “Reducer” are then aggregated into a single table.

If we now look at the code a little closer, we’ve already seen the “Mapper” and “Reducer” functions, lets look at how we use them in conjunction with the MAP_REDUCE operator. In the example below, this is how we would do this calculation described earlier without the use of MAP_REDUCE operator. Here we use cursors and do UNION ALL with “Mapper” and “Reducer” functions. While this works just fine, it does look a little messy, and perhaps it does not perform well due to the use of the cursors.

Below is what the same logic would look like if we would use the MAP_REDUCE operator instead. You will notice it is a lot cleaner, and also hides some of the complexities with managing the groupings and aggregations. You can see that the MAP_REDUCE operator takes 3 inputs, the input table, the “Mapper” and “Reducer” functions, and returns the final result table.

In SAP HANA 2.0 SPS02, we introduced the SQLScript Code Analyzer which initially had 4 rules. We’ve added 5 new rules for the SQLScript Code Analzyer in SAP HANA 2.0 SPS03.
In SAP HANA 2.0 SPS02, we introduced built-in libraries, and we delivered one called SQLSCRIPT_SYNC which contained functions for putting a process to sleep and waking up connections. In SAP HANA 2.0 SPS03, we have added a new library called SQLSCRIPT_STRING which contains several functions for string manipulation, including several functions for splitting strings, splitting strings using regular expressions, and splitting to arrays and tables. We also have several functions for formatting which uses python style formatting. In this example, I’m taking an intermediate table variable and using the FORMAT_TO_TABLE function to transform the data from a multi column table to a single column table which contains the same data as comma delimited data. After that I use the SPLIT function to break it apart again.
We also introduced the SQLSCRIPT_PRINT library which we can use to write out results. This is currently only supported in the hdbsql interface. PRINT_LINE will print out a line as a string to the hdbsql interface, and PRINT_TABLE will parse a table variable into a single string and write to the hdbsql intereface. We do have plans to make this functionality available in the Database Explorer in the future as well.

In SAP HANA 2.0 SPS03, we now allow you to create your own libraries as well, which we call User Defined Libraries, or UDLs. Libraries are a set of related variables, procedures, and function written in SQLscript. The HDI artifact for libraries is .hdblibrary. There are two access modes, public, and private. So you can flag each library member individually as to how you would like it to be exposed. So if you do not want a procedure to be callable from outside of the library, you would use the private keyword.

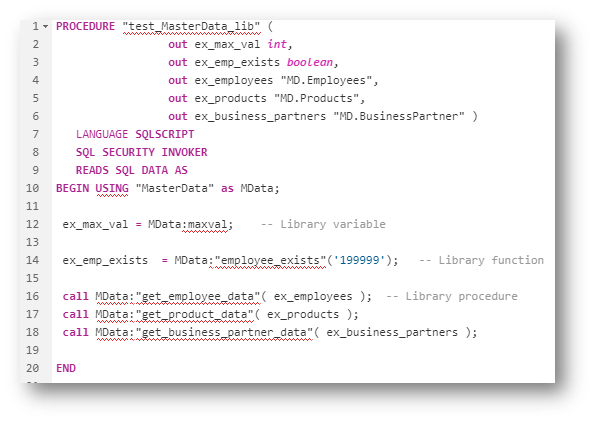
Libraries are only consumable from within SQLScript, and can not be used straightaway in any SQL statement or CALL statement directly. Currently, you must use them in a procedure or anonymous block. We need to use the USING keyword in the BEGIN statement to declare the use of the library, as you can see in the example below. Here I am declaring MasterData as the library I’m using and assigning an alias called MData. We can then reference the variables, functions, and procedures within our SQLScript code using the Alias:<name of procedure/function/variable> notation.
SQLScript Plan Profiler is a new performance analysis tool, mainly designed from the perspective of Stored Procedures and Functions. When the SQLScript Plan Profiler is enabled, results such as start and end time, cpu and wait time, etc. are generated per call statement in a tabular format. The profiling results can be found in the new monitoring view M_SQLSCRIPT_PLAN_PROFILER_RESULTS. We use the ALTER SYSTEM statement to work with the profiler. Below is the syntax.

Procedure result cache is a server-wide in-memory cache that caches the output arguments of procedure calls using the input arguments as keys. Previously, we introduce this same concept for scalar functions, where if we had a deterministic function, meaning that the results would be the same for the same input parameters for every call, the results would then be cache. We now introduce the same for procedures as well. We can flag our procedures as DETERMINISTIC in the same way.

Again, in SAP HANA 2.0 SPS02 we introduce the SQLScript Code Analyzer, but the only way to use it was to call the procedures associated with it via the SQL Console. Now in SAP HANA 2.0 SPS03, we have integrated the SQLScript Code Analyzer into the Database Explorer view in the SAP Web IDE for SAP HANA. You can now right-click on a procedure in the Database Explorer, and choose “Analyze SQLScript code” and it will bring the results in a tab on the right.

Finally, you might notice a different look and feel to the SQLscript Debugger in SAP HANA 2.0 SPS03. We have integrated it with the other debuggers in the SAP Web IDE for SAP HANA. We’ve also added the ability to step into and out of procedure calls and scalar function assignment statements.

For more information on SQLScript, please see the SQLScript Reference Guide.
Core Data Services(CDS)
Extended Table & Multi-Store Table Support
Given that SAP HANA Dynamic Tiering is correctly installed and running, and extended storage is configured and available, CDS now allows you to partition column entities into both default storage and extended storage as well as fully in extended storage.
For more information on Core Data Services, please see the Core Data Services Reference Guide.
SQLScript
Exit Handler for UPDATE NOWAIT
Exception handling in SQLScript is designed to allow you catch general SQL error codes, or even specific ones, but not all SQL error codes are catchable. For example, if you tried to catch SQL error code 146 which is an error for UPDATE NOWAIT failure, you would get an error message saying that the feature is not supported. As of SAP HANA 2.0 SPS03, we’ve added support for defining an exit handler for this specific error code.
BETWEEN Operator & Boolean Type
We continue to add language elements to SQLScript that simplify the programming model and improve the readability and maintainability of the code. For example, in some cases, you might have a requirement to determine if a value is within a certain range. Of course, you could write this simply as IF VALUE > 0 and VALUE < 100. But in an effort to simplify the code, we now offer the BETWEEN operator to check the value. You also see in the following example the use of the BOOLEAN type for the output parameter which we can set to true or false. This is also a new feature as of SAP HANA 2.0 SPS03.
Variable Declaration using LIKE
Another new language feature is the ability to declare variables using the LIKE keyword. For example, if we wanted an intermediate table variable that was exactly like a persistent table or even an intermediate table variable, we can use the LIKE keyword instead of having to define the columns of the variable.
Support Table Variables with Dynamic SQL
Previously we introduced the ability to exchange scalar values with dynamic SQL, meaning that we could do a SELECT * INTO a variable inside of EXEC or EXECUTE IMMEDIATE statements, and even pass parameters into it as well. We have now extended this capability to include table variables as well, so you can now extract the result sets of SELECT statements into table variables. In this example, I pass in the table name as well as a multiplier which is then used to construct the SELECT statement within dynamic SQL. The multiplier is passed in with the USING keyword. The INTO keyword puts the results of the SELECT into the intermediate table variable LT_RESULTS.
SELECT INTO with Default Values
In some cases, we might expect a SELECT INTO statement to fail and not return the scalar value. We can now assure that in those cases, the scalar variables will contain a value by using the DEFAULT keyword.
SEARCH Operator for Table Variables
In a previous support package, we introduced intermediate table operators such as INSERT, UPDATE, and DELETE. In SAP HANA 2.0 SPS03, we have added a new SEARCH operator for enabling efficient search by key-value pairs in table variables. In this example, you can see that I am doing an IF statement, which is searching for a particular PRODUCTID in the LT_PRODUCTS intermediate table variable.
ROW Type
We now support ROW type variables. This gives us the ability to have a collection of scalar variables with different types, very much like a structure in ABAP. This is useful for storing a single row of table data. For example, in the code below, LS_EMPLOYEES is a ROW type, and then I do a SELECT * INTO LS_EMPLOYEES FROM “MD.Products” WHERE EMPLOYEEID = the input parameter. So now LS_EMPLOYEES has all the data of that row, which I can then reference each field of that row, for example LS_EMPLOYEES.SALARYAMOUNT.
Updatable Cursor
In some cases, we need to iterate over a cursor and update the table it is currently pointed to. We use the FOR UPDATE when defining the cursor to acquire a lock on the effected rows. We then use the WHERE CURRENT OF <name_of_cursor> in the UPDATE statement. Keep in mind we have several restrictions associated with the use of this, for example, you currently can not use this for tables which contain associations, or partitioned tables.
CREATE OR REPLACE Enhancements
In SAP HANA 2.0 SPS02, we introduced the ability to do CREATE OR REPLACE for procedures and functions, but there was a limitation where you could not change the signature. In SAP HANA 2.0 SPS03, we now allow you to make such changes to the signature of the procedure or function when using the CREATE or REPLACE statement.
MAP_REDUCE Operator
MapReduce is a programming model which allows easy development of scalable parallel applications which processes large amounts of data. In SAP HANA 2.0 SPS00, we introduced the MAP_MERGE operator which is a specialized version of the MAP_REDUCE operator, a sort of Reducer-less MapReduce. In SAP HANA 2.0 SPS03, we now support the MAP_REDUCE operator. Please note that both MAP_MERGE and MAP_REDUCE operators work only on single node configuration and scale-out support is to be planned for a future release. I’ll try to explain this using a simple use case. For example, lets say you have a table which contains IDs and a column containing string data, this string data consists of letters separated by commas. The requirement is to count the number of strings that contains each character, and we need to count the number of occurrences of each character in the table. Here the “Mapper” function, processes each row of the input table and returns a table for each row processed. When all rows of the input table are processed by the “Mapper”, the output tables are aggregated into a single table(this is exactly what MAP_MERGE operator does).
Now the rows in the aggregated table are grouped by key-columns, which are defined in our code. For each group, we separate key values from the table. We call the group table without key columns, the “value table”. Now we use the “Reducer” function to process each group(or each value table ), which then returns a table or multiple tables containing the STATEMENT_FREQ, and the TOTAL_FREQ. When all groups are processed by the “Reducer” function, the output tables of the “Reducer” are then aggregated into a single table.
If we now look at the code a little closer, we’ve already seen the “Mapper” and “Reducer” functions, lets look at how we use them in conjunction with the MAP_REDUCE operator. In the example below, this is how we would do this calculation described earlier without the use of MAP_REDUCE operator. Here we use cursors and do UNION ALL with “Mapper” and “Reducer” functions. While this works just fine, it does look a little messy, and perhaps it does not perform well due to the use of the cursors.
Below is what the same logic would look like if we would use the MAP_REDUCE operator instead. You will notice it is a lot cleaner, and also hides some of the complexities with managing the groupings and aggregations. You can see that the MAP_REDUCE operator takes 3 inputs, the input table, the “Mapper” and “Reducer” functions, and returns the final result table.
SQLScript Code Analyzer Rules
In SAP HANA 2.0 SPS02, we introduced the SQLScript Code Analyzer which initially had 4 rules. We’ve added 5 new rules for the SQLScript Code Analzyer in SAP HANA 2.0 SPS03.
- USE_OF_UNASSIGNED_SCALAR_VARIABLE- detects variables which are used but were never assigned explicitly. Those variables will still have their default value when used, which might be undefined. It is recommended to assign a default value (can be NULL) to be sure that you get the intended value when you read from the variable.
- USE_OF_CE_FUNCTIONS - checks whether Calculation Engine Plan Operators (CE functions) are used. Since they make optimization more difficult and lead to performance penalties, they should be avoided.
- DML_STATEMENTS_IN_LOOPS - detects the following DML statements inside of loops: INSERT, UPDATE, DELETE, REPLACE/UPSERT. Sometimes it is possible to rewrite the loop and use a single DML statement to improve performance instead.
- USE_OF_SELECT_IN SCALAR_UDF – detects if SELECT is used within a scalar UDF which can lower the performance. If table operations are really needed, procedures or Table UDFs should be used instead.
- COMMIT_OR_ROLLBACK_IN_DYNAMIC_SQL - detects dynamic SQL which use the COMMIT or ROLLBACK statement. Since COMMIT and ROLLBACK can be used directly in SQLScript without the need of dynamic SQL, it is recommended to use COMMIT and ROLLBACK directly.
SQLScript String Built-In Library
In SAP HANA 2.0 SPS02, we introduced built-in libraries, and we delivered one called SQLSCRIPT_SYNC which contained functions for putting a process to sleep and waking up connections. In SAP HANA 2.0 SPS03, we have added a new library called SQLSCRIPT_STRING which contains several functions for string manipulation, including several functions for splitting strings, splitting strings using regular expressions, and splitting to arrays and tables. We also have several functions for formatting which uses python style formatting. In this example, I’m taking an intermediate table variable and using the FORMAT_TO_TABLE function to transform the data from a multi column table to a single column table which contains the same data as comma delimited data. After that I use the SPLIT function to break it apart again.
SQLScript Print Built-In Library
We also introduced the SQLSCRIPT_PRINT library which we can use to write out results. This is currently only supported in the hdbsql interface. PRINT_LINE will print out a line as a string to the hdbsql interface, and PRINT_TABLE will parse a table variable into a single string and write to the hdbsql intereface. We do have plans to make this functionality available in the Database Explorer in the future as well.
SQLScript User-Defined Libraries
In SAP HANA 2.0 SPS03, we now allow you to create your own libraries as well, which we call User Defined Libraries, or UDLs. Libraries are a set of related variables, procedures, and function written in SQLscript. The HDI artifact for libraries is .hdblibrary. There are two access modes, public, and private. So you can flag each library member individually as to how you would like it to be exposed. So if you do not want a procedure to be callable from outside of the library, you would use the private keyword.
Libraries are only consumable from within SQLScript, and can not be used straightaway in any SQL statement or CALL statement directly. Currently, you must use them in a procedure or anonymous block. We need to use the USING keyword in the BEGIN statement to declare the use of the library, as you can see in the example below. Here I am declaring MasterData as the library I’m using and assigning an alias called MData. We can then reference the variables, functions, and procedures within our SQLScript code using the Alias:<name of procedure/function/variable> notation.
SQLScript Plan Profiler
SQLScript Plan Profiler is a new performance analysis tool, mainly designed from the perspective of Stored Procedures and Functions. When the SQLScript Plan Profiler is enabled, results such as start and end time, cpu and wait time, etc. are generated per call statement in a tabular format. The profiling results can be found in the new monitoring view M_SQLSCRIPT_PLAN_PROFILER_RESULTS. We use the ALTER SYSTEM statement to work with the profiler. Below is the syntax.
ALTER SYSTEM <command> SQLSCRIPT PLAN PROFILER [<filter>]
<command> := START | STOP | CLEAR
<filter> := FOR SESSION <session_id> | FOR PROCEDURE <procedure_name>Procedure Result Cache
Procedure result cache is a server-wide in-memory cache that caches the output arguments of procedure calls using the input arguments as keys. Previously, we introduce this same concept for scalar functions, where if we had a deterministic function, meaning that the results would be the same for the same input parameters for every call, the results would then be cache. We now introduce the same for procedures as well. We can flag our procedures as DETERMINISTIC in the same way.
SQLScript Code Analzyer in Database Explorer
Again, in SAP HANA 2.0 SPS02 we introduce the SQLScript Code Analyzer, but the only way to use it was to call the procedures associated with it via the SQL Console. Now in SAP HANA 2.0 SPS03, we have integrated the SQLScript Code Analyzer into the Database Explorer view in the SAP Web IDE for SAP HANA. You can now right-click on a procedure in the Database Explorer, and choose “Analyze SQLScript code” and it will bring the results in a tab on the right.
SQLScript Debugger Enhancements
Finally, you might notice a different look and feel to the SQLscript Debugger in SAP HANA 2.0 SPS03. We have integrated it with the other debuggers in the SAP Web IDE for SAP HANA. We’ve also added the ability to step into and out of procedure calls and scalar function assignment statements.
For more information on SQLScript, please see the SQLScript Reference Guide.
- SAP Managed Tags:
- SAP HANA,
- SAP HANA, express edition,
- SAP HANA, platform edition
Labels:
7 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
327 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Developer extendibility for custom table and publish oDATA in Technology Q&A
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- Building custom app at SAP S/4 public cloud in Technology Q&A
- SAP S/4HANA Structure for Developer in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 4 |