
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- Best Practices for ABAP Development on SAP Netweav...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
alex_belle
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-02-2017
10:52 PM
ABAP 7.50/7.51/7.52 are the versions available for S/4 HANA 1610/1709 On-premise solution and they came with new features and new syntax for ABAP development.
In this blog you'll find a collection of Best Practices for ABAP development in Netweaver 7.5x that could guide you in this journey. There are lot of good Blogs referenced in this Blog.
Let's start with what is new in this version:
First, do not forget the kernel releases for each Release version of SAP Netweaver, see the table below:
Best Practice: Be Aware of Changes fo Each Version of SAP Netweaver 7.5x
1. Best Practice: Start Your Development with The Right Type.
From Release 7.50, AS ABAP can only run as a Unicode system, it means that all executable ABAP programs are Unicode programs and non-Unicode are no longer supported.
Update 1: Please read the comments from 93b1c542d4984f0e9a75a57ce6030ff3
When you are creating program in ADT it sets automatically the type to Unicode and you don't need to do it manually. Also you can check it opening you program and pressing ALT+ SHIFT + W or following the sequence below:
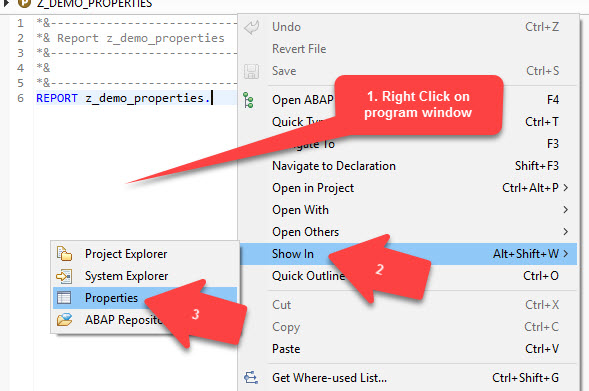
Now you can see the properties tab and just click on "specific" to get information about the ABAP Language Version. See below:

But if you are creating a program using the old SE80 or SE38 in SAP GUI instead of new ADT, keep selected "Standard ABAP (Unicode)" for "ABAP Language Version" propertie . See the picture below:

2.Best Practice: Be Aware of The New Data Types and ABAP Dictionary in Release 7.50
There are 3 important changes:
2.1 New Predefined ABAP Type int8
Apart from the extended value range ( -9.223.372.036.854.775.808 to +9.223.372.036.854.775.807), the new data type int8 has the same properties as the existing data type i for 4-byte integers, with the following exceptions:
There is a good example from Horst Keller's blog, please take a look at the following link: https://blogs.sap.com/2015/10/22/abap-news-for-release-7.50-fundamentals/
2.2 Global Temporary Tables
A global temporary table (GTT) can only be filled with temporary data during a database LUW. When a GTT is filled using Open SQL, it must be emptied again explicitly before the next implicit database commit. If not, a non-handleable exception is raised.
2.3 Replacement Objects
A CDS (Core Data Services) can be assigned as a replacement object to a transparent database table or a classic database view. In Open SQL reads, the replacement object is then accessed instead of the original object.
3.Best Practice: Be Aware of The Expressions and Functions in Release 7.50
3.1 Predicate Expression for Type Inspection and Case Distiction
This predicate expression "IS INSTANCE OF" makes possible to check the feasibility of a down cast before it is execute. In other words, you can use it detect the dynamic type of an object reference variable.
Take a look at the explanation from Horst Keller's blog, link: https://blogs.sap.com/2015/10/21/abap-news-for-release-750-is-instance-of/
Also you should check this link about the class cl_abap_corresponding
https://blogs.sap.com/2015/10/29/abap-news-for-release-750-corresponding-again/
The example below help you to understand how to use CL_ABAP_CORRESPONDING for internal tables. There are three tables, tab1, tab2 and tab3. First we move the values from tab1 to tab2 using the matching names.
In the second assignment, a mapping table table is passed.
In the third assignment, the values are moved from tab1 to tab3 using the matching names. Only the columns with same name are assigned to tab3.
See the results:
4. Best Practice: Improve The Error Handling in your ABAP Code Using New Features in Exception Classes in Release 7.5x
When you add one of the following ABAP superclasses below:
Then an ABAP exception class is automatically created.
The system IF_T100_MESSAGE is used to statically assign specific messages to an exception class that defines the semantics of the exception. The system interface IF_T100_DYN_MSG allows you to assign arbitrary messages of message classes to the exception by using the statement RAISE EXCEPTION ... MESSAGE ... at runtime.
If you want to see this new feature in action or if you did not understand very well what it's meaning, take a look at the demo programs listed below in your SAP NW 7.5x using t-code SE38.
The code below is the demo_raise_message_error program, pay attention in the code inside of the red blocks:

If you want to get access to text code click here or click here to get the entire documentation about this topic.
More explanation about this tops in the Horst Keller's blog.
5. Best Practice: Right Usage of The Open SQL in Release 7.50
Of course the Open SQL is getting more and more powerful, in other words, SAP has been increased coverage of the SQL Standard in Open SQL.
5.1 Best Practice: Make a Good Usage of The Expression UNION.
Look the following example:
Note: This example can be available in your NW 7.5x.
See the results below:
Understanding the results:
Four columns of the same type from result sets from three database tables DEMO_JOIN1, DEMO_JOIN2 and DEMO_JOIN3 are combined to make multiple SELECT statements using UNION. The database tables are filled in the static constructor.
Source: https://help.sap.com/doc/abapdocu_750_index_htm/7.50/en-US/index.htm?file=abapunion_clause.htm
5.2 Best Practice: Improve Your Code with Sub-queries as Data Source of INSERT. See The Example Below.
The example below shows the statement INSERT with the addition FROM SELECT, in other words, it inserts data from another select instruction.
The database table DEMO_SUMDIST_AGG is filled with aggregated data from the tables SCARR and SPFLI.
The result of both INSERT statements is the same. DEMO_SUMDIST_AGG is a global temporary table (GTT), which means that its content must be deleted before the results are produced (since this creates an implicit database commit).
Source: https://help.sap.com/doc/abapdocu_750_index_htm/7.50/en-US/index.htm?file=abeninsert_from_select_abe...
5.3 Best Practices: Open SQL Performance in ABAP 7.5
There are three best practices which can be combined to improve the performance for Open SQL in ABAP 7.5X, see below:
5.4 Best Practice: Use The New Open SQL Functions in Order to Reduce the Number of Operations in ABAP. See the functions below:
Take a look at: https://blogs.sap.com/2015/11/27/abap-language-news-for-release-750/
6. Best Practices: Be Aware and Understand How to Use CDS Views in Your Projects and Save Time.
The CDS views are one of the best innovations delivered by SAP in the last years. It is really powerful and the advanced users and developers should take advantages.
You can get more information about CDS Views here.
if you are not familiar with CDS Views, try the links below, they really will help you to understand the CDS views.
The connectivity with SAP HANA and the facility to publish CDS views as OData Service are really great features . You can find a good example in the following blog from Raja Prasad Gupta: How to create ABAP CDS view and OData with SAP Annotations.
Also you can find more information about CDS Views and Odata in SAP Help.
Do you want to read more about CDS Annotations? So, click here.
6.1 Best Practice: Improve Security of Your CDS Views using ABAP CDS Access Control. Take a look in the following links:
6.2 Best Practice: Extend your CDS Views Instead of Creating New CDS views. Link .
6.3 Best Practice: Improve Readability in Your CDS Views. Follow the link.
6.4 Use The Dependency Analyzer to Evaluate The Relationships and Complexity of CDS Entity With Regards to its SQL Definition.
The Dependency Analyzer helps you to understand SQL dependencies and complexity that might negatively affect the performance of your query.
Analyzing Dependencies in Complex CDS Views.
7. Best Practice: Keep your ABAP Tools up to date. In September 2017 SAP released the latest version (2.83) of the document: "Installing ABAP Development Tools for SAP". This document will support you on the installation of ABAP Develpoment Tools.

Link to document.
8. Best Practice: Understand Which Version of ABAP Development Tools is Related to each Version of SAP Netweaver.
Link to Source.
9. Best Practice: Be aware of the S/4 HANA and ABAP Programming Model.
The following link give you the direction to Carine Tchoutouo Djomo's Blog. There you will find a lot of information regarding the S/4 HANA and ABAP Programming Model. It includes examples and videos: LINK
In this blog you'll find a collection of Best Practices for ABAP development in Netweaver 7.5x that could guide you in this journey. There are lot of good Blogs referenced in this Blog.
Let's start with what is new in this version:
First, do not forget the kernel releases for each Release version of SAP Netweaver, see the table below:
Best Practice: Be Aware of Changes fo Each Version of SAP Netweaver 7.5x
1. Best Practice: Start Your Development with The Right Type.
From Release 7.50, AS ABAP can only run as a Unicode system, it means that all executable ABAP programs are Unicode programs and non-Unicode are no longer supported.
Update 1: Please read the comments from 93b1c542d4984f0e9a75a57ce6030ff3
When you are creating program in ADT it sets automatically the type to Unicode and you don't need to do it manually. Also you can check it opening you program and pressing ALT+ SHIFT + W or following the sequence below:
- Perform a right Click on program window
- Select "Show in" on menu
- Click on "Properties"
Now you can see the properties tab and just click on "specific" to get information about the ABAP Language Version. See below:
But if you are creating a program using the old SE80 or SE38 in SAP GUI instead of new ADT, keep selected "Standard ABAP (Unicode)" for "ABAP Language Version" propertie . See the picture below:
2.Best Practice: Be Aware of The New Data Types and ABAP Dictionary in Release 7.50
There are 3 important changes:
2.1 New Predefined ABAP Type int8
Apart from the extended value range ( -9.223.372.036.854.775.808 to +9.223.372.036.854.775.807), the new data type int8 has the same properties as the existing data type i for 4-byte integers, with the following exceptions:
- The alignment required for data objects of type int8 is an address divisible by 8.
- The value of the output length of data objects of type int8 is 20.
- A new calculation type has been introduced for int8, situated between i and p in the hierarchy.
There is a good example from Horst Keller's blog, please take a look at the following link: https://blogs.sap.com/2015/10/22/abap-news-for-release-7.50-fundamentals/
2.2 Global Temporary Tables
A global temporary table (GTT) can only be filled with temporary data during a database LUW. When a GTT is filled using Open SQL, it must be emptied again explicitly before the next implicit database commit. If not, a non-handleable exception is raised.
2.3 Replacement Objects
A CDS (Core Data Services) can be assigned as a replacement object to a transparent database table or a classic database view. In Open SQL reads, the replacement object is then accessed instead of the original object.
3.Best Practice: Be Aware of The Expressions and Functions in Release 7.50
3.1 Predicate Expression for Type Inspection and Case Distiction
This predicate expression "IS INSTANCE OF" makes possible to check the feasibility of a down cast before it is execute. In other words, you can use it detect the dynamic type of an object reference variable.
Take a look at the explanation from Horst Keller's blog, link: https://blogs.sap.com/2015/10/21/abap-news-for-release-750-is-instance-of/
Also you should check this link about the class cl_abap_corresponding
https://blogs.sap.com/2015/10/29/abap-news-for-release-750-corresponding-again/
The example below help you to understand how to use CL_ABAP_CORRESPONDING for internal tables. There are three tables, tab1, tab2 and tab3. First we move the values from tab1 to tab2 using the matching names.
In the second assignment, a mapping table table is passed.
In the third assignment, the values are moved from tab1 to tab3 using the matching names. Only the columns with same name are assigned to tab3.
REPORT Z_ABAP_BP_CORRESPONDING.
CLASS DEMO_CORRESPONDING DEFINITION.
PUBLIC SECTION.
CLASS-METHODS main.
ENDCLASS.
CLASS DEMO_CORRESPONDING IMPLEMENTATION.
METHOD main.
TYPES: BEGIN OF line1,
Name TYPE C LENGTH 50,
age TYPE i,
salary TYPE P LENGTH 10 DECIMALS 2,
END OF line1,
BEGIN OF line2,
name TYPE C LENGTH 50,
age TYPE i,
END OF line2,
BEGIN OF line3,
name TYPE C LENGTH 50,
salary TYPE P LENGTH 10 DECIMALS 2,
END OF line3.
DATA: itab1 TYPE TABLE OF line1 WITH EMPTY KEY,
itab2 TYPE TABLE OF line2 WITH EMPTY KEY,
itab3 TYPE TABLE OF line3 WITH EMPTY KEY.
DATA(out) = cl_demo_output=>new( ).
itab1 = VALUE #(
( name = 'John' age = 32 salary = '3500')
( name = 'Mary' age = 33 salary = '3534') ).
out->write( itab1 ).
cl_abap_corresponding=>create(
source = itab1
destination = itab2
mapping = VALUE cl_abap_corresponding=>mapping_table( )
)->execute( EXPORTING source = itab1
CHANGING destination = itab2 ).
out->write( itab2 ).
cl_abap_corresponding=>create(
source = itab1
destination = itab2
mapping = VALUE cl_abap_corresponding=>mapping_table(
( level = 0 kind = 1 srcname = 'name' dstname = 'name' )
( level = 0 kind = 1 srcname = 'age' dstname = 'age' ) )
)->execute( EXPORTING source = itab1
CHANGING destination = itab2 ).
out->write( itab2 ).
cl_abap_corresponding=>create(
source = itab1
destination = itab3
mapping = VALUE cl_abap_corresponding=>mapping_table( )
)->execute( EXPORTING source = itab1
CHANGING destination = itab3 ).
out->write( itab3 ).
out->display( ).
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
demo_corresponding=>main( ).See the results:
 |  |
4. Best Practice: Improve The Error Handling in your ABAP Code Using New Features in Exception Classes in Release 7.5x
When you add one of the following ABAP superclasses below:
- CX_STATIC_CHECK
- CX_DYNAMIC_CHECK
- CX_NO_CHECK
Then an ABAP exception class is automatically created.
The system IF_T100_MESSAGE is used to statically assign specific messages to an exception class that defines the semantics of the exception. The system interface IF_T100_DYN_MSG allows you to assign arbitrary messages of message classes to the exception by using the statement RAISE EXCEPTION ... MESSAGE ... at runtime.
If you want to see this new feature in action or if you did not understand very well what it's meaning, take a look at the demo programs listed below in your SAP NW 7.5x using t-code SE38.
- DEMO_RAISE_ERROR_MESSAGE
- DEMO_RAISE_EXCEPTION
- DEMO_RAISE_MESSAGE
- DEMO_RAISE_MESSAGE_GLOBAL
The code below is the demo_raise_message_error program, pay attention in the code inside of the red blocks:
If you want to get access to text code click here or click here to get the entire documentation about this topic.
More explanation about this tops in the Horst Keller's blog.
5. Best Practice: Right Usage of The Open SQL in Release 7.50
Of course the Open SQL is getting more and more powerful, in other words, SAP has been increased coverage of the SQL Standard in Open SQL.
Features Overview
|  |
5.1 Best Practice: Make a Good Usage of The Expression UNION.
Look the following example:
REPORT demo_select_union.
CLASS demo DEFINITION.
PUBLIC SECTION.
CLASS-METHODS:
main,
class_constructor.
ENDCLASS.
CLASS demo IMPLEMENTATION.
METHOD main.
DATA(out) = cl_demo_output=>new( ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION DISTINCT
SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION DISTINCT
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3
INTO TABLE @DATA(result_distinct).
out->write( result_distinct ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION ALL
SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION ALL
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3
INTO TABLE @DATA(result_all).
out->write( result_all ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION ALL
SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION DISTINCT
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3
INTO TABLE @DATA(result_all_distinct1).
out->write( result_all_distinct1 ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION ALL
( SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION DISTINCT
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3 )
INTO TABLE @DATA(result_all_distinct2).
out->write( result_all_distinct2 ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION DISTINCT
SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION ALL
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3
INTO TABLE @DATA(result_distinct_all1).
out->write( result_distinct_all1 ).
SELECT a AS c1, b AS c2, c AS c3, d AS c4
FROM demo_join1
UNION DISTINCT
( SELECT d AS c1, e AS c2, f AS c3, g AS c4
FROM demo_join2
UNION ALL
SELECT i AS c1, j AS c2, k AS c3, l AS c4
FROM demo_join3 )
INTO TABLE @DATA(result_distinct_all2).
out->write( result_distinct_all2 ).
out->display( ).
ENDMETHOD.
METHOD class_constructor.
DELETE FROM demo_join1.
DELETE FROM demo_join2.
DELETE FROM demo_join3.
INSERT demo_join1 FROM TABLE @( VALUE #(
( a = 'a1' b = 'b1' c = 'c1' d = 'd1' )
( a = 'a2' b = 'b2' c = 'c2' d = 'd2' )
( a = 'a3' b = 'b3' c = 'c3' d = 'd3' ) ) ).
INSERT demo_join2 FROM TABLE @( VALUE #(
( d = 'a1' e = 'b1' f = 'c1' g = 'd1' )
( d = 'a2' e = 'b2' f = 'c2' g = 'd2' )
( d = 'a3' e = 'b3' f = 'c3' g = 'd3' ) ) ).
INSERT demo_join3 FROM TABLE @( VALUE #(
( i = 'a1' j = 'b1' k = 'c1' l = 'd1' )
( i = 'i1' j = 'j1' k = 'k1' l = 'l1' )
( i = 'i2' j = 'j2' k = 'k2' l = 'l2' ) ) ).
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
demo=>main( ).
Note: This example can be available in your NW 7.5x.
See the results below:
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Understanding the results:
Four columns of the same type from result sets from three database tables DEMO_JOIN1, DEMO_JOIN2 and DEMO_JOIN3 are combined to make multiple SELECT statements using UNION. The database tables are filled in the static constructor.
- The first statement shows the default behavior with addition DISTINCT. No rows are inserted from database table DEMO_JOIN2 and one row is not inserted from database table DEMO_JOIN3 because these rows already exist.
- The second statement shows the behavior with addition ALL. All the rows from the three result sets are combined into one result set without removing any rows.
- The third statement contains addition ALL in the first UNION and contains DISTINCT in the second union. Addition DISTINCT deletes all duplicate rows, including the rows created using addition ALL. Therefore the result is the same as in the first statement.
- The fourth statement is the same as the third - except that parentheses have been inserted here. First, the parentheses are evaluated. Addition DISTINCT now takes effect in the parentheses and removes the first row from DEMO_JOIN3. Afterwards the result set of the parentheses is completely inserted into the result set of DEMO_JOIN1.
- The fifth statement contains addition DISTINCT in the first UNION and contains ALL in the second union. In the first union, no rows are taken from DEMO_JOIN2 because all the rows already exist. Next, all the rows are inserted from DEMO_JOIN3.
- The sixth statement is the same as the fifth - except that parentheses have been inserted here. Once the parentheses have been evaluated, the corresponding result set contains all rows from DEMO_JOIN2 and DEMO_JOIN3. In the union with rows from DEMO_JOIN1, all duplicate rows are removed using DISTINCT; the result is the same as with the first statement.
Source: https://help.sap.com/doc/abapdocu_750_index_htm/7.50/en-US/index.htm?file=abapunion_clause.htm
5.2 Best Practice: Improve Your Code with Sub-queries as Data Source of INSERT. See The Example Below.
The example below shows the statement INSERT with the addition FROM SELECT, in other words, it inserts data from another select instruction.
REPORT demo_insert_from_select.
CLASS demo DEFINITION.
PUBLIC SECTION.
CLASS-METHODS main.
ENDCLASS.
CLASS demo IMPLEMENTATION.
METHOD main.
"INSERT FROM TABLE
SELECT
FROM scarr AS s
INNER JOIN spfli AS p ON s~carrid = p~carrid
FIELDS s~mandt,
s~carrname,
p~distid,
SUM( p~distance ) AS sum_distance
GROUP BY s~mandt, s~carrname, p~distid
INTO TABLE @DATA(temp).
INSERT demo_sumdist_agg FROM TABLE @temp.
SELECT * FROM demo_sumdist_agg
ORDER BY carrname, distid, sum_distance
INTO TABLE @DATA(insert_from_table).
DELETE FROM demo_sumdist_agg.
"INSERT FROM SELECT
INSERT demo_sumdist_agg FROM
( SELECT
FROM scarr AS s
INNER JOIN spfli AS p ON s~carrid = p~carrid
FIELDS s~carrname,
p~distid,
SUM( p~distance ) AS sum_distance
GROUP BY s~mandt, s~carrname, p~distid ).
SELECT * FROM demo_sumdist_agg
ORDER BY carrname, distid, sum_distance
INTO TABLE @DATA(insert_from_select).
DELETE FROM demo_sumdist_agg. "GTT
IF insert_from_select = insert_from_table.
cl_demo_output=>new( )->write(
`Same data inserted by FROM TABLE and FROM SELECT:`
)->display( insert_from_select ).
ENDIF.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
demo=>main( ).The database table DEMO_SUMDIST_AGG is filled with aggregated data from the tables SCARR and SPFLI.
- First, a standalone SELECT statement is used to read the aggregated data into an internal table and then the statement INSERT is used to write it to the database table. This requires two database reads and the transport of the data between the database server and application server.
- The same SELECT statement is then used directly as a subquery in the INSERT statement. Only a single database read and no transport of data between the database server and application server is then required.
The result of both INSERT statements is the same. DEMO_SUMDIST_AGG is a global temporary table (GTT), which means that its content must be deleted before the results are produced (since this creates an implicit database commit).
Source: https://help.sap.com/doc/abapdocu_750_index_htm/7.50/en-US/index.htm?file=abeninsert_from_select_abe...
5.3 Best Practices: Open SQL Performance in ABAP 7.5
There are three best practices which can be combined to improve the performance for Open SQL in ABAP 7.5X, see below:
- Keep the number of hits low
You can use specific conditions to restrict the set to those rows actually needed, it will help you to keep the set of selected rows as small as possible. - Keep the data volume low
A restricted number of the columns always can improve the performance, therefore you should request only the columns which will be really used, no superfluous columns. In the same way, you can use aggregate functions to reduce the volume of data. - Keep the number of reads low
Mass operations are better than single operations, therefore the Open SQL statements should not be used within loops. Instead, joins, views, or subqueries can be used when reading multiple database tables.
5.4 Best Practice: Use The New Open SQL Functions in Order to Reduce the Number of Operations in ABAP. See the functions below:
- New numeric function ROUND: it rounds numeric values.
- New string functions: CONCAT, LPAD, LENGTH, LTRIM, RTRIM, REPLACE, RIGHT and SUBSTRING.
Take a look at: https://blogs.sap.com/2015/11/27/abap-language-news-for-release-750/
6. Best Practices: Be Aware and Understand How to Use CDS Views in Your Projects and Save Time.
The CDS views are one of the best innovations delivered by SAP in the last years. It is really powerful and the advanced users and developers should take advantages.
You can get more information about CDS Views here.
if you are not familiar with CDS Views, try the links below, they really will help you to understand the CDS views.
- https://blogs.sap.com/2016/05/09/how-to-create-smart-templates-annotations-within-cds-views-part-1/
- http://sapinsider.wispubs.com/Assets/Articles/2015/October/SPI-enhanced-ABAP-development-with-Core-D...
- https://blogs.sap.com/2016/10/19/trouble-shooting-cds-views/
- https://blogs.sap.com/2016/10/19/modularizing-cds-annotations/
The connectivity with SAP HANA and the facility to publish CDS views as OData Service are really great features . You can find a good example in the following blog from Raja Prasad Gupta: How to create ABAP CDS view and OData with SAP Annotations.
Also you can find more information about CDS Views and Odata in SAP Help.
| Note: |
|
Do you want to read more about CDS Annotations? So, click here.
6.1 Best Practice: Improve Security of Your CDS Views using ABAP CDS Access Control. Take a look in the following links:
- Help.sap.com
- ABAP CDS Access Control in Horst Keller's Blog
6.2 Best Practice: Extend your CDS Views Instead of Creating New CDS views. Link .
6.3 Best Practice: Improve Readability in Your CDS Views. Follow the link.
6.4 Use The Dependency Analyzer to Evaluate The Relationships and Complexity of CDS Entity With Regards to its SQL Definition.
The Dependency Analyzer helps you to understand SQL dependencies and complexity that might negatively affect the performance of your query.
| Tab | Screenshot |
| Dependency Tree: Displays SQL dependencies of a CDS view on other database objects. |  |
SQL Dependency Graph: Displays dependencies in a graphical map. | 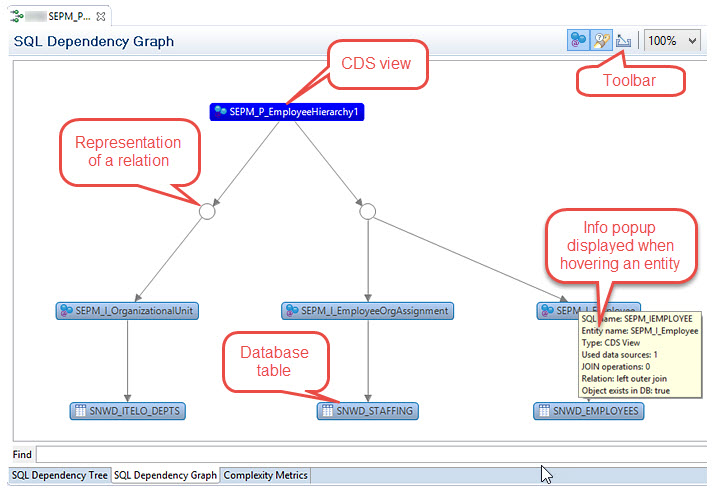 |
Complexity Metrics: Displays a statistical summary of selected key figures (such as used data sources, SQL operations, function calls, and expressions). | No IMAGE |
Analyzing Dependencies in Complex CDS Views.
7. Best Practice: Keep your ABAP Tools up to date. In September 2017 SAP released the latest version (2.83) of the document: "Installing ABAP Development Tools for SAP". This document will support you on the installation of ABAP Develpoment Tools.
Link to document.
8. Best Practice: Understand Which Version of ABAP Development Tools is Related to each Version of SAP Netweaver.
The following table gives you an overview of the released ADT versions and ABAP back ends:
| SAP NetWeaver 7.4 | SAP NetWeaver 7.5 | SAP NetWeaver AS for ABAP 7.51 innovation package | SAP NetWeaver AS for ABAP 7.52 | ABAP Development Tools (Client) |
|---|---|---|---|---|
| - | - | - | SP00 | Version ADT 2.83 |
| - | - | SP03 | Version ADT 2.80 | |
| - | - | SP02 | Version ADT 2.77 | |
| - | - | SP01 | Version ADT 2.73 | |
| - | SP00 | Version ADT 2.68 | ||
| - | SP04 | Version ADT 2.64 | ||
| - | SP03 | Version ADT 2.60 | ||
| - | SP02 | Version ADT 2.58 | ||
| - | SP01 | Version ADT 2.54 | ||
| - | SP00 | Version ADT 2.51 | ||
| SP12 | Version ADT 2.48 | |||
| SP11 | Version ADT 2.44 | |||
| SP10 | Version ADT 2.41 | |||
| SP09 | Version ADT 2.36 | |||
| SP08 | Version ADT 2.31 | |||
| SP07 | Version ADT 2.28 | |||
| SP06 | Version ADT 2.24 | |||
| SP05 | Version 2.19 |
Link to Source.
9. Best Practice: Be aware of the S/4 HANA and ABAP Programming Model.
The following link give you the direction to Carine Tchoutouo Djomo's Blog. There you will find a lot of information regarding the S/4 HANA and ABAP Programming Model. It includes examples and videos: LINK
- SAP Managed Tags:
- ABAP Development
17 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
3 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
IBM watsonx
1 -
Integration & Connectivity
10 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
13 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
15 -
User Experience
5
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |