Hi!
In the blog, I’d like to share with you some thoughts about remodeling BEx-reports to equivalent ABAP CDS-view. To be concrete, I’ll tell about BW-reports with 2 structures: one is with key figures, and another one is with restricted and calculated elements. Let’s consider simple example.
Initial information.
Let’s we have ADSO ZSALES and BW-report on top of it.

BW-report has 2 structures. Structure in the rows contains 3 elements: GR1, GR2 and GR3.

GR1 element of the structure is defined like this.

GR2 is defined like this

And finally, GR3 is defined as subtraction GR1 from GR2

You need to create corresponding ABAP-CDS-view to return the same result as BW Query does. You can directly use generated ODATA-service over the CDS view in e.g. Smart Business applications. Of course, I understand there is a way to expose BW-query as ODATA service (“ex-Easy query”). But using the “CDS approach” provides more control over data handling and doesn’t depends on some easy-query
limitations.
Main part
In the example, you should create:
Five @VDM.viewType: #BASIC CDS views, where
- Three of them are @analytics.dataCategory : #DIMENSION CDS-views for texts of ZSALESREP, ZCUSTOMER and «virtual» GRx-analytics. Last one is to provide corresponding texts for GR1, GR2 and GR3 values.
- Fourth is @analytics.dataCategory: #CUBE CDS view to provide data foundation. It’s the central CDS view in the whole model.
- And the fifth is the also @analytics.dataCategory: #CUBE CDS view with associations dimension views with the central view.
One @VDM.viewType: #COMPOSITE view with
@analytics.dataCategory: #CUBE which provide texts labels for the fields and creates transient provider.
Finally, you create @VDM.viewType: #CONSUMPTION CDS view on top of #COMPOSITE view. The view has
@analytics.query: true and @OData.publish: true annotations which generate corresponding OData-service.
The whole model may look like in the diagram below.

There are several approaches to implement ZSALES CDS view. It based directly on transaction data which can be very large and located on different hosts in scale-out HANA configuration. So, the goal is to minimize number of large ZSALES table accesses.
With straightforward approach, your ZSALES CDS based on union of 2 additional CDS-views. 1
st provides necessary aggregation of ZSALESREP into groups GR1 and GR2. 2
nd CDS (which based on the 1
st) provides subtraction GR1 from GR2. There are 2 accesses to ZSALES ADSO table, which can be very large. In more complicated scenarios of grouping and calculations on data it can be much more such additional CDS-views with table access inside each of them.
Another approach is to create ZSALES CDS based on AMDP-procedure. Inside the procedure, you use HANA SQL Script where you can write on pure SQL more optimized SELECT-query. For example you can use WITH <subquery_name> AS (<subquery> ) SELECT … FROM <subquery_name> … UNION ALL SELECT … FROM <subquery_name> . In the case there are the only access to ZSALES ADSO table in <subquery>. In <subquery> you put all nessecary grouping of data and residual part of the SQL-SELECT-query is to perform calculation on data groups. SQL-SELECT-query below can illustrate this.
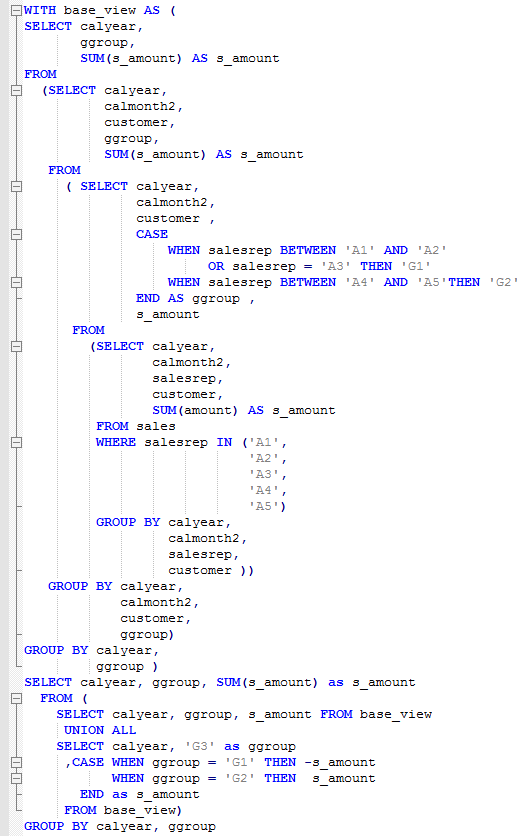
Same effect could be achieved when using intermediate variables in HANA procedure.
To conclude the blog, I have to say that the problem of replacing BW-query by CDS-view is required further investigations. Some conclusions can be disputable and I invite you for discussion here.
