
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Custom Dictionaries - SAP HANA Text Analysis
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Esha1
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-15-2018
2:22 AM
In this blog, I’ll discuss how to create custom dictionaries in SAP HANA. To implement certain custom use cases, customers have to implement their own dictionaries for performing Text Analysis.
Use Case: A company has ‘n’ number of products in product portfolio which are not covered completely by standard configuration. In such case, they can create a custom dictionary with an entity category Product and add all the products names in the portfolio.
SAP HANA is shipped with several predefined, standard text analysis configurations. Such configurations are available in “sap.hana.ta.config” repository package as shown in Figure 1. For more details on standard Text Analysis Configurations, refer to the blog [ https://blogs.sap.com/2018/02/01/sap-hana-text-analysis-3/ ].

Figure 1: Standard Text Analysis Configurations
Steps involved in the implementation of Custom dictionaries
***********************************************************************************
Step 1: Create Custom Dictionary
Dictionary contains a number of user-defined entity types, each of which further contain any number of entities of standard and variant types. In simple terms, dictionary stores name variations in a structured manner to be accessible through the extraction process. Dictionaries are language-independent, and can be created for all 34 supported languages.
Dictionary files must be in XML format and follow the specified syntax below:
Three parameters that need to be specified while creating the dictionary:
Figure 2 below shows the custom dictionary created for performing Custom Text Analysis.
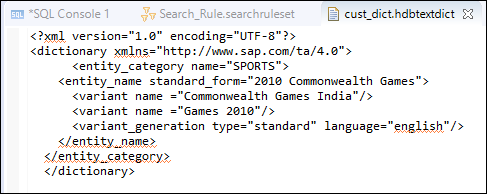
Figure2: Custom Dictionary File
***********************************************************************************
Step 2: Update the Configuration File or create a Custom Configuration File specifying Custom Dictionary
Custom Text Analysis Configurations can be used to perform custom text analysis using custom text analysis dictionaries and extraction rule set. Create your own custom text analysis configuration files with “.hdbtextconfig” file extension. Configuration files are also in XML format.
Below is a Piece of Code that shows the sequence of Text Analysis Steps in XML Format.
In this configuration section, following analyzers are available:
In our example, custom text analysis configuration is managed within SAP HANA repository. Figure 3 below shows the property sections highlighted with enabled the custom dictionaries, and inclusion of custom dictionary path.

Figure 3: Custom Configuration File
Dictionary is created in “sap.hana.ta.dict” repository package and Text Analysis configuration is created in “sap.hana.ta.config” repository package as seen in Figure 4 below.

Figure 4: Repository Path
*************************************************************************************
This custom form is used to extract basic entities from the text and entities of interest including people, places, firms, URLs, and other common terms.
Figure 5 below shows the rule as Entity Extraction in TA_RULE column with new category names and available basic entities.

Figure5: Custom Configuration – Entity Extraction
In summary, we covered detailed steps on how to create and implement custom dictionaries in SAP HANA for performing Text Analysis in certain custom use cases.
Use Case: A company has ‘n’ number of products in product portfolio which are not covered completely by standard configuration. In such case, they can create a custom dictionary with an entity category Product and add all the products names in the portfolio.
SAP HANA is shipped with several predefined, standard text analysis configurations. Such configurations are available in “sap.hana.ta.config” repository package as shown in Figure 1. For more details on standard Text Analysis Configurations, refer to the blog [ https://blogs.sap.com/2018/02/01/sap-hana-text-analysis-3/ ].
Figure 1: Standard Text Analysis Configurations
Steps involved in the implementation of Custom dictionaries
- Create a Custom dictionary
- Update the Configuration File or create a Custom Configuration File specifying Custom Dictionary
***********************************************************************************
Step 1: Create Custom Dictionary
Dictionary contains a number of user-defined entity types, each of which further contain any number of entities of standard and variant types. In simple terms, dictionary stores name variations in a structured manner to be accessible through the extraction process. Dictionaries are language-independent, and can be created for all 34 supported languages.
Dictionary files must be in XML format and follow the specified syntax below:
<?xml version="1.0" encoding="UTF-8" ?>
<dictionary xmlns="http://www.sap.com/ta/4.0">
<entity_category name=“<Category_Name">
<entity_name standard_form=“<Entity_Name">
<variant name=“Variant_Name"/>
</entity_name>
</entity_category> ...
</dictionary>
Three parameters that need to be specified while creating the dictionary:
- Category name
- Standard form of an entity: This is complete or precise form of a given entity
- Variant names for an entity: This is less standard form of a given entity
Figure 2 below shows the custom dictionary created for performing Custom Text Analysis.
Figure2: Custom Dictionary File
***********************************************************************************
Step 2: Update the Configuration File or create a Custom Configuration File specifying Custom Dictionary
Custom Text Analysis Configurations can be used to perform custom text analysis using custom text analysis dictionaries and extraction rule set. Create your own custom text analysis configuration files with “.hdbtextconfig” file extension. Configuration files are also in XML format.
Below is a Piece of Code that shows the sequence of Text Analysis Steps in XML Format.
<configuration name=“…AggregateAnalyzer.Aggregator">
<property name="Analyzers" type="string-list">
<string-list-value>…FormatConversionAnalyzer.FC</string-list-value>
<string-list-value>…StructureAnalyzer.SA</string-list-value>
<string-list-value>…LinguisticAnalyzer.LX</string-list-value>
<string-list-value>…ExtractionAnalyzer.TF</string-list-value>
<string-list-value>….GrammaticalRoleAnalyzer.GRA</string-list-value>
</property> </configuration>
In this configuration section, following analyzers are available:
- “FormatConversionAnalyzer” is used for performing document conversion
- “StructureAnalyzer” is used for de-tagging and language detection. This performs mark-up removal, whitespace normalization and language detection
- “LinguisticAnalyzer” is used to perform Linguistic Analysis which includes tokenization, identification of word base forms (stems) and tagging part of speech
- “ExtractionAnalyzer” is an optional parameter which is used for entity/relation extraction
- „GrammaticalRoleAnalyzer“ is also an optional parameter used to identify functional relationships between elements
In our example, custom text analysis configuration is managed within SAP HANA repository. Figure 3 below shows the property sections highlighted with enabled the custom dictionaries, and inclusion of custom dictionary path.
Figure 3: Custom Configuration File
Dictionary is created in “sap.hana.ta.dict” repository package and Text Analysis configuration is created in “sap.hana.ta.config” repository package as seen in Figure 4 below.
Figure 4: Repository Path
*************************************************************************************
This custom form is used to extract basic entities from the text and entities of interest including people, places, firms, URLs, and other common terms.
CREATE COLUMN TABLE "EXT_CORE"
( ID INTEGER PRIMARY KEY,
STRING NVARCHAR(200) );
INSERT INTO "EXT_CORE" VALUES (1, 'Ruby likes working at SAP');
INSERT INTO "EXT_CORE" VALUES (2, 'Rohan dislikes soccer');
INSERT INTO "EXT_CORE" VALUES (3, 'Rohan really likes football');
INSERT INTO "EXT_CORE" VALUES (4, 'Australia won 74 Gold in Commonwealth Games India');
INSERT INTO "EXT_CORE" VALUES (5, 'India won 38 Gold in Games 2010');
CREATE FULLTEXT INDEX EXT_CORE_INDEX ON "EXT_CORE" ("STRING")
CONFIGURATION 'sap.hana.ta.config::Cust_Extraction_Core'
TEXT ANALYSIS ON;
SELECT * FROM "$TA_EXT_CORE_INDEX"
Figure 5 below shows the rule as Entity Extraction in TA_RULE column with new category names and available basic entities.
Figure5: Custom Configuration – Entity Extraction
In summary, we covered detailed steps on how to create and implement custom dictionaries in SAP HANA for performing Text Analysis in certain custom use cases.
- SAP Managed Tags:
- SAP HANA
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
178 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
416 -
Workload Fluctuations
1
Related Content
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Capture Your Own Workload Statistics in the ABAP Environment in the Cloud in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 30 | |
| 23 | |
| 10 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |