
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- HowTo - Configure MDG / Master Data Governance Bus...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-29-2017
10:43 PM
Hello MDG & HANA Community,
in this blog entry, we will implement a duplicate check on the Business Partner (BP) entity in MDG. We will generate MDG HANA Search Views. In case you want to create your own SAP MDG HANA search view you can go through the official guides (e.g. MDG_Config_BP_90_SP00.pdf).We will also be using HANA Search Rule Sets to achieve a more fine-grained mode to identify duplicate records.
This will enable you to structure the duplicate check behavior exactly to your needs. Stopwords and term mappings additionally help to overcome limitations of the standard duplicate check where legal form abbreviations and their varieties such as S.A. and SA can be treated equally.
You can create and adapt the search behavior using search rule sets for all other entities as well. The business partner one is just an example used in here.
These are the steps we will follow:
1. Create HANA Development Package and generate your Search View
2. Create Search View
3. Create Match Profile for Duplicate Check
4. Activate the duplicate check for a certain entity type
5. Edit the generated HANA Search Rule Set (SRS)
6. HANA Search Rule Set Properties and Options
7. Refine Search Rule Set with Stopwords and Term Mappings
8. Duplicate Check / Search Rule Set – Testing/Troubleshooting/Refining
9. *HANA Search View Regeneration
10. Include Duplicate Check in MDG Change Request
Prerequisites:
- MDG 8.0 on a HANA DB
- MDG user to do customizing of Search and Duplicate Check
- HDB user
- MODELING / CONTENT_ADMIN role
- native development package maintenance privileges required: REPO.READ / REPO.EDIT_NATIVE_OBJECTS / REPO.ACTIVATE_NATIVE_OBJECTS / REPO.MAINTAIN_NATIVE_PACKAGES
- Sufficient nerves to sustain until the perfect duplicate check has been accomplished!
1. Create HANA Development Package and generate your Search View
The journey begins in the customizing section of MDG (TA MDGIMG). As the duplicate check of MDG harnesses HANA’s fuzzy search capabilities, you need an MDG search view that you create in the subsequent steps. In order to do that, do the following upfront:
You need to create a HANA development package (of course complying to your company-specific development guidelines, e.g. com.companyname.mdg.search) in which you want the search artifacts such as views and rule sets to be stored (in HANA – e.g. HANA Studio/HANA Dev. Workbench).
In our example we created a package Z_HANA_SEARCH_BP_ADDR
2. Create Search View
You can also refer to Steffen Ulmer’s blog entry to get some more detailed exposure on the search view generation:
https://blogs.sap.com/2017/02/16/howto...-configure-a-new-hana-search-view-for-mdg-m/comment-page-1/...
The example is for MDG-M, however the same procedure basically applies for all other entities.
Irrespective of Steffen's wonderful blog, the following will give you also guidance on how to do that:

Alternatively call transaction MDG_HDB_GEN_UI
Click on the standard search view “MDG_BS_BP_ADDRESS”.
Click on the white “page” symbol in order to copy the standard search view to “ZMDG_BS_BP_ADDRESS” or any other name in your customer namespace:
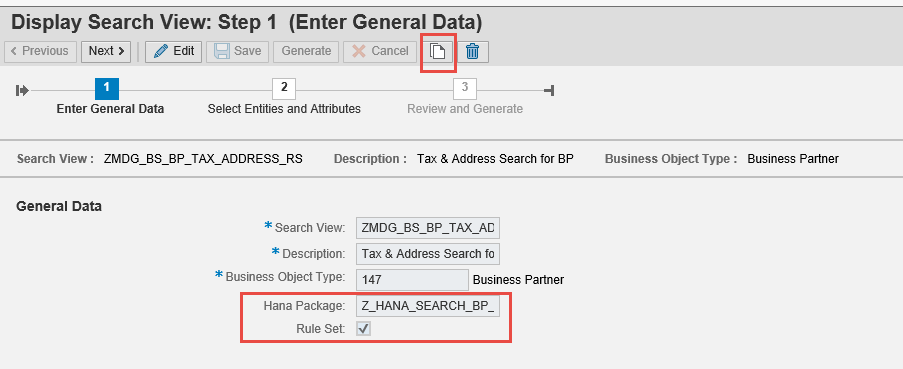
Open the created Z* search view and edit. Define the HANA package in which you want to store it. Also make sure to tick “Rule Set”.
Proceed to step 2 and choose the attributes you wish to take into account in your duplicate check:
Proceed to step 3, save and generate the search view + its rule set. This will trigger the creation of attribute views (standard attribute view + reuse attribute view which you can extend/change) on the HANA DB, as well as a search rule set artifact.
You can double check the outcome in HANA Studio in your development package. This summarizes what you should see:

3. Create Match Profile for Duplicate Check
Before you work on your rule set, you need to create a match profile for your search views.
Navigate to the following MDGIMG section

Select the Srch Mode HA = HANA and click on Match Profile on the left hand side menu.

Now cross-check if your HANA Search View is “registered” as a Search Application in MDG customizing. These entries are added automatically and do not require any manual adjustments.

Rule set Z_HANA_SEARCH_BP_ADDR:ZMDG_BS_BP_TAX_ADDRESS_RS_Rule_Set_USQL.searchruleset has been created
Define your match profile ID + Data Model BP in our case:

Define the relevant fields for your duplicate check scope. Keep in mind that you can use only the fields that you have selected in your HANA Search View.
The mandatory checkbox defines the fields that must be populated before a duplicate check will be executed. Ex. Attr describe attributes that can be shown in the duplicate check hitlist but will be ignored from within the duplicate check logic. Weight, Fuzziness and Sequence is according to my knowledge ignored when you use search rule sets.

4. Activate the Duplicate Check for a certain Entity Type (BP)
Navigate to the following MDGIMG entry:
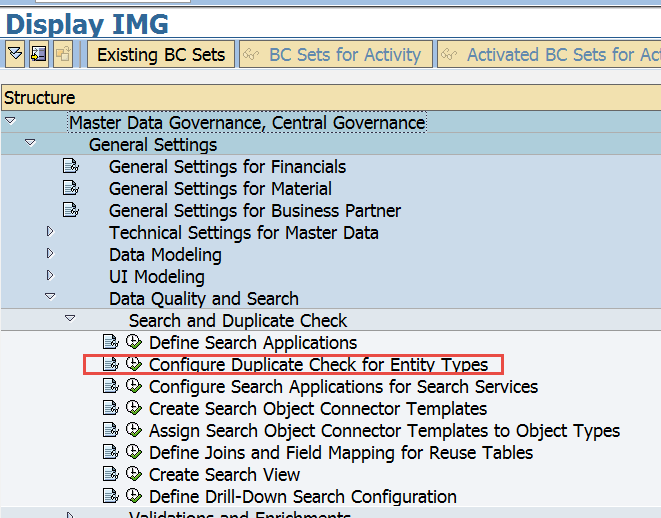
The included search help corresponds to the technical name of your HANA Search Views.

5. Edit the generated HANA Search Rule Set (SRS)
You are now able to access these objects from HANA Studio or the web based development workbench. Especially the search rule set (SRS) is eventually something you want to refine and redefine over time.
Having created search views + rule set, you are now able to access the ruleset via HANA Studio or by using the web based development workbench.
Here is some extract from the search developer guide that perfectly describes HANA search rule sets:
"The application can use search rules to store the rules as a configuration object in the SAP HANA database. Instead of embedding the rules in SELECT statements that are part of the application code, the application has to call a database procedure to process all rules defined in the configuration object.
This results in higher flexibility as the rules used within such a scenario are kept on DB level and can be adjusted without much effort."
The following screenshot depicts the final state of the search rule set I have created:

Working with rule sets require a proper understanding of HANA’s fuzzy search and respectively the properties that you want to take into account, it makes sense to familiarize yourself with section “FUZZY Search”/”Search Rules” of the HANA search developer guide of your HANA version.
6. HANA Search Rule Set Properties and Options
A good reference of how some of the properties influence the result set of search and correspondingly a duplicate check can be found in Roland Gremmelspacher’s blog entry:
Search rule sets offer you various properties and options, the type of your attribute/column decides which ones you get – either Text or String Column options (+ Date Column options).
In the case of MDG search views using rule sets, you might want to apply Text Column options on some of the attributes of your rule set. However, it depends on the requirements you have in regards to the duplicate check behavior which sort of property you want to employ.
Here’s an overview of the Text Column options (under the properties tab in HANA Studio):

In comparison to Text column options, you have a different and limited scope of properties for String Column:

As said - ultimately the data type of your attribute decides which column options you can go for.
This is only partially true because on columns of data type String, we can also enforce Text column options.
The following shows an error when taking Text Column Options for the wrong column type (you need a TEXT datatype which implicitly has got an FT-index, HANA creates by default a full text index on the following data types: TEXT/BINTEXT/SHORTTEXT, for all other, you must create the index manually, the system attaches a hidden column to the specified column.):

To realize using Text Column Options anyways in this example, you need to manually create a HANA full text index (FT-index) on the corresponding column on HANA table level. To sort out the fields/columns on which you need to apply this, you must find out which input tables shape the search rule set view (which is considered in the rule set definition section). Typically in MDG this comprises 2 base tables, one for the active and one for the staging area:
- View “SAPABAP”.”ZMDG_BS_BP_TAX_ADDRESS_RS_USQL” is the view you want to investigate – the view of your search rule Set:

- Go to the view definition, e.g. in _SYS_BIC schema. Open the view definition and find out which fields you need to take into account for the FT-index creation. A FT-index can easily be created with SQL.
Helpful:
Typically in MDG, one of your views included in the SRS would be termed similarly as the following:
„<SAPABAPSCHEMA>“.“/1MD/MD_____00J“
To create an FT-index you can use the following SQL :
CREATE FULLTEXT INDEX I_MC_NAME1 on "„<SAPABAPSCHEMA>"."<TABLE>" ( <FIELDNAME> ) FUZZY SEARCH INDEX ON FAST PREPROCESS OFF TEXT MINING OFF TEXT ANALYSIS OFF;
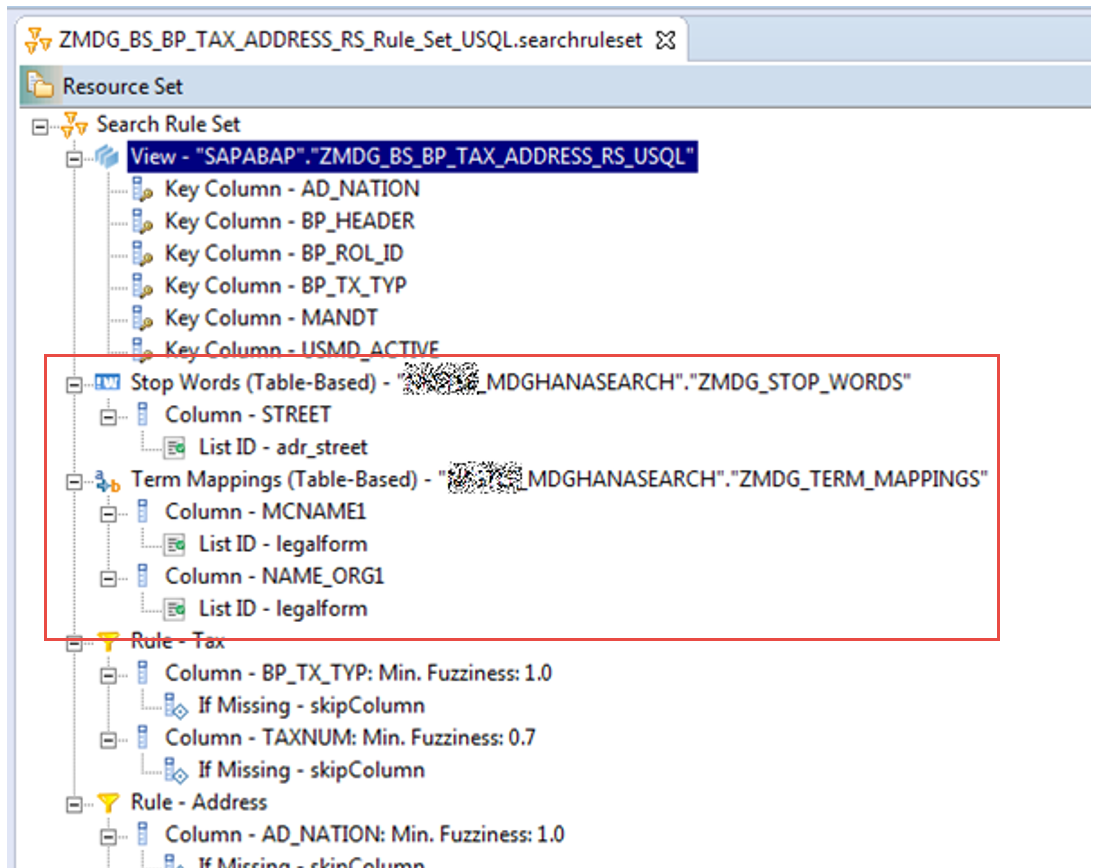
7. Refine Search Rule Set with Stopwords and Term Mappings
In our example we’d like to make use of a feature that is supported by HANA Fuzzy Search:
- Stopwords and Term Mappings
Stopwords enable you to define your own company-specific attributes such as “legalform” or “adr_street”, to which you can refer from an attribute within your search rule set (e.g. STREET1 to “adr_street” etc.).

Term mappings can be used to map e.g. one and the same legal form together, that is written or expressed differently in your data (e.g. GmbH, G.m.b.H, Gesellschaft mit beschränkter Haftung etc. – whatever users were able to enter 😉 ). Additionally, you can set a weight for a mapping in the term mapping table that will the search rule set will consider.

To realize that, you need to create two tables, complying to some pre-defined structure. This is described in the HANA Search Developer Guide.
http://help.sap.com/hana/SAP_HANA_Search_Developer_Guide_en.pdf
As you can see in our SRS there’s a “ZMDG_STOP_WORDS” and “ZMDG_TERM_MAPPINGS” table involved. Consider that you need to fill the stopwords + term mappings tables yourself, according to your requirements/context.
For more details on stopwords and term mappings please refer to the HANA Search Developer Guide.
8. Duplicate Check / Search Rule Set – Testing/Troubleshooting/Refining
Of course you can test your SRS within an MDG change request, however the following approach is much more convenient when it comes to refining and understanding the detailed behavior:
To troubleshoot and test your SRS, you can use the following syntax (adapted to your SRS and attribute names). You can use it to optimize the behavior of your duplicate check and figure out e.g. the ranking of your search results.
To get a predefined rule set specific SQL generated automatically make a right-click on very first node in your search rule set “Search Rule Set” à “Copy SQL Statement to Clipboard”. Then paste it into a SQL console and adjust according to your needs.
CALL SYS.EXECUTE_SEARCH_RULE_SET('
<query limit="500">
<ruleset name="Z_HANA_SEARCH_BP_ADDR:
ZMDG_BS_BP_ADDRESS_RS_Rule_Set_USQL.searchruleset"/>
<column name="NAME_ORG1">Sample Company Ltd.</column>
<column name="STREET">sample street</column>
<column name="REF_POSTA">DE</column>
<column name="MCNAME1">Sample Company Ltd.</column>
<column name="POST_COD1">20000</column>
<column name="CITY1">Sample City</column>
</query>');
If you come across an error such as :
Could not execute 'CALL SYS.EXECUTE_SEARCH_RULE_SET(' <query limit="500"> <ruleset ...' in 54 ms 10 µs .
SAP DBTech JDBC: [2]: general error: Defined key columns are not sufficient to yield a unique result!
…you need to rethink your SRS and especially the usage of your Key Columns section. You can change the behavior of your Key Columns to non unique by pressing on the View node, setting Non Unique Keys to true. This will ensure that your Key Columns can be used in multiple rules. Usually the Key Columns defined in the View section generate the uniqueness of the found records in your duplicate check.
9. *HANA Search View Regeneration
Please keep in mind that regenerating your HANA Search Views will override your Search View and Search Rule Set settings. The regeneration option is accessible from the Search View section in the MDGIMG – or via TA “MDG_HDB_GEN_UI”.
10. Include Duplicate Check in MDG Change Request
Having defined your SRS properly, you can now move on with the MDG change request (CR) customizing part. In MDG, you need to consider the duplicate check in your change CR(s).
In the IMG navigate to “Configure Properties of Change Request Step”. Choose the CR type you want to work with.
11. Duplicate Check in MDG FIORI "Request New Customer"
The following describes how the duplicate check results may look like from an MDG FIORI UI perspective using the standard "Request New Customer" app.
In this example I had to change the company name.


Additional Aspects
- The created reuse search views from MDG Customizing can be extended with additional fields and entities. These fields can also be included in your duplicate check respectively search rule sets. Feel free to try out and let us know from your experience.
- For debugging MDG HANA search/duplicate check use ABAP class CL_MDG_HDB_SEARCH (is the class that provides the search/duplicate check features/interfaces)
Thanks to Roland Gremmelspacher and Michael Veth from the MDG Product Team who provided valuable information.
I hope this will enable some of you to successfully implement more sophisticated duplicate checks in the MDG world.
Best regards and good luck while developing,
Any questions are welcome,
There's also always room for improvement so please let me know when you come across errors etc.,
Stefan
- SAP Managed Tags:
- SAP Master Data Governance
21 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- SAP Analytics Cloud Planning - Converting data in Technology Blogs by SAP
- Dynamic Derivations using BADI in SAP MDG in Technology Blogs by Members
- SAP Datasphere: Using Variable derivation for currency conversion measures within Analytic Model in Technology Blogs by SAP
- Trigger a process in SAP Build Process Automation from SAP Build Apps without using API [Sneak Peek] in Technology Blogs by SAP
- What you need to know about Finance in SAP S/4HANA Cloud, Public Edition in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |