
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Develop your agile DW with SAP Web IDE - SAP HANA ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-08-2017
4:00 AM
Building on the previous blog on designing your agile Data Warehouse (DW), now is the time to look at the next step: developing the SAP HANA SQL DW. In this post, I'll introduce the “data oriented” tools that are part of the Web IDE for SAP HANA.

So, the Web IDE is a set tools for developers to build the integrations and calculations that define your HANA SQL DW. The Web IDE is most commonly known as the tool for creating applications, not specifically a DW. As there are already enough blogs out there describing the “application use case” of Web IDE, this blog describes the parts with which you build your DW. For those familiar with the “classic” HANA tooling, you could assume that the WebIDE components presented here are just the successors of the Modeler and Development perspective in HANA Studio or the Web development workbench. That is not the complete story though: there are major extensions and improvements for the DW use case, which are emphasized in this blog post.

The below illustration provides an overview of the HANA SQL DW. To scope of this post excludes the more generic data sources (the ones mentioned are just examples), consumption layer (which sits outside the DW anyway), data lakes (we save that for another post), and ingestion layer (enough blogs on that). That leaves us with what is inside the yellow box, and these are the technologies that the HANA SQL DW developer works with. SQL and procedures should be known to you, so we focus on data sourcing with virtual tables, data definition with CDS and the Native DSO, virtualization with Calculation Views, ETL with flowgraphs, and scheduling with Task chains. Data distribution (DDO), Data Lifecycle Manager (DLM) and the DW Monitor will be described when we get to the 'run' phase.

The content of this blog post is based on the latest releases at time of writing: HANA2 SPS02 with the XS Advanced Runtime and Web IDE, and Data Warehouse Foundation SPS02.
Data from external systems are sourced through the HANA platform, where you must first set up a remote source. Then you can identify your source objects (tables, views, procedures). The example illustration below is how you define a virtual table. Each file you create in the Web IDE has an explicit extension, here that is hdbvirtualtable.

Virtual tables are used in three ways:
You might also want to source data locally, for example from another schema. With containers leveraged by the Web IDE, by default a projects’ database module builds a schema that has no privilege to access objects outside of that container. If you do want to access that data, you have to explicitly create pointers to the “outside”. These pointers are represented by synonyms, or hdbsynonym files. How exactly these synonyms work is described in detail in a series of blogs, starting here.
Sometimes you need to create deployable reference data, or you just need some test data into your container to play with. A convenient way to create small data sets are the hdbtabledata files, which you can point to the CSV files included in your project. When performing a build of your project, the content of the CSV file is inserted into the designated table. As these files are part of your design time repository, they can be easily reused. Loading large files on a regular basis is better done using the SDI Data Provisioning agent, which is outside the scope of this post.

In the previous post, Enterprise Architect Designer was introduced, amongst others to define your DW data model. After all, you need to define the model for your staging area, harmonization layer, or however you like to call it. The default design time language for this is Core Data Services (CDS).
CDS is often described in the context of building pure applications, but CDS certainly also serves the DW use case. Most prominently for table definitions, it removes the need of having to manage change. In any SQL DW, change usually requires writing an ALTER statement if you want to keep the existing data, or DROP+CREATE if not. As a DW typically holds so many data definitions, and changes to those are frequent, the string of these alterations are difficult to keep track of. This easily results in misalignment between development and production, the daunting task of realigning these without losing data.
CDS is a declarative language. Simply put, you define how the target table should look like, not how an existing definition should be changed; and change is managed by SAP HANA. Upon the creation of a CDS entity, SAP HANA checks if the runtime table already exists, and how the runtime definition can be changed without losing data. It's worth noting that with XS Advanced, CDS now supports leaving out namespaces, which gives you the liberty to define your table names completely per your own naming convention. Also, comments for tables and table columns are now supported, and this metadata is fed directly to calculation views, where column comments are consumed as column labels and then propagated to the end-user tools.
There’s also the option of still using CREATE and ALTER TABLE statements, by shooting these off from the Web IDE integrated Database Explorer. Or you can embed create statements in *.hdbtable definitions, or embed any SQL statement in an *.hdbprocedure file. These are design time objects, so you benefit from storing these definitions in the central GIT repository.


