
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Implementing the MNIST classification problem (the...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-01-2017
3:41 PM
Almost everyone who wants to learn more about machine learning (ML) sooner or later follows one of the tutorials solving the MNIST classification problem. The MNIST data set contains a large number of handwritten (labeled) digits and the goal is to perform image recognition on those images to detect the actual digit. In this blog post, we want to show how you can do this using the External Machine Learning (EML) component of the Application Function Library (AFL) just released with HANA2 SPS02 (for general highlights see this blog). The new EML-AFL allows to execute inference call requests from SAP HANA SQL and SQLScript against a Google Tensorflow Serving instance and the available models. The data to be processed can either be passed from SAP HANA to TensorFlow or a location link to where the data is to be found can be passed along with the call.
There is an excellent series of videos showing how to implement the MNIST classification problem on HANA, storing the images of as a 784-column table of floats. There’s nothing technically wrong with it, however the formatting of the MNIST data is unnecessarily awkward, because the video tutorial authors tried to change as little of the original model coding as possible. We would like to show an alternative approach using Googles recommended data format for TensorFlow called TFRecords. If you are not familiar with it yet, don’t worry, we’ll explain what you need to know about it.
The blog post has the following structure:
Train and export the TensorFlow model:
Setting up the system with all the necessary dependencies is not an easy task, however in the following we assume that this has already been done following one of the many blog posts and tutorials on this subject. Run the python program mnist_saved_model.py which will create a directory with a file saved_model.pb and a sub-directory call variables. To perform a quick check if the model was saved correctly and how the signature looks like, you can use the saved_model_cli tool. In our case, we stored the model in a file models/2, the corresponding command line for your unix shell looks like

Producing the output:

What does it tell me? It shows that the model contains two signatures. The first one is called ‘predict_images’ and expects a (raw) tensor of shape (-1,784), the -1 refers to an unspecified number of rows, and it returns a tensor ‘scores’ containing the results of the classification with shape (-1,10). The second signature is called ‘serving_default’ and the input is a tensor ‘inputs’ with unknown_rank named tf.example. The outputs are ‘classes’ and ‘scores’ with the specified shapes and data types.
So far everything looks good. Now the question is, how can I feed data to the graph using the ‘serving_default’ signature? This will be explained in the next section.
Googles standard TensorFlow data format:
The two main methods of feeding data into a TensorFlow graph are either though the feed_dict argument to a run() call, and this is how most of you are usually doing it, or reading the data from files. You can read text files but more efficient is the use of binary file formats. The Googles recommended file format for TensorFlow is .tfrecords. Files of that format contain records of the form tf.train.Example which are then serialized via protocol buffers to a string. A lot of information in one sentence, let’s parse it one by one: tf.train.Example is a data format for storing data for inference and training. It contains a key-value store (features); where each key (string) maps to a feature message (which in our case is a FloatList). For more information see https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto
TensorFlow’s file formats are based on Protocol Buffers also called protobuf, which generates classes for the various programming languages to handle the data in an efficient way. Storing records in that format makes up a .tfrecords file.
Now let’s use this in practice. The following code snipped loads the MNIST data sets, converts them into a tf.example and saves the result in a file.

This creates a tf.example of the following form with 784 values for the pixels of the 28x28 images.

This completes the first step, converting the data into the format expected by the model signature, namely tf.example. Now we should be able to feed these records into the model via the command line interface

This will yield the result as described in the signature definition of the model namely ‘classes’ and ‘scores’ for the two records contained in our pickled file:

The next step is store the serialized data in a HANA table. Since we are dealing with binary data a natural way to store the data will be a BLOB (binary large object). To move the data from our python environment to the HANA world, the python connector pyhdb comes in pretty handy. We just open a connection and write the data (in this case for a single record) into a previously created HANA table, with one column defined as BLOB.

To recap, we now know what the standard format for feeding data into a TensorFlow graph is and how to converted the MNIST dataset (well at least some records of it) into this format. We saved the data to a file and tested our model using the command line interface by feeding the records into the serving_default signature and received the expected output. Finally, we stored the data in a HANA table as a BLOB and now we should be ready to perform inference calls.
Calling the TensorFlow model from HANA using data inside HANA
For the following script to work you need to have the AFL-EML installed on your HANA instance and you need a TensorFlow Serving Server (version 0.5.1 or higher). Details on the installation are described here ( https://tensorflow.github.io/serving/setup). If you want to save yourself the trouble of building TensorFlow serving from scratch, RPMs of TensorFlow model servers for SLES12 (OpenSUSE or Fedora should also work) can be found here.
Bevor the ‘MNIST’ procedure can be called, the appropriate table types for the input and output tables need to be created. With that information, the wrapper procedure can be called which creates the actual ‘MNIST’ procedure. Additionally, the model server configuration needs to be specified which is depicted in the following slide:

Now, we have assembled all the bits and pieces to perform the MNIST classification call. The input data (our tf.example records) are stored as a BLOB in table ‘IMAGES’. The output will be stored in table ‘SCORES’ containing the classes and the scores. The complete SQL script code is shown here.

The actual call is performed in line CALL MNIST(CALL_PARAMS, IMAGES, SCORES) with overview. The results are stored in the tables SCORES and a select will produce the following output:

So finally, we got our classification results!! We could show that the image number 10 from the mnist.test.images data set which looks like this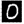 is indeed with 98% confidence the digit 0. This concludes the MNIST example and it illustrates the concepts which should be applicable to a much broader range of applications. The only prerequisite is, that you can train a TensorFlow model for your problem and that you can save it in the saved_model format. This enables you to deploy it to a TensorFlow Serving server. Datasets converted to tf.Example format and stored as a BLOB in a HANA table could then be used to query the model for inference calls. The results are written into HANA tables and are available for further processing. Alternatively, you could store images in a separate directory and store a reference like image ID in HANA, then pass the ID to the TensorFlow graph which will then load the specified image for further processing. This opens the door to many interesting use cases which we will explore in subsequent blog posts. Stay tuned …..
is indeed with 98% confidence the digit 0. This concludes the MNIST example and it illustrates the concepts which should be applicable to a much broader range of applications. The only prerequisite is, that you can train a TensorFlow model for your problem and that you can save it in the saved_model format. This enables you to deploy it to a TensorFlow Serving server. Datasets converted to tf.Example format and stored as a BLOB in a HANA table could then be used to query the model for inference calls. The results are written into HANA tables and are available for further processing. Alternatively, you could store images in a separate directory and store a reference like image ID in HANA, then pass the ID to the TensorFlow graph which will then load the specified image for further processing. This opens the door to many interesting use cases which we will explore in subsequent blog posts. Stay tuned …..
There is an excellent series of videos showing how to implement the MNIST classification problem on HANA, storing the images of as a 784-column table of floats. There’s nothing technically wrong with it, however the formatting of the MNIST data is unnecessarily awkward, because the video tutorial authors tried to change as little of the original model coding as possible. We would like to show an alternative approach using Googles recommended data format for TensorFlow called TFRecords. If you are not familiar with it yet, don’t worry, we’ll explain what you need to know about it.
The blog post has the following structure:
- You need the mnist_saved_model.py to perform training and to save the model in a special format (saved_model) which can later be deployed on the TensorFlow Serving Server. This python script is part of the MNIST tutorial on https://tensorflow.github.io/serving/serving_basic.html. We show how to read the signature of the model using a command line tool provided by Google.
- In the second section, we explain what TFRecords are, how we can use them and how to get the data (the MNIST hand written images) into a HANA table.
- When a server is running, listening for inference requests and the images are stored in a HANA table, then you are ready to perform the actual inference call. This will feed the data into the TensorFlow graph and you can review the results in a HANA table. We show how this is being done.
Train and export the TensorFlow model:
Setting up the system with all the necessary dependencies is not an easy task, however in the following we assume that this has already been done following one of the many blog posts and tutorials on this subject. Run the python program mnist_saved_model.py which will create a directory with a file saved_model.pb and a sub-directory call variables. To perform a quick check if the model was saved correctly and how the signature looks like, you can use the saved_model_cli tool. In our case, we stored the model in a file models/2, the corresponding command line for your unix shell looks like
Producing the output:
What does it tell me? It shows that the model contains two signatures. The first one is called ‘predict_images’ and expects a (raw) tensor of shape (-1,784), the -1 refers to an unspecified number of rows, and it returns a tensor ‘scores’ containing the results of the classification with shape (-1,10). The second signature is called ‘serving_default’ and the input is a tensor ‘inputs’ with unknown_rank named tf.example. The outputs are ‘classes’ and ‘scores’ with the specified shapes and data types.
So far everything looks good. Now the question is, how can I feed data to the graph using the ‘serving_default’ signature? This will be explained in the next section.
Googles standard TensorFlow data format:
The two main methods of feeding data into a TensorFlow graph are either though the feed_dict argument to a run() call, and this is how most of you are usually doing it, or reading the data from files. You can read text files but more efficient is the use of binary file formats. The Googles recommended file format for TensorFlow is .tfrecords. Files of that format contain records of the form tf.train.Example which are then serialized via protocol buffers to a string. A lot of information in one sentence, let’s parse it one by one: tf.train.Example is a data format for storing data for inference and training. It contains a key-value store (features); where each key (string) maps to a feature message (which in our case is a FloatList). For more information see https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto
TensorFlow’s file formats are based on Protocol Buffers also called protobuf, which generates classes for the various programming languages to handle the data in an efficient way. Storing records in that format makes up a .tfrecords file.
Now let’s use this in practice. The following code snipped loads the MNIST data sets, converts them into a tf.example and saves the result in a file.
This creates a tf.example of the following form with 784 values for the pixels of the 28x28 images.
This completes the first step, converting the data into the format expected by the model signature, namely tf.example. Now we should be able to feed these records into the model via the command line interface
This will yield the result as described in the signature definition of the model namely ‘classes’ and ‘scores’ for the two records contained in our pickled file:
The next step is store the serialized data in a HANA table. Since we are dealing with binary data a natural way to store the data will be a BLOB (binary large object). To move the data from our python environment to the HANA world, the python connector pyhdb comes in pretty handy. We just open a connection and write the data (in this case for a single record) into a previously created HANA table, with one column defined as BLOB.
To recap, we now know what the standard format for feeding data into a TensorFlow graph is and how to converted the MNIST dataset (well at least some records of it) into this format. We saved the data to a file and tested our model using the command line interface by feeding the records into the serving_default signature and received the expected output. Finally, we stored the data in a HANA table as a BLOB and now we should be ready to perform inference calls.
Calling the TensorFlow model from HANA using data inside HANA
For the following script to work you need to have the AFL-EML installed on your HANA instance and you need a TensorFlow Serving Server (version 0.5.1 or higher). Details on the installation are described here ( https://tensorflow.github.io/serving/setup). If you want to save yourself the trouble of building TensorFlow serving from scratch, RPMs of TensorFlow model servers for SLES12 (OpenSUSE or Fedora should also work) can be found here.
Bevor the ‘MNIST’ procedure can be called, the appropriate table types for the input and output tables need to be created. With that information, the wrapper procedure can be called which creates the actual ‘MNIST’ procedure. Additionally, the model server configuration needs to be specified which is depicted in the following slide:
Now, we have assembled all the bits and pieces to perform the MNIST classification call. The input data (our tf.example records) are stored as a BLOB in table ‘IMAGES’. The output will be stored in table ‘SCORES’ containing the classes and the scores. The complete SQL script code is shown here.
The actual call is performed in line CALL MNIST(CALL_PARAMS, IMAGES, SCORES) with overview. The results are stored in the tables SCORES and a select will produce the following output:
So finally, we got our classification results!! We could show that the image number 10 from the mnist.test.images data set which looks like this
- SAP Managed Tags:
- Machine Learning,
- SAP HANA
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
400 -
Workload Fluctuations
1
Related Content
- Augmenting SAP BTP Use Cases with AI Foundation: A Deep Dive into the Generative AI Hub in Technology Blogs by SAP
- Part 2: Deliver real-life use cases with SAP BTP – Returnable Packaging – SAP AI Core in Technology Blogs by SAP
- Unlocking Data Value #3: Machine Learning with SAP in Technology Blogs by SAP
- Data Discovery using ChatGPT in SAP Analytics Cloud in Technology Blogs by Members
- Integrating GPT Chat API with SAP CAP for Advanced Text Processing in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 |