Many companies currently complement their existing relational data warehouses with big data components, such as Spark, HDFS, Kafka, S3, ... This leads to a new form of data warehouse (DW) that we call big data warehouse (BDW). This blog elaborates how BW/4HANA and the SAP Data Hub (DH) are a perfect match for building a BDW.
Many companies currently complement their existing relational data warehouses with big data components, such as Spark, HDFS, Kafka, S3, ... This leads to a new form of data warehouse (DW) that we call big data warehouse (BDW). This blog elaborates how BW/4HANA and the SAP Data Hub (DH) are a perfect match for building a BDW.
The idea of a BDW is prevailing in many companies and industries. This blog describes a BDW built at Netflix, this one a BDW at Sears. Many more can be found on the web. All those examples show how big data storage and processing environments complement traditional relational data warehouses by providing
- an easy way to process semi- and unstructured data, such a photos, videos, sound, text,
- an inexpensive storage for fine granular data, e.g. from sensors and logs.
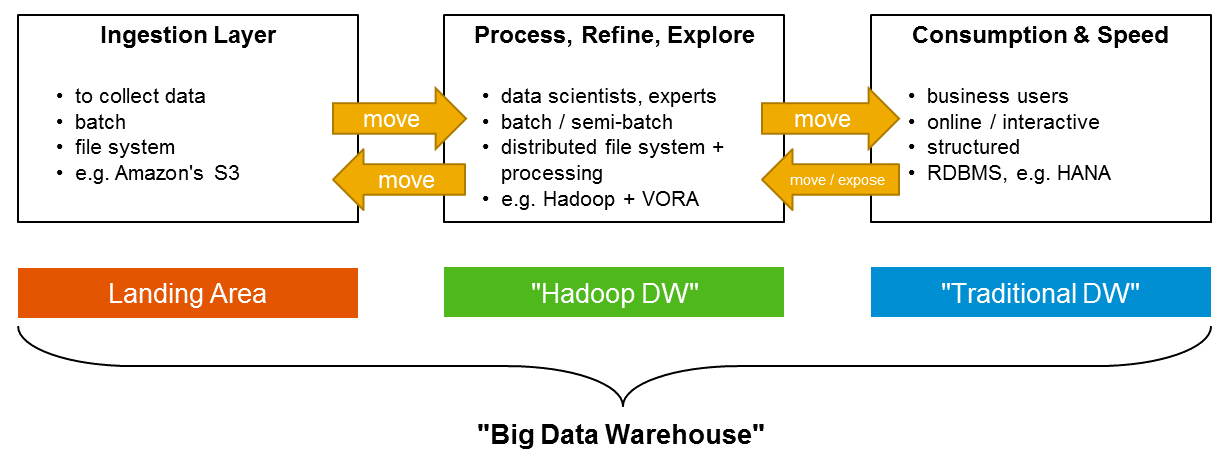
Figure 1 shows a generic setup of a BDW. Usually, there are 2 to 3 storage layers involved; sometimes, the first two are collapsed into one:
- an ingestion layer: inexpensive storage to collect data from many sources, e.g. thousands of sensors; Amazon's S3 is frequently used here,
- a processing and refinement layer for distributed processing of large and/or many files,
- a relational DW: this layer serves to provide semantically rich and well structured data to business users who use analytic clients tools for interactive analyses.

Fig. 1: Many BDWs follow the pattern of these storage and processing layers.
Many SAP customers are on the same trajectory as described in the Netflix and Sears examples. All of them have run a relational DW for many years and are now evolving and complementing it with big data components. BW and BW-on-HANA are capable to play the role of the relational DW in such an environment through various connection options. However, BW/4HANA's ambition is to excel this and be well integrated with SAP's Data Hub. The latter manages the ingestion and processing layers to the left of figure 1. This is outlined in figure 2 which represents the pattern of figure 1 implemented with SAP software components.
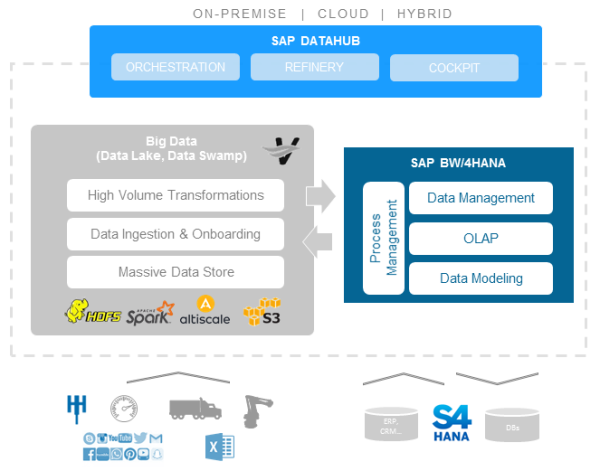
Fig. 2: BW/4HANA and SAP's Data Hub combined.
Now, what does this tight integration between BW/4HANA and SAP's Data Hub mean? What are the specifics? This is shown in figure 3 and comprises the following features:
- Workflows between the 2 environments can be mutually triggered: the Data Hub's data pipeline can be part of BW/4HANA's process chains and vice versa.
- Data movement between BW/4HANA and the Data Hub - or technically: between HANA and VORA - is highly optimized and aligned for performance (e.g. align data types thereby reducing overheads through type casting).
- The repositories of BW/4HANA and the Data Hub will be integrated and interoperate to enable common transports, lineage and impact analysis.
- In the area of data tiering, VORA is leveraged for archiving (cold store) of BW/4HANA data with high data throughput and fast read access.
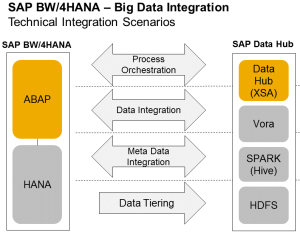
Fig. 3: Integration points between BW/4HANA and SAP's Data Hub.
What already exists today and what is planned to be shipped at what time is described in the roadmap shown in figure 4. Click the picture to enlarge.

Fig. 4: Roadmap of planned integration features for BW/4HANA and SAP's Data Hub.
Conclusion
In times of digitalization and the Internet-of-things, traditional and relational data warehouses are complemented with tooling, engines and infrastructure from the big data area. This leads to "big data warehouses" or, sometimes, also labeled "modern data warehouses". BW/4HANA and the SAP Data Hub are a perfect match in that respect.
This blog has also been published here and here. You can follow me on Twitter via @tfxz.