Let’s say you load a batch of source data to your target table, resulting in inserts, updates, and deletions of records in your target table. What if you regret executing this load, for example, because your source system accidentally delivered an old or incomplete data set? There’s no way to go back to the original set of data, except by either truncating and reloading (losing any history) or restoring the entire database.
Because this situation applies to any DW, a common workaround includes implementing complicated snapshotting and logical rollback procedures in the DW. However, developing this and keeping it running can take considerable effort. It will require additional fields like from/to dates for time slicing, additional tables for change recording, processes for loading metadata tables, etc. And what about the resources needed to do the necessary data compares? These processes can be very resource intensive and increase DWH load times.

The Native DataStoreObject (NDSO) is the answer to the above described problem. The NDSO offers the following features:
Once you install the Data Warehouse Foundation plugin, you can define these NDSO’s directly in the Web IDE CDS Editor. You can also use the EA Designer for this, or both. As NDSO’s are defined in CDS, they also take advantage of afore mentioned CDS characteristics.


Your persistent data transformations are handled by flowgraphs, which you develop in the Web IDE, just like the other components described here. The functions of the flowgraph are best compared with an ETL tool like SAP Data Services, which takes the same approach with each node describing a data source, transformation, or data target. Like Data Services, flowgraphs can handle multiple data sources, multiple transform nodes, and multiple data targets defined as one data flow. The major difference with “external” ETL tools is that flowgraphs are completely executed in the HANA database – 100% push down - there is no application engine involved that executes part of the logic. This delivers HANA performance, without any chance for slowing down through data traffic between the DB and ETL application engine.

Calculation Views in the Web IDE on XS Advanced are pretty similar to the ones you know from SAP HANA Studio or XS classic. There are differences in looks, some differences in features. I’m assuming that you are already familiar with Calculation Views, but if not: Calculation Views allow you to define data transformations “on the fly”, leveraging the speed of SAP HANA and thereby reducing the need for persistent data transformations. Also, they are the access layer to external reporting tools, providing features like a semantic layer, privilege handling, hierarchies, and currency conversion.
If you want to know more, I’d recommend to look up one of the many already existing blogs. As the calculation views are not very different from the ones you know from SAP HANA 1, I won’t go into further detail on these.

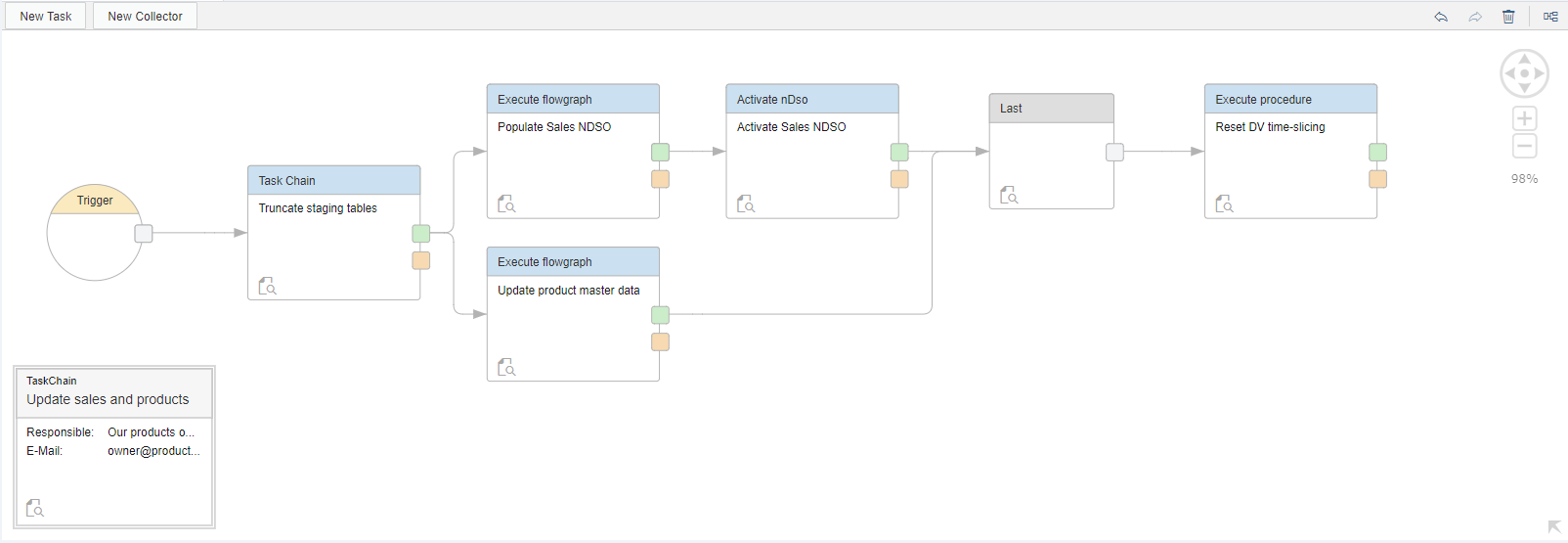
Flowgraphs, procedures, Native DSO activations: these are objects that usually need to be run in a certain order, and need to either be scheduled at certain times or need to be triggered by a certain event. By leveraging the Data Warehouse Foundation plugin, the Web IDE does this with Task Chains. The below screenshot should give you an idea of how you create these.
This post served to introduce the major components a developer would use in the HANA SQL DW, but there are several other components that we did not talk that you will or might need:
The goal of this post was to present the main objects you would develop in the HANA SQL DW, as seen from the perspective of a DW developer. I hope that was helpful, and I’m looking forward to your comments.
If you’re interested in learning more about Data Warehouse Foundation features like the NDSO, Task chains, or Data Lifecycle Manager, please visit this Intro to the Data Warehouse Foundation blog with more technical detail and learning resources.
Explore SAP’s next generation data warehousing solutions.
So, the Web IDE is a set tools for developers to build the integrations and calculations that define your HANA SQL DW. The Web IDE is most commonly known as the tool for creating applications, not specifically a DW. As there are already enough blogs out there describing the “application use case” of Web IDE, this blog describes the parts with which you build your DW. For those familiar with the “classic” HANA tooling, you could assume that the WebIDE components presented here are just the successors of the Modeler and Development perspective in HANA Studio or the Web development workbench. That is not the complete story though: there are major extensions and improvements for the DW use case, which are emphasized in this blog post.
The below illustration provides an overview of the HANA SQL DW. To scope of this post excludes the more generic data sources (the ones mentioned are just examples), consumption layer (which sits outside the DW anyway), data lakes (we save that for another post), and ingestion layer (enough blogs on that). That leaves us with what is inside the yellow box, and these are the technologies that the HANA SQL DW developer works with. SQL and procedures should be known to you, so we focus on data sourcing with virtual tables, data definition with CDS and the Native DSO, virtualization with Calculation Views, ETL with flowgraphs, and scheduling with Task chains. Data distribution (DDO), Data Lifecycle Manager (DLM) and the DW Monitor will be described when we get to the 'run' phase.
Figure 1: The HANA SQL DW. This post describes what's in the yellow box.
The content of this blog post is based on the latest releases at time of writing: HANA2 SPS02 with the XS Advanced Runtime and Web IDE, and Data Warehouse Foundation SPS02.
Extract sources with synonyms, virtual tables and flat files
Data from external systems are sourced through the HANA platform, where you must first set up a remote source. Then you can identify your source objects (tables, views, procedures). The example illustration below is how you define a virtual table. Each file you create in the Web IDE has an explicit extension, here that is hdbvirtualtable.
Figure 2: Virtual table definition
Virtual tables are used in three ways:
- To provide data “on the fly”, when the source database is accessed whenever the DW is queried. In that case, data might travel through calculation views or other objects, but is not stored on the HANA database.
- As the source for persistent storage in the DW. In that case, flowgraphs or DB procedures take these virtual tables as a source and a local database table as a target.
- As part of real-time replication with SAP HANA Smart Data Integration (SDI). At this point these replications are managed outside of the Web IDE, for which you then use a synonym to consume them.
You might also want to source data locally, for example from another schema. With containers leveraged by the Web IDE, by default a projects’ database module builds a schema that has no privilege to access objects outside of that container. If you do want to access that data, you have to explicitly create pointers to the “outside”. These pointers are represented by synonyms, or hdbsynonym files. How exactly these synonyms work is described in detail in a series of blogs, starting here.
Sometimes you need to create deployable reference data, or you just need some test data into your container to play with. A convenient way to create small data sets are the hdbtabledata files, which you can point to the CSV files included in your project. When performing a build of your project, the content of the CSV file is inserted into the designated table. As these files are part of your design time repository, they can be easily reused. Loading large files on a regular basis is better done using the SDI Data Provisioning agent, which is outside the scope of this post.
Figure 3: design time small data sets with hdbtabledata
Create your DW data model with CDS
In the previous post, Enterprise Architect Designer was introduced, amongst others to define your DW data model. After all, you need to define the model for your staging area, harmonization layer, or however you like to call it. The default design time language for this is Core Data Services (CDS).
CDS is often described in the context of building pure applications, but CDS certainly also serves the DW use case. Most prominently for table definitions, it removes the need of having to manage change. In any SQL DW, change usually requires writing an ALTER statement if you want to keep the existing data, or DROP+CREATE if not. As a DW typically holds so many data definitions, and changes to those are frequent, the string of these alterations are difficult to keep track of. This easily results in misalignment between development and production, the daunting task of realigning these without losing data.
CDS is a declarative language. Simply put, you define how the target table should look like, not how an existing definition should be changed; and change is managed by SAP HANA. Upon the creation of a CDS entity, SAP HANA checks if the runtime table already exists, and how the runtime definition can be changed without losing data. It's worth noting that with XS Advanced, CDS now supports leaving out namespaces, which gives you the liberty to define your table names completely per your own naming convention. Also, comments for tables and table columns are now supported, and this metadata is fed directly to calculation views, where column comments are consumed as column labels and then propagated to the end-user tools.
There’s also the option of still using CREATE and ALTER TABLE statements, by shooting these off from the Web IDE integrated Database Explorer. Or you can embed create statements in *.hdbtable definitions, or embed any SQL statement in an *.hdbprocedure file. These are design time objects, so you benefit from storing these definitions in the central GIT repository.
Figure 4: CDS Graphical Editor in Web IDE, which you can use alongside EA Designer
Figure 5: CDS Code Editor in Web IDE – no SQL create statement here
Request and delta handling with the Native DataStoreObject
Let’s say you load a batch of source data to your target table, resulting in inserts, updates, and deletions of records in your target table. What if you regret executing this load, for example, because your source system accidentally delivered an old or incomplete data set? There’s no way to go back to the original set of data, except by either truncating and reloading (losing any history) or restoring the entire database.
Because this situation applies to any DW, a common workaround includes implementing complicated snapshotting and logical rollback procedures in the DW. However, developing this and keeping it running can take considerable effort. It will require additional fields like from/to dates for time slicing, additional tables for change recording, processes for loading metadata tables, etc. And what about the resources needed to do the necessary data compares? These processes can be very resource intensive and increase DWH load times.
Figure 6: Classic way of handling request and delta handling
The Native DataStoreObject (NDSO) is the answer to the above described problem. The NDSO offers the following features:
- Request management out of the box;
- Superb data compare performance, as the code line is integrated in the HANA DB;
- Delta handling, to easily push only new load requests to subsequent data targets;
- A friendly user interface for load monitoring and request handling features such as roll-back;
- Native integration with EIM flowgraphs, but 3rd party ETL can also connect straight to it;
- Supports for the “delta language” or recordMode of SAP data source extractors.
Once you install the Data Warehouse Foundation plugin, you can define these NDSO’s directly in the Web IDE CDS Editor. You can also use the EA Designer for this, or both. As NDSO’s are defined in CDS, they also take advantage of afore mentioned CDS characteristics.
Figure 7: (Optional) Native DSO taking care of request and delta handling
Figure 8: Example of managing requests for a Native DSO
Transform and store data with flowgraphs
Your persistent data transformations are handled by flowgraphs, which you develop in the Web IDE, just like the other components described here. The functions of the flowgraph are best compared with an ETL tool like SAP Data Services, which takes the same approach with each node describing a data source, transformation, or data target. Like Data Services, flowgraphs can handle multiple data sources, multiple transform nodes, and multiple data targets defined as one data flow. The major difference with “external” ETL tools is that flowgraphs are completely executed in the HANA database – 100% push down - there is no application engine involved that executes part of the logic. This delivers HANA performance, without any chance for slowing down through data traffic between the DB and ETL application engine.
Figure 9: Example of a flowgraph in Web IDE
Transform data virtually and define the access layer with Calculation Views
Calculation Views in the Web IDE on XS Advanced are pretty similar to the ones you know from SAP HANA Studio or XS classic. There are differences in looks, some differences in features. I’m assuming that you are already familiar with Calculation Views, but if not: Calculation Views allow you to define data transformations “on the fly”, leveraging the speed of SAP HANA and thereby reducing the need for persistent data transformations. Also, they are the access layer to external reporting tools, providing features like a semantic layer, privilege handling, hierarchies, and currency conversion.
If you want to know more, I’d recommend to look up one of the many already existing blogs. As the calculation views are not very different from the ones you know from SAP HANA 1, I won’t go into further detail on these.
Figure 10: Calculation Views in Web IDE, which are very similar in function and looks as in HANA Studio or XS classic
Scheduling with Task Chains
Flowgraphs, procedures, Native DSO activations: these are objects that usually need to be run in a certain order, and need to either be scheduled at certain times or need to be triggered by a certain event. By leveraging the Data Warehouse Foundation plugin, the Web IDE does this with Task Chains. The below screenshot should give you an idea of how you create these.
Figure 11: Scheduling operations with Task Chains
What we did not talk about
This post served to introduce the major components a developer would use in the HANA SQL DW, but there are several other components that we did not talk that you will or might need:
- Besides what was described above, you might also need, for example, analytical privileges (to define your row-based access privileges), database procedures, sequences and access roles. A full overview of all supported objects is provided in the HDI Artifact Types and Build Plug-ins Reference.
- No application controller or UI view components were described. You also don’t need this to build a DW, but what if you want to build custom applications that interact with your DW? The Web IDE is meant to build such applications, and it will be easy to integrate them with your DW.
- The Web IDE itself, how the different editors shown above are started, and how the Web IDE works with the GIT repository. We'll be covering this in an upcoming blog post. The same goes for monitoring tools, and the Data Lifecycle Manager. These are handled in the run phase.
Conclusion
The goal of this post was to present the main objects you would develop in the HANA SQL DW, as seen from the perspective of a DW developer. I hope that was helpful, and I’m looking forward to your comments.
If you’re interested in learning more about Data Warehouse Foundation features like the NDSO, Task chains, or Data Lifecycle Manager, please visit this Intro to the Data Warehouse Foundation blog with more technical detail and learning resources.
Explore SAP’s next generation data warehousing solutions.
- SAP Managed Tags:
- SAP Datasphere,
- SAP HANA
Labels:
13 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
427 -
Workload Fluctuations
1
Related Content
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- What are the use cases of SAP Datasphere over SAP BW4/HANA in Technology Q&A
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 3 in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP: Blog 2 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog Series in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |