(To be honest, I quickly put my notes together into a more structured form. So please, don't expect a sophisticated text)
On 27th of February, Neo4j, the company behind the popular graph database with the same name, hosted their GraphTour event in Berlin. The opening keynote of both the CEO and the Director of Product Management for Neo4j Cloud was refreshing with a lot of charm and passion.
During the conference, it was stated that the growth of graph databases outperforms every other type of db and that >50% of enterprise already use a graph db in production - a number that also surprised them. The advantage of graph dbs really kicks in when the dataset is highly connected as can be seen in the following two images.


SQL Query (left) and equivalent in Cypher (right; Neo4j's own query language). When they talked about who supports the Cypher language, also SAP Hana showed up 😉
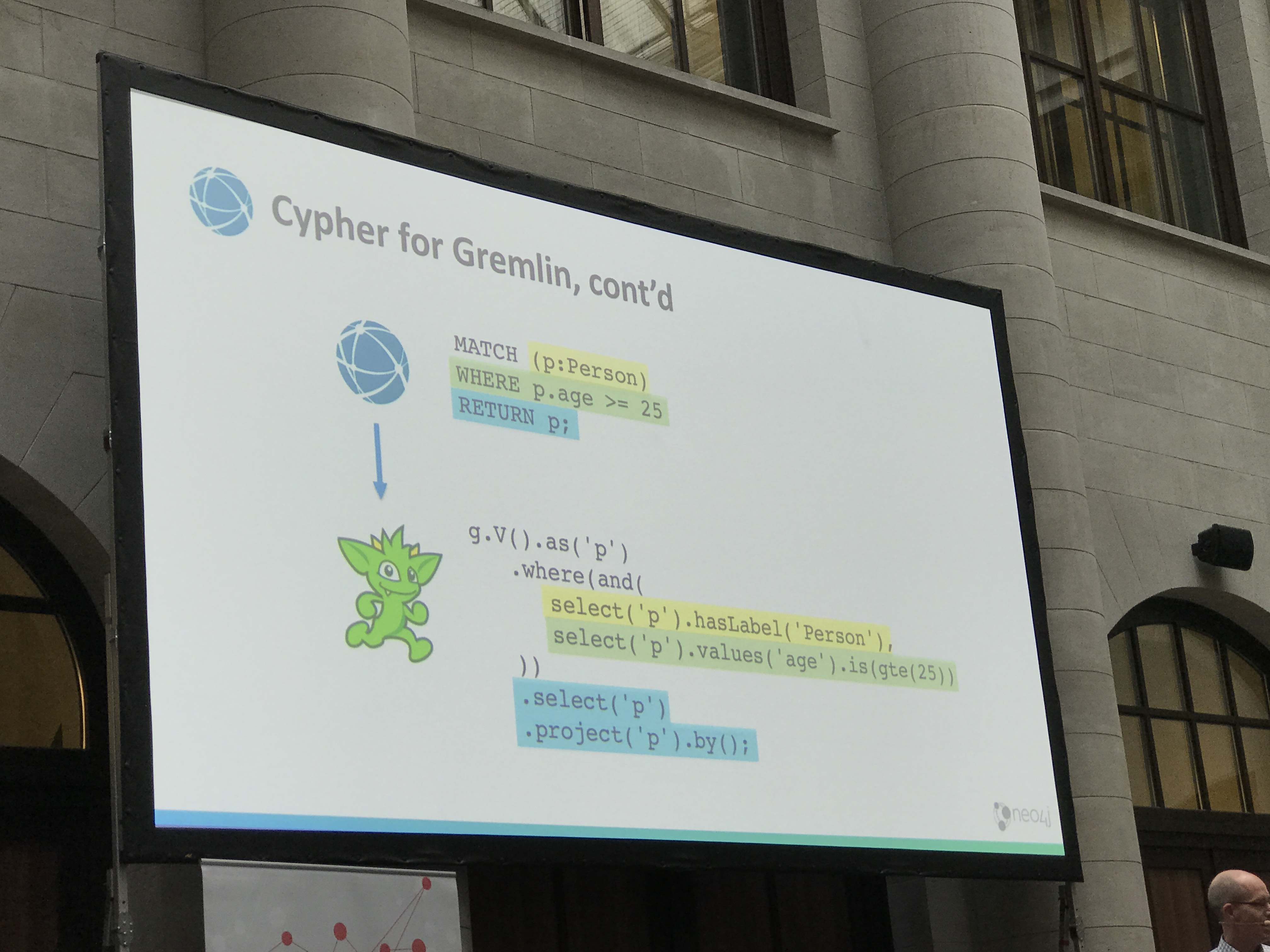
During the conference, Neo4j announced their Cypher for Gremlin plugin. It enables others to write Cypher queries and execute them on Gremlin-enabled dbs. Gremlin is a query language based on the Apache TInkerPop standard and is supported by a variety of databases.
~"Context will increase the precision of machine learning systems"
Machine Learning was also mentioned during several presentations and they stated that (knowledge) graphs are an important aspect for ML as context information can increase the precision of systems. As an example they mentioned the Google Knowledge Graph ... the graph that already inspired us to work on an internal Enterprise Knowledge Graph 🙂 In the future, those graphs will be even more important as the world is becoming increasingly connected.


Other example: eBay leveraging knowledge graphs as the base for shopping bots
The trend, especially in Enterprises, is going from bringing tabular data to connected data, from disconnected silos to bridged silos (EKG...), and on top of that a single lake to perform analytics on.


Besides employees of Neo4j, Daimler and Generali went on stage and presented their use-cases for Neo4j. Daimler started in the past to have a swarm structure (an announcement Dieter Zetsche already mentioned in a talk "Das Nashorn-Prinzip: Groß und trotzdem alles andere als träge – wie sich ein Weltkonzern den Pionie... I saw at the KIT 2016): having teams without a strict hierarchy. Despite the lack of a hierarchy, Daimler is still interested in how persons are connected to each other and they use Neo4j to make this analyzable. Generali spoke about using Neo4j to get context information to detect fraud in insurance cases.
A different topic they mentioned was the upcoming GDPR law and how Neo4j can be used to be compliant.

It was followed by a presentation about how extensions can be easily developed for Neo4j to perform analytics and ml such as NLP, where GraphAware already put some effort into: GitHub Repo
~"We suck at being a key-value store or a document store, but we are completely focused on graphs"
The day closed with a presentation by the Chief Data Scientist of Neo4j: it was interesting and funny - a good end! He talked about the advantages of graph native systems vs. graph engines on top of non-graph dbs.

With beer and wine it was called a day, with the mission the CEO gave everyone: to connect with each other!
With

from Berlin
Twitter
