Hoeffding Tree Overview – Creating a Training Mod...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
While going through the video library, we noticed our Hoeffding Tree machine learning series was a little out of date, so we decided it was time for a makeover. If you’re using streaming analytics version 1.0 SP 11 or newer and want to learn how to train and score data in SAP HANA studio, check out part 1 of this new video series. There are more videos to come, and each will have an associated blog post just like this one, so stay on the lookout.
Here's an overview of part 1 and a sneak peek of the videos to come:
Summary
Part 1 is the beginning of the training phase, which involves creating a training model that uses the Hoeffding Tree training machine learning function. As data streams in, this function continuously works to discover predictive relationships in the model. To make sure things go smoothly, you need to use specific Hoeffding Tree training input and output schemas.
Input Schema
[IDS] + S
You can have as many feature columns as you need and each of these columns can be any combination of an integer, double, or string. The last column is a string, which is the label, or classifier. The data we’re working with in this video is sample insurance data, so the classifier will be “Yes” for a fraudulent claim, or “No” for a legitimate claim.
Output Schema
[D]
The output schema is more simple. There’s just one column, and it’s always a double. This displays a value between 0 and 1, which tells you the accuracy of the model.
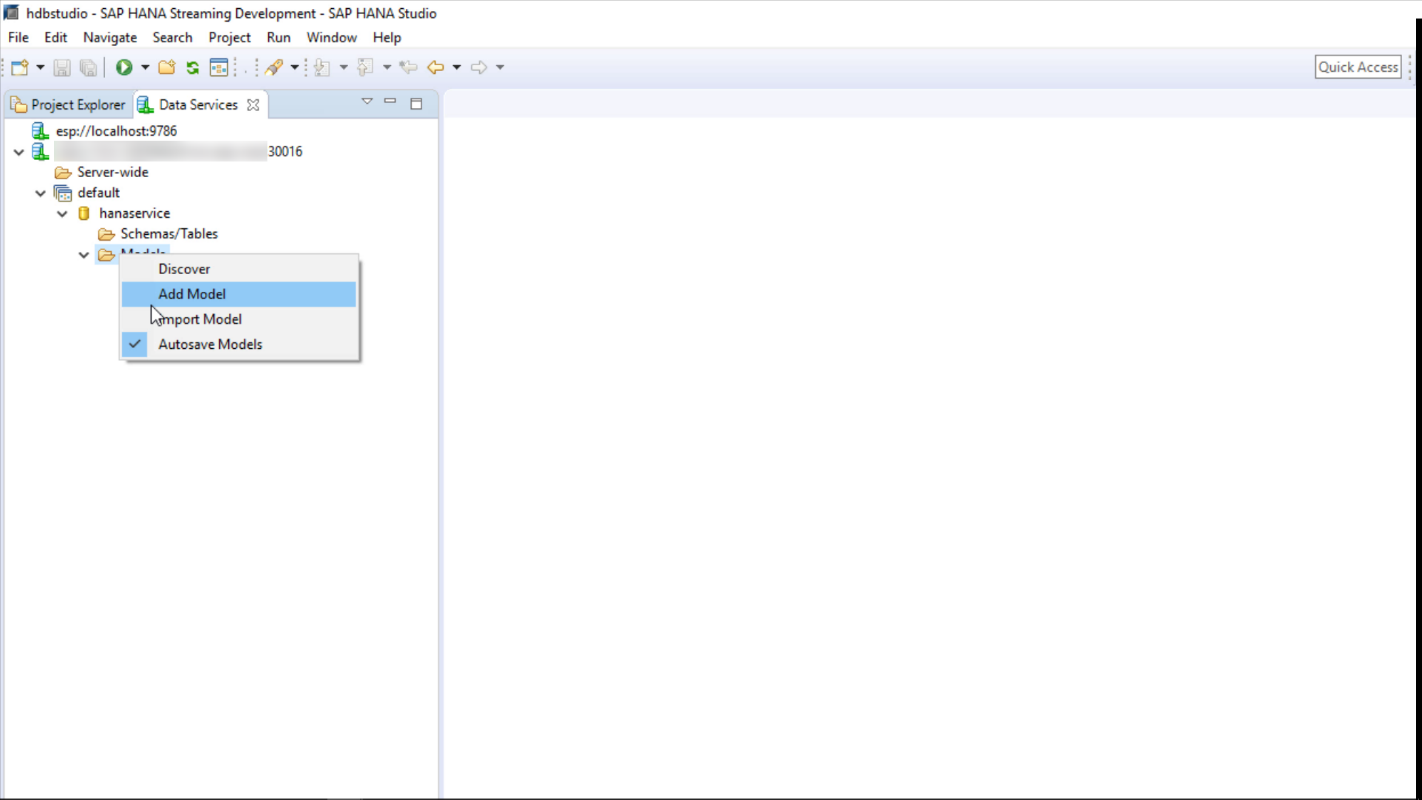
Once connected, drill down to the Models folder in the Data Services view and choose Add Model:
Then, open the model properties by selecting the model. In the General tab, fill in the fields:
Choose HoeffdingTreeTraining as the machine learning function. The above input and output schema match the source data you’ll use in the next video (more on that in the next blog). Because this is a simple example, we set the sync point to 5 rows. This means that for every 5 rows, the model will be backed up to the HANA database. Of course, you would likely use a much higher interval in a production setting. If you want to fill in the specifics of the algorithm, switch to the Parameters tab. In the video, we just used the defaults.
Note that you also have the option to save the model (if autosave isn’t enabled), delete it, or reset it. Deleting a model removes every trace of it, whereas resetting a model only removes its model content and evaluation data. This means that the model’s function will learn from scratch. The model itself remains in the data service, and the model metadata remains in the HANA database tables.
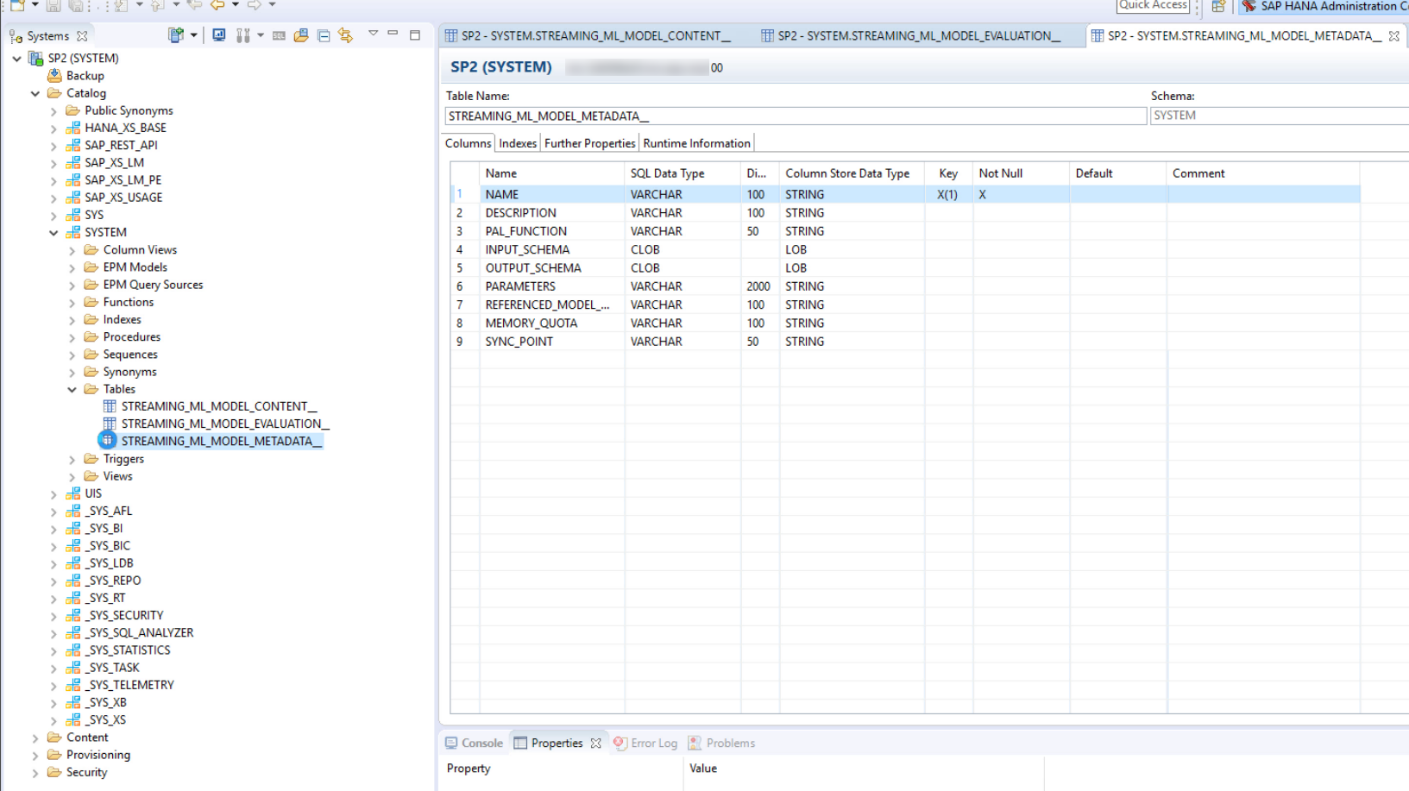
You can find the model metadata, along with the other tables that get created when you create a model, under the user schema in the SAP HANA Administration Console:
These tables store valuable overview information about the models you create, to which streaming analytics makes relevant changes whenever models are updated. These tables include a snapshot of the model properties, model performance stats, and so on. For more details, check out our table reference.
For more on machine learning models, check out the Model Management section of the SAP HANA Streaming Analytics: Developer Guide. If you’re interested in creating machine learning models in Web IDE, we've got a blog post for that too!