

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Bringing Machine Learning (TensorFlow) to the ente...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-15-2017
4:54 PM
In this blog I aim to provide an introduction to TensorFlow and the SAP HANA integration, give you an understanding of the landscape and outline the process for using External Machine Learning with HANA.
There's plenty of hype around Machine Learning, Deep Learning and of course Artificial Intelligence (AI), but understanding the benefits in an enterprise context can be more challenging. Being able to integrate the latest and greatest deep learning models into your enterprise via a high performance in-memory platform could provide a competitive advantage or perhaps just keep up with the competition?
With HANA 2.0 SP2 onwards we have the ability to call TensorFlow (TF) models or graphs as they are known. HANA now includes a method to call External Machine Learning (EML) models via a remote source. The EML integration is performed using a wrapper function, very similar to the Predictive Analysis Library (PAL) or Business Function Library (BFL). Like the PAL and BFL, the EML is table based, with tables storing the model metadata, parameters, input data and output results. At the lowest level EML models are created and accessed via SQL, making them a perfect building block.
TensorFlow by itself is powerful, but embedding it within a business process or transaction could be a game changer. Linking it to your enterprise data seamlessly and being able to use the same single source of data for transactions, analytics and deep learning without barriers is no longer a dream. Having some control, and audit trail of what models were used by who, how many times, when they were executed and with what data is likely to be a core enterprise requirement.
TensorFlow itself, is a software library from Google that is accessed via Python. Many examples exist where TF has been used to process and classify both images and text. TF models work by feeding tensors, through multiple layers, a tensor itself, is just a set of numbers. These numbers are stored in a multi-dimensional arrays, which can make up a layer. The finally output of the model may lead to a prediction, such as a true/false classification. We use a typical supervised learning apprach i.e. the TensorFlow model first requires training data to learn from.
As shown below, a TF model is built up of many layers that feed into each other. We can train these models to identify almost anything, given the correct training data, and then integrate that identification within a business process. Below we could pass in an image and ask the TensorFlow model to classify (identify) it, based on training data.
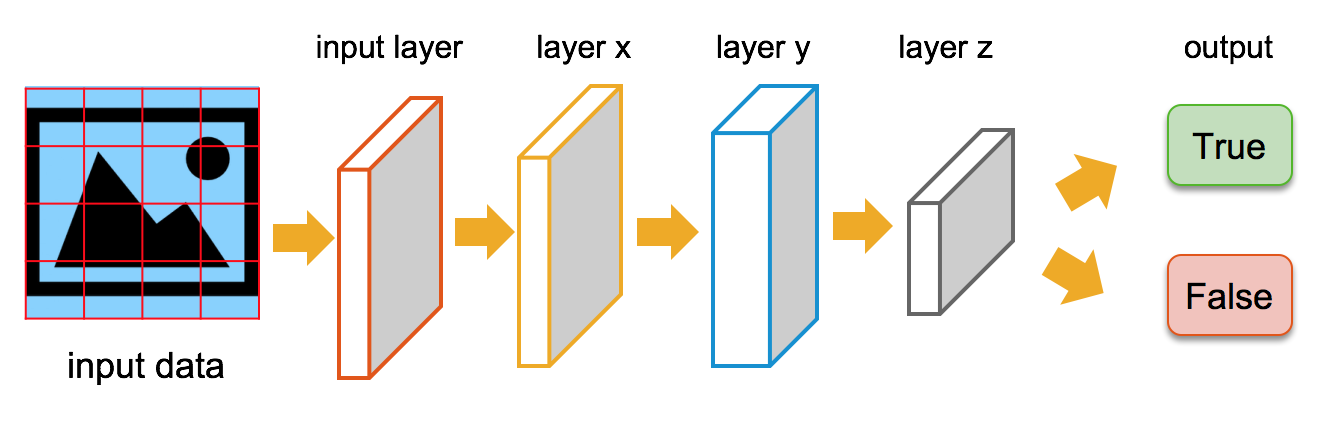
Equally, we could build a model that expects some unstructured text data. The models' internals may be quite different, but the overall concept would be similar

For text data and text classification, extensive research has been performed by Google with Word2Vec and Stanford publishing GloVe, providing vector representations of words. Pre-trained word vectors are available for download covering multiple languages.
With the SAP HANA TensorFlow integration, there are two distinct scenarios, model development/training and then model deployment. First you develop a model, train it, test it, validate it with training data, where the outcome is known. Here we have shown that environment with a Jupyter notebook. Finally, you would publish the model for TensorFlow Serving and make that model available via SAP HANA. During the development and training phase HANA would primarily be used as a data source.

Once a model has been published for scoring, the jupyter notebook and python are not being used.
Model execution is performed by TensorFlow Serving, which loads up a trained model and waits for input data from SAP HANA.
Often, to productionise a TensorFlow model with TensorFlow Serving you would need to develop a client specifically to interact with that model. With the HANA EML, we have a metadata wrapper that resides in HANA to provide a common way to call multiple TensorFlow Serving models. With the HANA EML TensorFlow models can now be easily integrated into enterprise applications and business processes.
There are at least 3 options to consider
I went with the pure Python library, from the SAP official GitHub https://github.com/SAP as this appears to be the most simple when moving platforms as it has the least dependencies, although it does not yet support SSL or Kerberos so may not be suitable for production just yet. Hdbcli is part of the HANA Client distribution and is the most comprehensive with the best performance, but requires a binary installation from .sar file. Pyodbc is a generic solution more suited to Windows only scenarios.
Newer isn't always better! Python 2.7 and Python 3.6 are not necessarily backwards or forward compatible. You can spend time debugging examples that were written against a different version. Many examples you find don’t specify a version, and when they do it’s easy to overlook this important detail. We used Python 3.6, but found many examples had 2.7 syntax which does not always work in 3.6. My advice is, always use the same Python version as any tutorials you are following. At the time of writing the TensorFlow Serving repository binary is for Python 2.7, you therefore may need to compile it yourself for Python 3.6.
Get familiar with Jupyter, this is a great interactive development environment. Jupyter runs equally well on your laptop or in Amazon Web Services (AWS) or Google Cloud Platform (GCP).
I began with Anaconda on my laptop, which provides applications (such as Jupyter), easy package management and environmental isolation. Jupyter notebooks are easy to move between local and AWS/GCP as long as the required Python libraries of the same version are installed on both platforms.
Keras is a python library that provides higher level access to TensorFlow functions and even allows you to switch between alternative deep learning backends such as Theano, Google TensorFlow and Microsoft Cognitive Toolkit (CNTK). we tried Theano and TensorFlow, and apparently you can even deploy Theano models to TensorFlow Serving
Once you are up and running with an example model you will find that it takes some time to train your models even with modern CPUs. With deep learning models you train the model over a number of epochs or episodes (a complete pass over the data set). After each epoch, the model learns from the previous epoch, it's common to run 16, 32, 64, 100 or even 1000 epochs. An epoch could take 30 seconds to run on a CPU and less than 1 second on a single GPU.
If you use a cloud platform both GCP and AWS, have specific instance types designed for this. If you use AWS, G3(g3.4xlarge) and P2 (p2.xlarge) or P3 (p3.2xlarge) are suited for Deep Learning, as they include GPUs. If using AWS I would recommend the P instance type, as these are the latest and greatest. If/when you are at this stage to fully utilise the GPUs you may need to compile TensorFlow or other deep learning foundation for your specific environment.
Once you are done with building, refining, training and testing your model you will then need to save it for TensorFlow Serving. Saving a model for serving is not necessarily easy! TensorFlow Serving wants a specific saved_model.pb. The saved models need to have a signature, that defines inputs and outputs. When you have created you own model you will likely need to build a specific saved_model function. We will share some code snippets in a future blog.
TensorFlow Serving is cross platform, but we found that Ubuntu seems to be Google's preferred Linux distribution. The prerequisites are straightforward for Ubuntu, which was not the case with Amazon Linux which evolved from RedHat.
There are many blogs and GitHub repositories to get you started, that provide walk-through examples and training for free. Some of the good ones include the following.
HANA Academy External Machine Learning (EML) Library on YouTube
HANA Academy Code Snippets GitHub
Open SAP - Enterprise Deep Learning
fast.ai
WildML
Identifying Fake News with SAP HANA & TensorFlow
There's plenty of hype around Machine Learning, Deep Learning and of course Artificial Intelligence (AI), but understanding the benefits in an enterprise context can be more challenging. Being able to integrate the latest and greatest deep learning models into your enterprise via a high performance in-memory platform could provide a competitive advantage or perhaps just keep up with the competition?
With HANA 2.0 SP2 onwards we have the ability to call TensorFlow (TF) models or graphs as they are known. HANA now includes a method to call External Machine Learning (EML) models via a remote source. The EML integration is performed using a wrapper function, very similar to the Predictive Analysis Library (PAL) or Business Function Library (BFL). Like the PAL and BFL, the EML is table based, with tables storing the model metadata, parameters, input data and output results. At the lowest level EML models are created and accessed via SQL, making them a perfect building block.
TensorFlow Introduction
TensorFlow by itself is powerful, but embedding it within a business process or transaction could be a game changer. Linking it to your enterprise data seamlessly and being able to use the same single source of data for transactions, analytics and deep learning without barriers is no longer a dream. Having some control, and audit trail of what models were used by who, how many times, when they were executed and with what data is likely to be a core enterprise requirement.
TensorFlow itself, is a software library from Google that is accessed via Python. Many examples exist where TF has been used to process and classify both images and text. TF models work by feeding tensors, through multiple layers, a tensor itself, is just a set of numbers. These numbers are stored in a multi-dimensional arrays, which can make up a layer. The finally output of the model may lead to a prediction, such as a true/false classification. We use a typical supervised learning apprach i.e. the TensorFlow model first requires training data to learn from.
As shown below, a TF model is built up of many layers that feed into each other. We can train these models to identify almost anything, given the correct training data, and then integrate that identification within a business process. Below we could pass in an image and ask the TensorFlow model to classify (identify) it, based on training data.
Equally, we could build a model that expects some unstructured text data. The models' internals may be quite different, but the overall concept would be similar
For text data and text classification, extensive research has been performed by Google with Word2Vec and Stanford publishing GloVe, providing vector representations of words. Pre-trained word vectors are available for download covering multiple languages.
HANA TensorFlow Landscape
With the SAP HANA TensorFlow integration, there are two distinct scenarios, model development/training and then model deployment. First you develop a model, train it, test it, validate it with training data, where the outcome is known. Here we have shown that environment with a Jupyter notebook. Finally, you would publish the model for TensorFlow Serving and make that model available via SAP HANA. During the development and training phase HANA would primarily be used as a data source.
Once a model has been published for scoring, the jupyter notebook and python are not being used.
Model execution is performed by TensorFlow Serving, which loads up a trained model and waits for input data from SAP HANA.
Often, to productionise a TensorFlow model with TensorFlow Serving you would need to develop a client specifically to interact with that model. With the HANA EML, we have a metadata wrapper that resides in HANA to provide a common way to call multiple TensorFlow Serving models. With the HANA EML TensorFlow models can now be easily integrated into enterprise applications and business processes.
Some Implementation Specifics
SAP HANA Python Connectivity
There are at least 3 options to consider
I went with the pure Python library, from the SAP official GitHub https://github.com/SAP as this appears to be the most simple when moving platforms as it has the least dependencies, although it does not yet support SSL or Kerberos so may not be suitable for production just yet. Hdbcli is part of the HANA Client distribution and is the most comprehensive with the best performance, but requires a binary installation from .sar file. Pyodbc is a generic solution more suited to Windows only scenarios.
Python 2.7 vs Python 3.6
Newer isn't always better! Python 2.7 and Python 3.6 are not necessarily backwards or forward compatible. You can spend time debugging examples that were written against a different version. Many examples you find don’t specify a version, and when they do it’s easy to overlook this important detail. We used Python 3.6, but found many examples had 2.7 syntax which does not always work in 3.6. My advice is, always use the same Python version as any tutorials you are following. At the time of writing the TensorFlow Serving repository binary is for Python 2.7, you therefore may need to compile it yourself for Python 3.6.
Jupyter Notebooks & Anaconda
Get familiar with Jupyter, this is a great interactive development environment. Jupyter runs equally well on your laptop or in Amazon Web Services (AWS) or Google Cloud Platform (GCP).
I began with Anaconda on my laptop, which provides applications (such as Jupyter), easy package management and environmental isolation. Jupyter notebooks are easy to move between local and AWS/GCP as long as the required Python libraries of the same version are installed on both platforms.
Keras
Keras is a python library that provides higher level access to TensorFlow functions and even allows you to switch between alternative deep learning backends such as Theano, Google TensorFlow and Microsoft Cognitive Toolkit (CNTK). we tried Theano and TensorFlow, and apparently you can even deploy Theano models to TensorFlow Serving
GPU > CPU
Once you are up and running with an example model you will find that it takes some time to train your models even with modern CPUs. With deep learning models you train the model over a number of epochs or episodes (a complete pass over the data set). After each epoch, the model learns from the previous epoch, it's common to run 16, 32, 64, 100 or even 1000 epochs. An epoch could take 30 seconds to run on a CPU and less than 1 second on a single GPU.
If you use a cloud platform both GCP and AWS, have specific instance types designed for this. If you use AWS, G3(g3.4xlarge) and P2 (p2.xlarge) or P3 (p3.2xlarge) are suited for Deep Learning, as they include GPUs. If using AWS I would recommend the P instance type, as these are the latest and greatest. If/when you are at this stage to fully utilise the GPUs you may need to compile TensorFlow or other deep learning foundation for your specific environment.
Serving the model
Once you are done with building, refining, training and testing your model you will then need to save it for TensorFlow Serving. Saving a model for serving is not necessarily easy! TensorFlow Serving wants a specific saved_model.pb. The saved models need to have a signature, that defines inputs and outputs. When you have created you own model you will likely need to build a specific saved_model function. We will share some code snippets in a future blog.
TensorFlow Serving is cross platform, but we found that Ubuntu seems to be Google's preferred Linux distribution. The prerequisites are straightforward for Ubuntu, which was not the case with Amazon Linux which evolved from RedHat.
Further Reading
There are many blogs and GitHub repositories to get you started, that provide walk-through examples and training for free. Some of the good ones include the following.
HANA Academy External Machine Learning (EML) Library on YouTube
HANA Academy Code Snippets GitHub
Open SAP - Enterprise Deep Learning
fast.ai
WildML
SAP Help - SAP HANA External Machine Learning Library
Identifying Fake News with SAP HANA & TensorFlow
- SAP Managed Tags:
- Machine Learning,
- SAP HANA,
- SAP HANA, platform edition
8 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 7 in Technology Blogs by SAP
- Learning Material for - SAC Certification ? in Technology Q&A
- CAP LLM Plugin – Empowering Developers for rapid Gen AI-CAP App Development in Technology Blogs by SAP
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |