
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- My CDS view self study tutorial – Part 14 CDS view...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-23-2017
6:25 AM
- Part1 – how to test odata service generated by CDS view
- Part2 – what objects are automatically generated after you activate one CDS view
- Part3 – how is view source in Eclipse converted to ABAP view in the backend
- Part4 – how does annotation @OData.publish work
- Part5 – how to create CDS view which supports navigation in OData service
- Part6 – consume table function in CDS view
- Part7 – unveil the secret of @ObjectModel.readOnly
- Part8 – my summary of different approaches for annotation declaration and generation
- Part9 – cube view and query view
- Part10 – How does CDS view key user extensibility work in S4/HANA
- Part11 – CDS view test double framework
- Part12 – CDS view source code count tool
- Part13 – CDS view authorization
- Part14 - this blog
Table of Content
- Note
- Test CDS views used in this blog
- How to do performance analysis using HANA studio planviz
- All weird performance behaviors get clarified
- 1. different product ID leads to greatly different performance result
- 2. select vs select distinct
- 3. Performance Gap between ST05 trace and the planViz opened in HANA Studio
I am a newbie in CDS performance area and frequently I meet with some "weird" performance behavior which makes me really confused. After I consulted with performance experts, it turns out that all those "strange" behavior has their root cause and could be well explained - no strange at all but just works as designed! I will share with my finding and learning with you through this blog.
Note
1. This blog is written based on the prerequisite that the Netweaver is connected to a HANA DB whose version listed below:

2. The test CDS views I used in this blog are NOT part of SAP standard delivery, so you could NOT find them in any SAP system.
Test CDS views used in this blog
The hierarchy of test CDS views used in this blog is listed below.
1. CRMS4D_SALE_I and CRMS4D_SVPR_I are two item database tables which store the service order line item with type "Sales Item" and "Service Item". The record numbers of these two tables are also listed in the picture.

2. How the upper-most CDS view CRMS4V_C_ITEM_OPT2 is consumed:
According to different search criteria selected by end user, different SQL statement is populated dynamically:


3. CRMS4V_I_ITEM_WO_STATUS_TEXT is just an union of two item database tables whose source code could be found from here.
4. CRMS4V_C_ITEM_OPT_TXT_DELAY: in search result UI, the status description is displayed:

However in database table, the status value is modeled as checkbox,

on the other hand in CRM the status text is defined against status internal key with format I<four number digit>, so the CDS view CRMS4V_C_ITEM_OPT_TXT_DELAY is used to convert the boolean value to the expected internal I format, whose source code could be found from here.

5. CRMS4V_C_ITEM_OPT2: consumed by ABAP code to serve the search request triggered from end UI.
How to do performance analysis using HANA studio planviz
- switch on ST05 trace.
- perform search against product id. I write a simple report to trigger the search from backend:
PARAMETERS: pid TYPE comm_product-product_id OBLIGATORY DEFAULT 'AB0000000042',
maxhit TYPE int4 OBLIGATORY DEFAULT 100.
DATA: lt_selection_parameter TYPE genilt_selection_parameter_tab,
ls_query_parameters TYPE genilt_query_parameters,
ls_selection_parameter TYPE genilt_selection_parameter.
DATA(lo_core) = cl_crm_bol_core=>get_instance( ).
lo_core->load_component_set( 'ONEORDER' ).
ls_selection_parameter = VALUE #( attr_name = 'PRODUCT_ID' sign = 'I' option = 'EQ' low = pid ).
APPEND ls_selection_parameter TO lt_selection_parameter.
ls_query_parameters-max_hits = maxhit.
cl_crm_order_timer=>start( ).
TRY.
DATA(lo_collection) = lo_core->dquery(
iv_query_name = 'BTQSrvOrd'
it_selection_parameters = lt_selection_parameter
is_query_parameters = ls_query_parameters ).
CATCH cx_root INTO DATA(cx_root).
WRITE:/ cx_root->get_text( ).
RETURN.
ENDTRY.
cl_crm_order_timer=>stop( 'Search by Product ID name' ).
WRITE:/ |Number of Service Orders found: { lo_collection->size( ) }|.3. Execute the search and deactivate the trace. Now the CDS view read operation could be found from the trace.
Edit->Display Execution Plan -> For Recorded Statement:


4. In HANA studio, open this plv file:


With plv file opened in HANA studio, all my previous doubt could be clarified.
All weird performance behaviors get clarified
With trace file available, all weird behavior could be well explained now.
1. different product ID leads to greatly different performance result
For product ID 3D0000000002, only 0.1 second is used to finish the query, while for product ID AB0000000042, 231 seconds is consumed.


First open plv file for product ID 3D0000000002, the trace shows there are only 4123 records which fulfills the condition ORDERED_PROD = '3D0000000002':

This is consistent with what I have found in SE16:

And for CRMS4D_SVPR_I, there are 20000 records whose product_id = '3D0000000002'. So after union, totally 4123 + 20000 = 24123 records are sent for upper process.
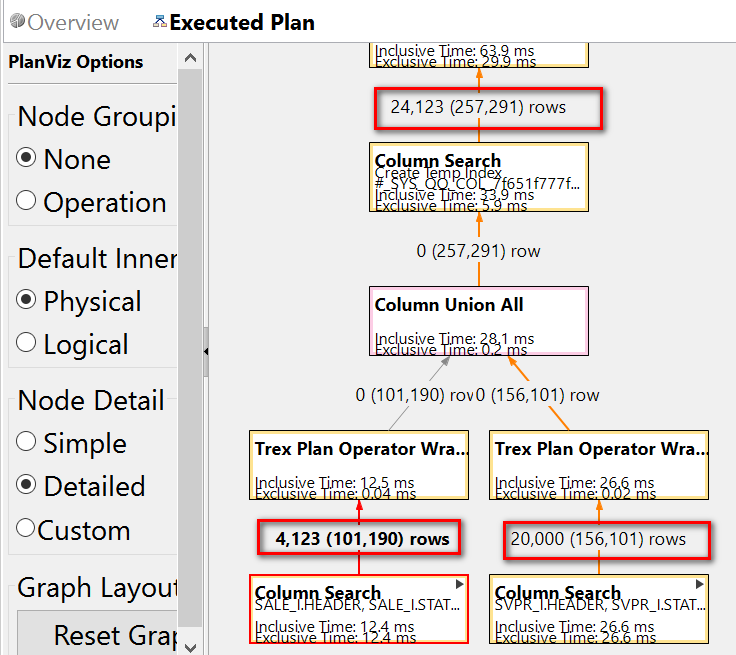
finally these 24123 records are used to get 100 distinct records as result.
Now let's turn to the trace file for product ID AB0000000042.
A huge number of records (182,272,424 ) are fetched from database table:


So this search criteria does not make too much sense from business point of view - more search parameter is necessary to limit the records retrieved from database table for further process.
2. select vs select distinct
Execute below two statements in HANA studio seperately:
case 1: SELECT distinct "OBJECT_ID" FROM "SAPQGS"."CRMS4VCITEMODL2" WHERE "PRODUCT_ID" = 'AB0000000042' limit 100
case 2: SELECT "OBJECT_ID" FROM "SAPQGS"."CRMS4VCITEMODL2" WHERE "PRODUCT_ID" = 'AB0000000042' limit 100
Mark the SQL statement in HANA studio, "Visualize Plan->Execute":

The execution plan shows that the limit operation is done based on the huge number of records which leads to a comparatively poor performance - 1.1 seconds.

In the case 2 where the distinct keyword is removed, due to the optimization of HANA execution engine, the limit operation is performed immediately during the time when the records are retrieved from database table, so only these 100 records are sent to subsequent process, which ends up with a comparatively good performance. This behavior is so called "limit push down", which is not supported if distinct keyword is involved.

3. Performance Gap between ST05 trace and the planViz opened in HANA Studio
I have once observed a "strange" behavior:
When I perform the query on my CDS view with two search parameters: product id and sold to party name, it will take on average 16~18 seconds to finish the query.


When I download the trace file, open and execute it in HANA studio,

Only around 2 second is consumed in HANA studio.


What makes this big difference when CDS view is consumed in ABAP and HANA layer with exactly the same SQL statement?
In fact the statement is not exactly the same at all.
In ABAP layer, the limit is specified dynamically - not fixed in the design time.

However in HANA studio, the limit 100 is hard coded.

When I change the dynamically specified limit operation in ABAP with fixed limit, the performance in ABAP is now consistent with HANA studio:


The reason is, it is possible for HANA optimizer as a kind of cost-based optimizer to apply PRELIMIT_BEFORE_JOIN rule to constant LIMIT operator during execution plan generation for the non-prepared statement. However due to technical reasons, it is not possible for parameterized LIMIT operator, since it is impossible for HANA optimizer to estimate the cost of the statement containing parameterized LIMIT operator and decide the optimal plan based on the estimated cost - the optimization could not be applied unless we are well aware of how many records could be pruned with LIMIT operator.
- SAP Managed Tags:
- ABAP Development,
- ABAP Testing and Analysis,
- SAP HANA
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Start page of SAP Signavio Process Insights, discovery edition, the 4 pillars and documentation in Technology Blogs by SAP
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- Analyze Expensive ABAP Workload in the Cloud with Work Process Sampling in Technology Blogs by SAP
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |