
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Spring Boot Applications in SAP Cloud Platform: Th...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
vadimklimov
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-13-2018
9:39 PM
Intro
Principles of reactive programming model, as opposite to classic imperative, have been defined a while ago and written down in Reactive Manifesto. Major shift in paradigm is implementation of non-blocking (asynchronous) applications and their components, that are based on concept of components reacting to event streams. Reacting to the event / stream instead of calling blocking functions and waiting until they complete their work and return control to the caller function, improves performance and throughput of the entire application. It shall be noted that usage of only few reactive components within the application that relies on other major and blocking components is unlikely to bring significant improvement, as reactive nature of upstream components will be neutralized by blocking nature of downstream components – for example, implementation of reactive non-blocking principles in the API or service layer will not have desired effect for the entire application, if database layer that is queried by corresponding requests, doesn’t support reactive model and uses classic blocking principles when processing database requests. It is also important to ensure that runtime where application is executed, is also compliant to reactive model and supports it.
In Java world, significant milestone in moving towards reactive applications was release of Java 8 that introduced Streams API and that became foundation for several libraries which enable development of reactive applications – such as RxJava and Project Reactor. Going further, Java 9 introduced Reactive Streams / Flows API, embedding this functionality into standard JDK. Popular Java frameworks were also extended with support for reactive applications development – for example, Spring 5 (released to general availability in September 2017) and, correspondingly, Spring Boot 2.0 (released to general availability in March 2018). New runtime environments / servers have been provided as well to support fully reactive, non-blocking streams for deployed applications – such as Netty and Undertow.
Commonly, reactive programming is associated with functional programming paradigm which is based on declarative programming, although in fact, this is not the only approach available when developing reactive applications – in this blog, I would like to draw attention to an alternative approach, where imperative programming paradigm can be employed to migrate traditional thread blocking application to reactive non-blocking one, thanks to corresponding framework wrappers.
Why would we want to assess alternative options if functional reactive streams programming is already available and natively supported in recent Java release? One of major reasons is related to potential migration efforts – in complex legacy applications, switching programming paradigm, even if technically feasible, is resource consuming and can turn to be not worth efforts that need to be invested to make this migration happen reliably and ensure further support of the migrated application.
With these arguments and motivation, let’s get to technical aspects. Application that I will use in the demo throughout the blog, is Java Spring Boot application deployed to Cloud Foundry environment of SCP. Application exposes REST API that can be used to query and retrieve data persisted in MongoDB repository. Spring Boot 2.0 (which is based on Spring 5 framework) includes modules to support reactive stack, as well as more traditional and commonly used modules available in earlier releases of Spring framework. Postman will be used to consume APIs.
Development of involved Spring Boot application has been carried in Eclipse IDE extended with Spring related plugins, dependencies management and build has been conducted using Gradle.
Application’s source code and Gradle build script can be found in GitHub repository.
Baseline version of the application: development
At the beginning we develop basic Spring Boot application using traditional concepts – this is going to be our baseline version of the application.
Dependencies that are required by the developed application:
- Spring Web MVC module (artefact ID 'spring-boot-starter-web' of group ID 'org.springframework.boot') – to enable exposure of REST APIs,
- Spring Cloud Connectors (artifact IDs 'spring-cloud-spring-service-connector' and 'spring-cloud-cloudfoundry-connector' of group ID 'org.springframework.cloud') – to enable integration with cloud provided services such as MongoDB service,
- Spring Data MongoDB module (artifact ID 'spring-boot-starter-data-mongodb' of group ID 'org.springframework.boot') – to enable integration with MongoDB database.
I also make use of Spring Developer Tools (artifact ID 'spring-boot-devtools' of group ID 'org.springframework.boot') to facilitate development and local testing of the developed application.
Tomcat is used as a servlet container for the application.
Below is application’s main class:

Controller that implements API layer - handlers for two API methods: query for specific document by its unique identifier (query can return at most single document) and query for all documents by one of their non-unique attributes (query can return list of documents):

MongoDB repository definition interface:

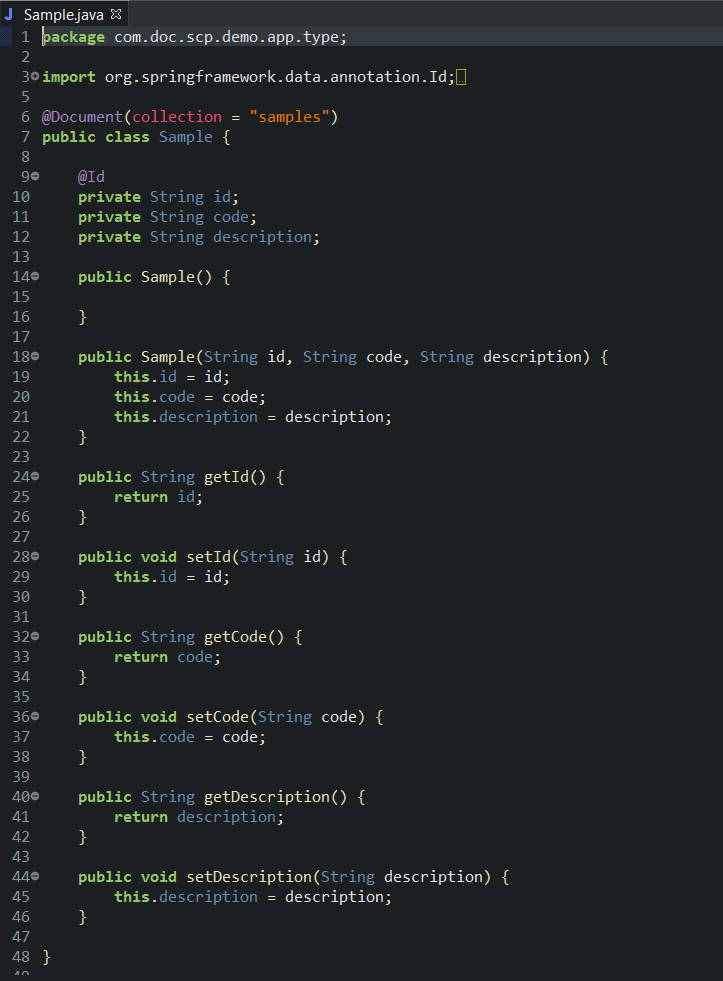
Entity type / MongoDB document type definition class:
Cloud Connector configuration class that scans for all relevant cloud provisioned services available for the application at runtime:

Baseline version of the application: deployment and test
After development phase had been completed, the application has been assembled into JAR file and deployed generated JAR file to Cloud Foundry environment. Earlier created MongoDB service instance to which some documents had been inserted, was bound to the deployed application.
In sake of demonstration, I use Postman to consume the exposed API by sending HTTP GET request to the application:

Application’s log retrieved from Cloud Foundry space, indicates the issued request handling:

Reactive version of the application: development
We are now done with the baseline version of the application development and checking – now it is time to develop another Spring Boot application to fulfil exactly same functional requirements and implement same logic – but this time, we replace all major thread blocking components with their reactive analogues.
Dependencies that are required by the developed application:
- Spring Web Reactive module (artifact ID 'spring-boot-starter-webflux' of group ID 'org.springframework.boot') – to enable exposure of REST APIs using reactive model. This module replaces earlier used Spring Web MVC module,
- Spring Cloud Connectors (artifact IDs 'spring-cloud-spring-service-connector' and 'spring-cloud-cloudfoundry-connector' of group ID 'org.springframework.cloud') – to enable integration with cloud provided services such as MongoDB service. This is same module as the one used earlier,
- Spring Data MongoDB Reactive module (artifact ID 'spring-boot-starter-data-mongodb-reactive' of group ID 'org.springframework.boot') – to enable integration with MongoDB database using reactive model. This module replaces earlier used Spring Data MongoDB module.
Spring Developer Tools are used in this application, too.
Together with enablement of reactive ready modules for the developed application, underlying runtime is replaced to meet reactive streaming requirements – instead of earlier used Tomcat, we go ahead with Netty, which is one of non-servlet runtimes for reactive applications,
Now let’s focus on changes that had to be applied to application’s implementation in order to migrate it to reactive model.
First of all, it is necessary to add additional annotation in application’s main class – '@EnableReactiveMongoRepositories' – to introduce usage of reactive MongoDB repositories (which, in its turn, implies usage of reactive MongoDB driver when accessing MongoDB repository):

Besides this annotation, it is also required to adjust definition of MongoDB repository: instead of earlier used interface MongoRepository, it now has to inherit from corresponding reactive counterpart – ReactiveCrudRepository. Note that definition of methods for querying documents by their attributes also slightly changes in part of their return types in order to comply to reactive types (Flux and Mono). In this particular example, I use Flux return type as this is reactive counterpart for earlier used List:

Another adjustment that has to be conducted, is in the controller. Change has same background as the one mentioned in repository definition above – accommodation of return types of corresponding controller methods that handle respective exposed API methods in such a way that they comply to reactive model – namely, Flux, if the API method handler can return multiple entities / documents, and Mono, if the API method handler can return at most up to one single entity / document. Hence, handler for querying for a specific unique document by its identifier gets changed to return objects of type Mono, and handler for querying for all matching documents by their non-unique attribute gets changed to return objects of type Flux:

That’s it. As it can be seen, migration of the basic application from traditional model to reactive model in this simplistic case was smooth and didn’t make the developer to step outside of traditional Spring development and explicitly switch to another programming paradigm, such as functional programming. We used annotated controllers when developing API layer, made minor amendments in some relevant components to enable reactive interaction with MongoDB, used reactive types to wrap entity types, made few adjustments in dependencies to make use of respective Spring components and reactive enabled driver to MongoDB – and that was all we did so far.
Reactive version of the application: deployment and startup (failure)
We are now ready to assemble application and give a try to deploy and run it in Cloud Foundry environment following similar steps to those used earlier for the baseline version of the application. Assembly and deployment succeeded, but when starting the application, startup process completed with errors due to an exception caused by application’s failure to establish connection to MongoDB repository:

It shall be noted that during deployment, the same instance of MongoDB service was bound to the application, none of application properties or cloud connector configuration have been changed in reactive version of the application compared to its baseline version. Surprisingly, the application now attempts to establish connection to phantom locally hosted MongoDB repository (which for sure, doesn’t exist in cloud environment) instead of connecting to the bound MongoDB service instance. As it can be seen from the provided startup log, application’s MongoDB driver was initially able to recognize location of bound MongoDB service instance, but for some reason it didn’t use correct connection parameters and replaced them with connection string to localhost. Materials on this and similar topics suggest that there are still some issues that have to be addressed and fixed by corresponding migrated framework modules, Spring Data MongoDB Reactive module being one of them when used in Cloud Foundry environment.
Reactive version of the application: deployment and startup (workaround), test
To overcome this issue in current environment and using available modules, it is now time for workarounds. One of them is to explicitly define connectivity parameters for the bound instance of MongoDB service in application properties.
Firstly, it is necessary to retrieve MongoDB instance connection parameters – this can be done using administration cockpit and navigating to details of MongoDB service instance. Note that the required information includes sensitive data – such as user name and password used during authentication procedure when accessing respective MongoDB service instance – hence, appropriate security controls shall be applied. Below example is illustrated in plain text and is based on temporarily created MongoDB service instance in demo purposes only. Searched information is MongoDB database connection string that shall hold value in format 'mongodb://username:password@host:port/database':

Next, the obtained MongoDB connection string shall be maintained in the developed application properties. In this demo, I use a single property 'spring.data.mongodb.uri' to specify the entire connection string – alternatively, combination of corresponding individual properties 'spring.data.mongodb.*' that specify MongoDB host, port, database, user and password can be used. Not to distract attention from the main subject of this blog, I maintain it directly in properties file ('application.properties') of the reactive version of the application:

In production ready developments, this kind of configuration has to be externalized and be environment specific to achieve better flexibility and maintainability of the application.
After this is done, the application is redeployed and restarted – and this time, startup process succeeds and connection to the bound MongoDB service instance is established with no errors:

We can now test this application by consuming the exposed API using Postman:

Corresponding entry in application’s log indicates the issued request handling:

Runtime analysis
By now, deployment to Cloud Foundry environment and end to end demonstration of a presented scenario have been completed – but we haven’t yet looked under the hood of the application at its runtime, though this outlook would illustrate fundamental difference between traditional and reactive processing of sample requests. Although we haven’t performed sophisticated and complex migration activities from development perspective, we caused significant change to behaviour of the application at its runtime – thanks to built-in capabilities of Spring 5 / Spring Boot 2.0 that allow usage of imperative programming and annotation driven configuration when developing reactive applications and that enable transparent handling of reactive streams which happens behind the scenes. Let’s gain insight into application runtime in general and handling and processing of the request by such application in particular. For this, I’m going to use Eclipse IDE with Java profiler plugin to profile locally running application – that is the same application as described above, but executed as standalone Spring application that communicates with locally running instance of MongoDB. Performance hotspot profiling will allow us to look into application threads and method calls that were performed in context of each of them.
In the first instance, let’s profile API request processed by baseline version of the application. From a list of runnable threads, it can be noted that there is one HTTP thread ('http-nio-8080-exec-1') that consumed most of CPU time (343 ms), and this is the thread that handled the request and executed all underlying logic:

Methods invoked within this thread, include execution of controller logic, as well as thread blocking querying of MongoDB repository:

Next, let’s profile the same API request processed by reactive version of the application. From a list of runnable threads, we can immediately notice difference compared to threads used in baseline version of the application: instead of earlier observed single HTTP thread that processed the entire API request and occupied the most of CPU time, we now can see two threads that contributed to CPU time consumption: HTTP thread ('reactor-http-nio-3') consumed much less CPU time (only 15,6 ms), and it is now accompanied with the other thread ('nioEventLoopGroup-2-2') – threading used in event-loop architecture implemented in Netty framework used by Spring Web Reactive module, which consumed significantly more CPU time (171 ms):

Methods invoked within HTTP thread, include execution of controller logic, but this thread is not blocked by querying MongoDB repository – resource consuming querying is executed within a dedicated separate thread. Exploration of invoked methods of both highlighted threads provides clear evidence of usage of reactive principles – in particular, usage of observable emitter (publisher) and observer (subscriber) entities:


This an is important observation: as it has been described above, we didn’t explicitly use Reactive Streams API when migrating traditional application to reactive, but framework did this for us, which is useful functionality to be aware of when developing Spring Boot applications in general and reactive applications in particular.
- SAP Managed Tags:
- Java,
- SAP Business Technology Platform
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
API security
1 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
Azure API Center
1 -
Azure API Management
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Defender
1 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
GraphQL
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
2 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP API Management
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
2 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Demystifying the Common Super Domain for SAP Mobile Start in Technology Blogs by SAP
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- SAP BTP, Kyma Runtime internally available on SAP Converged Cloud in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 5 in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 |