Welcome back to the next blog in the SAP S/4HANA Cloud 2-tier ERP blog series.
In this blog, let’s take a look at master data handling concepts in a 2-tier deployment model.
Enterprises worldwide strive to have a clean, duplicity free, accurate master data. Lot of efforts is spent in this direction. A fragmented, inconsistent master data hiders business processes efficiency, introduces reputation risks and might lead to loss of customer loyalty and eventually business loss.
Simply put clean
master data is fundamental to any enterprise’s success.
There are many products from SAP’s stable for master data handling like SAP MDM and SAP MDG. In this blog post we are not going to look at these product capabilities, but going to look at the various approaches I feel are possible in master data handling in a 2-tier deployment.
I see the following possible approaches
- Headquarters runs MDG addon on SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud
- Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud – Replication using DRF
- Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud – API approach
- Headquarters runs SAP ECC or S/4HANA OnPremise & SAP PI/PO/other middleware and Subsidiary runs S/4HANA Cloud – data handling in SAP PO
- Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud – data replication and transformation using SAP CP.
Approach 1: Headquarters runs MDG addon on SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud
In this deployment model, HQ runs SAP ERP or S/4HANA OnPremise and MDG is an addon. The expectation here is to extend the role MDG plays in OnPremise in ensuring a clean and single source of master data to all satellite systems to also to S/4HANA Cloud.
Existing investments into SAP MDG can be extended to ensure even S/4HANA cloud gets Master Data pushed from SAP MDG to S/4HANA Cloud instance.

In this approach, subsidiaries running S/4HANA Cloud can seamlessly work with an existing SAP MDG instance to get clean master data and reduces the risk of subsidiaries introducing incomplete, inconsistent local copies of Master Data.
Approach 2: Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud –
Replication using DRF
This approach is pretty similar to the one we saw earlier in Approach 1. In this case, we do not have an SAP MDG instance, but still need ability to send master data maintained in HQ to local subsidiaries running S/4HANA Cloud.
In such cases, DRF comes in handy. We can replicate master data changes carried out centrally either manually or automatically in the background using the data replication framework (DRF). Filters allow us to configure replication settings. (Approach 1 also leverages DRF)
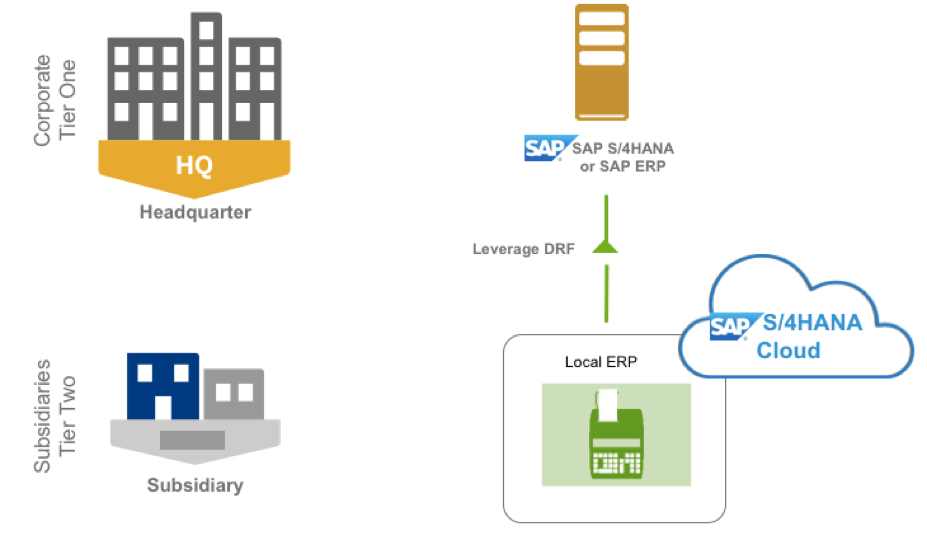
In this case, there is no need for additional investments for customers to ensure master data (Customer, Vendor, Material) are synchronized across HQ and subsidiaries. As I’m leveraging DRF, I’ve limited transformation capabilities in case I need to perform extensive data transformation or need to publish the master data to multiple systems.
Approach 3: Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud –
API approach
In this approach, I would leverage the whitelisted APIs published on API Hub for S/4HANA Cloud for CRUD operations of various master data objects.
For a detailed list of APIs available, visit:
https://api.sap.com

Here, I do not get any framework support to say which Master Data object has been created newly or changed in HQ. All these logic and transformation logic needs to be a custom solution on HQ side.
The next 2 approaches we are going to discuss will essentially build upon this approach.
Approach 4: Headquarters runs SAP ECC or S/4HANA OnPremise & SAP PI/PO/other middleware and Subsidiary runs S/4HANA Cloud – data handling in SAP PO
Yes, when I was discussing, approach 3, many of us would have thought, why can’t I have SAP PO which will help me in performing data transformation more easily than writing it as a custom logic on ERP side.
This is also a possibility.

With SAP PO or any other middleware, I get more advantages than a pure API approach we saw earlier:
- Better data transformation handling ability
- Data transformation rules are centralized in my landscape (SAP PO for instance here)
- Ability to propagate master data to multiple systems
Approach 5: Headquarters runs SAP ECC or S/4HANA OnPremise and Subsidiary runs S/4HANA Cloud – data replication and transformation using SAP CP.
This approach is essentially a variant of the Approach 4 we discussed. Here instead of SAP PO, I make use of SAP CP (integration service) capabilities for master data transformation and transfer to subsidiaries running S/4HANA Cloud.
With more and more enterprise adopting a cloud approach, I see Approach 5 getting wider acceptance and be the preferred choice.

Of course for both Approach 4 and Approach 5, you need whitelisted APIs or IDocs on SAP S/4HANA Cloud side to make this communication to work.
I have put forth various approaches I see are possible for master data handling in a 2 tier deployment. Not all master data objects will follow one approach. I will pen another blog on what approach various master data objects (like BP, Material, profit center, cost center, internal order, conditions, tax codes, procurement master like plant, purchasing organization, Bill of material, inspection methods, work center, project master etc…) can use later.
For more information on SAP S/4HANA Cloud, check out the following links:
Follow us via
@SAP and #S/4HANA or connect with me via
srivatsan.santhanam
