
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- sqlpad meets SAP HANA
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Manager
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-05-2018
3:45 PM
So the other week when my system totally crashed I found myself in need of a way to connect to my SAP HANA express system. Considering I had already been exploring a tool called SQLPAD I thought it was a perfect opportunity to go ahead and work on a contribution to Open Source.
Having already contacted the author of the project, Rick, he was open to the idea of a contribution so a fork in Github later and a few alternations to the codebase and I was ready to proceed. The internal process was pretty quick, took me just a couple of days while a simple form was processed (time zones delay everything!).


All checks were green! Now to wait for the pull request to be merged and see how things go! I've always found it amazing how a small amount code changes can make to the overall functionality of a program.

8 files, a few lines and a whole new database is supported!

The coolest part of course is watching your request get merged!

To top it off I just got an email this morning where Rick let me know that he has deployed the latest version to "npm" so you can now officially get your hands on it and connect it to your SAP HANA systems!
Looks like I may need to submit a change or two to the docs for the program in general but functionality wise we are set to go so far! So I wanted to share 3 ways you can get your hands on the program.
The direct install, well all of them are pretty straight forward. For this one you will need to have Node JS installed (version 6.0.0 is what I have done all my testing and usage with).
At your command prompt/terminal you can execute "npm install sqlpad -g"

To run it just type "sqlpad", granted you will probably want to add parameters, etc

The second option I played with is Vagrant, which I mentioned in my previous post about my system issues. My Vagrant file looks like:
This puts everything self contained into a VM.
The final option which i lean towards the most is my Docker config. Which puts my configuration for the program locally (I make sure it's in a sync'd folder).
My "docker-compose.yml" file looks like:
My "DockerFile" looks like:
Regardless of which of these methods or another method once it's up an running here you go. Once you have either signed in or signed up you can add your connection.

Now I added the IP of my SAP HANA express system to my hosts file so I could just put the hostname.

Now by leaving the "schema" blank I'm not tying the connection to anything specific, I can also give a specific "schema" as well.


Once I have my system connection I can start running queries.


To quickly test things I decided to check very quickly how my system was running.

Saving the queries make life easy because I can re run favorite queries anytime.
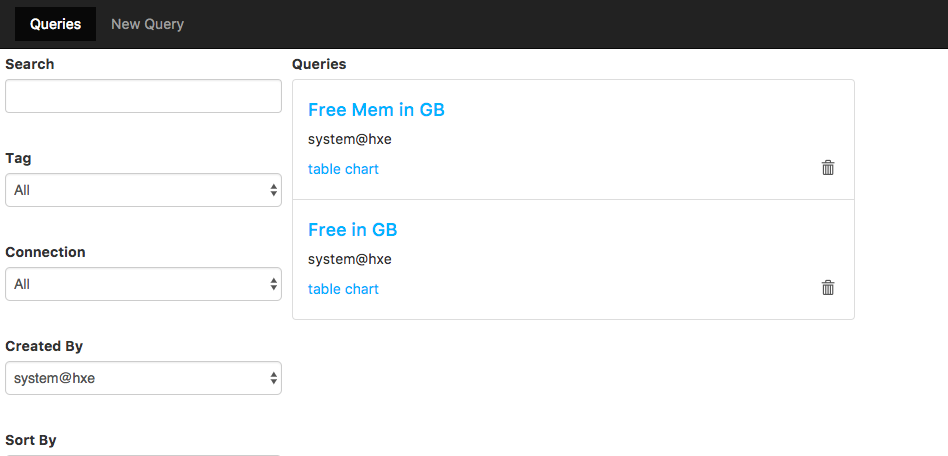
The data visualization is awesome, just not with this particular query.

Lightweight, easy to use and extensible - what more can you want from a tool? Now granted I'm sure many people are scratching their heads and saying "but but but" and yes SAP has their own tools, however if you are going after the "Server Only" version of SAP HANA express edition those tool choices are limited and limitations are not something I am a fan of so I decided to add another option to the mix.
Having already contacted the author of the project, Rick, he was open to the idea of a contribution so a fork in Github later and a few alternations to the codebase and I was ready to proceed. The internal process was pretty quick, took me just a couple of days while a simple form was processed (time zones delay everything!).
All checks were green! Now to wait for the pull request to be merged and see how things go! I've always found it amazing how a small amount code changes can make to the overall functionality of a program.
8 files, a few lines and a whole new database is supported!
The coolest part of course is watching your request get merged!
To top it off I just got an email this morning where Rick let me know that he has deployed the latest version to "npm" so you can now officially get your hands on it and connect it to your SAP HANA systems!
Looks like I may need to submit a change or two to the docs for the program in general but functionality wise we are set to go so far! So I wanted to share 3 ways you can get your hands on the program.
- Direct install
- Vagrant
- Docker
The direct install, well all of them are pretty straight forward. For this one you will need to have Node JS installed (version 6.0.0 is what I have done all my testing and usage with).
At your command prompt/terminal you can execute "npm install sqlpad -g"
To run it just type "sqlpad", granted you will probably want to add parameters, etc
The second option I played with is Vagrant, which I mentioned in my previous post about my system issues. My Vagrant file looks like:
# -*- mode: ruby -*-
# vi: set ft=ruby :
$rootScript = <<SCRIPT
sudo locale-gen "en_US.UTF-8"
sudo dpkg-reconfigure locales
sudo apt-get install -y git-core curl
SCRIPT
$userScript = <<SCRIPT
cd /home/vagrant
mkdir /home/vagrant/sqlpaddb
# Installing nvm
wget -qO- https://raw.github.com/creationix/nvm/master/install.sh | sh
# This enables NVM without a logout/login
export NVM_DIR="/home/vagrant/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh" # This loads nvm
echo "Installing: "
echo "Application: node.js"
nvm install stable &> /dev/null
nvm install 6.0.0
nvm alias default 6.0.0
npm install -g npm
# Install sqlpad
npm install sqlpad -g
sqlpad --dir /home/vagrant/sqlpaddb/ --port 3000 &> start.log & echo "SQL Pad started"
#/home/vagrant/.nvm/versions/node/v6.0.0/bin/sqlpad --dir /home/vagrant/sqlpaddb/ --port 3000 &> start.log
#/usr/sbin/node /home/vagrant/.nvm/versions/node/v6.0.0/lib/node_modules/sqlpad/server.js --dir /home/vagrant/sqlpaddb/ --port 3000 &> start.log
SCRIPT
ENV["LC_ALL"] = "en_US.UTF-8"
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/xenial64"
config.vm.provision "shell", inline: $rootScript
config.vm.provision "shell", inline: $userScript, privileged: false
config.vm.network "forwarded_port", guest: 3000, host: 3000, host_ip: "127.0.0.1"
config.vm.network "forwarded_port", guest: 3010, host: 3010, host_ip: "127.0.0.1"
config.vm.provider "virtualbox" do |vb|
# Customize the amount of memory on the VM:
vb.memory = "2048"
end
end
This puts everything self contained into a VM.
The final option which i lean towards the most is my Docker config. Which puts my configuration for the program locally (I make sure it's in a sync'd folder).
My "docker-compose.yml" file looks like:
version: '3'
services:
app:
build:
context: .
volumes:
- db-data:/opt/data
ports:
- "3000:3000"
volumes:
db-data:My "DockerFile" looks like:
FROM node:6.0.0
RUN apt-get update
RUN apt-get install -y less
RUN npm install
RUN npm install sqlpad -g
RUN mkdir -p /opt/data/
COPY ./db /opt/data/
EXPOSE 3000
CMD ["sh", "-c", "/usr/local/bin/sqlpad --dir /opt/data --port 3000"]Regardless of which of these methods or another method once it's up an running here you go. Once you have either signed in or signed up you can add your connection.
Now I added the IP of my SAP HANA express system to my hosts file so I could just put the hostname.
Now by leaving the "schema" blank I'm not tying the connection to anything specific, I can also give a specific "schema" as well.
Once I have my system connection I can start running queries.
To quickly test things I decided to check very quickly how my system was running.
Saving the queries make life easy because I can re run favorite queries anytime.
The data visualization is awesome, just not with this particular query.
Lightweight, easy to use and extensible - what more can you want from a tool? Now granted I'm sure many people are scratching their heads and saying "but but but" and yes SAP has their own tools, however if you are going after the "Server Only" version of SAP HANA express edition those tool choices are limited and limitations are not something I am a fan of so I decided to add another option to the mix.
- SAP Managed Tags:
- SQL,
- SAP HANA,
- SAP HANA, express edition
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
326 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- Partner Innovation - eMudhra's Co-Innovation Journey with SAP in Technology Blogs by SAP
- Cloud Integration - How to Manage Abnormally Large Files with SFTP Adapter and SAP HANA Database in Technology Blogs by Members
- What’s New in SAP Datasphere Version 2024.4 — Feb 13, 2024 in Technology Blogs by Members
- Did you know this about Capacity Planning in S/4HANA? in Technology Blogs by SAP
- Unveiling SAP BusinessObjects BI 4.3 SP04 ! in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |