
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- #sitFRA Demo Recap – SAP HANA && SAP Vora Yin and...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
abdel_dadouche
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-12-2017
8:46 AM
Following the #sitFRA Demo Recap blog, here is the second part of the series.
This part will focus on how to import the data used in our demo from the GDELT database.
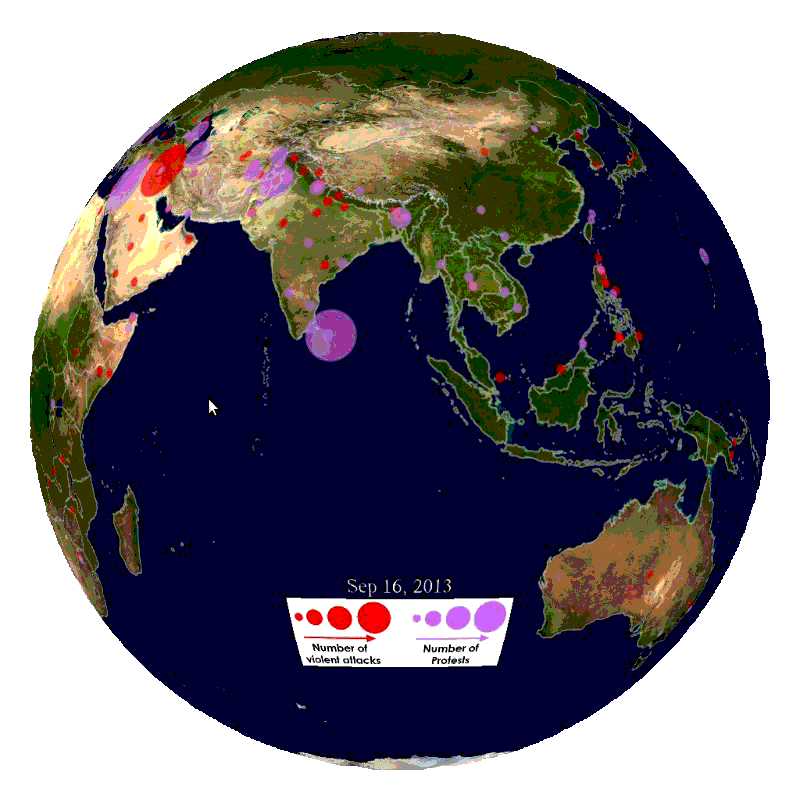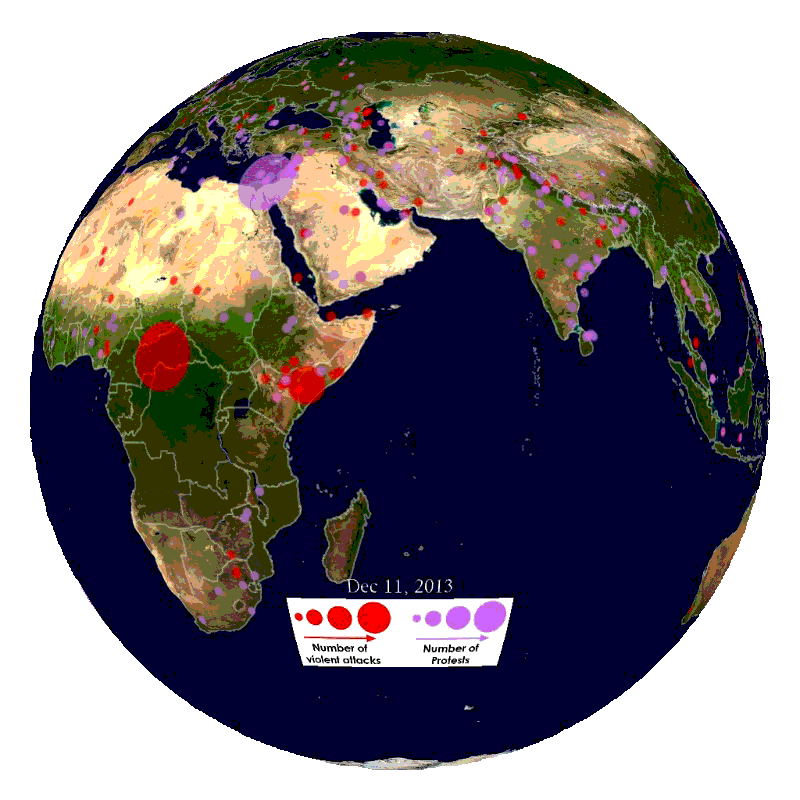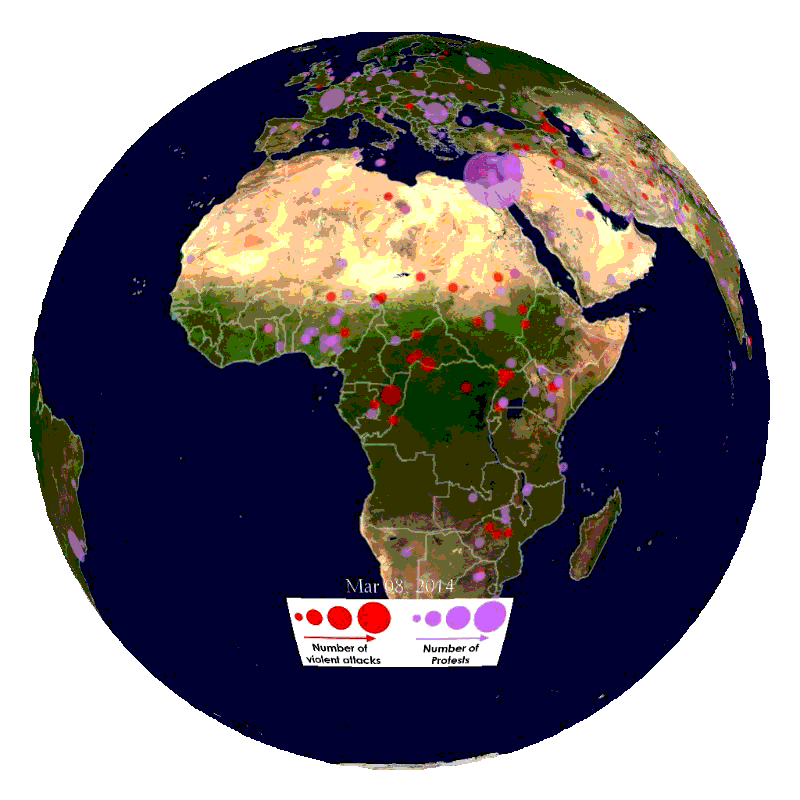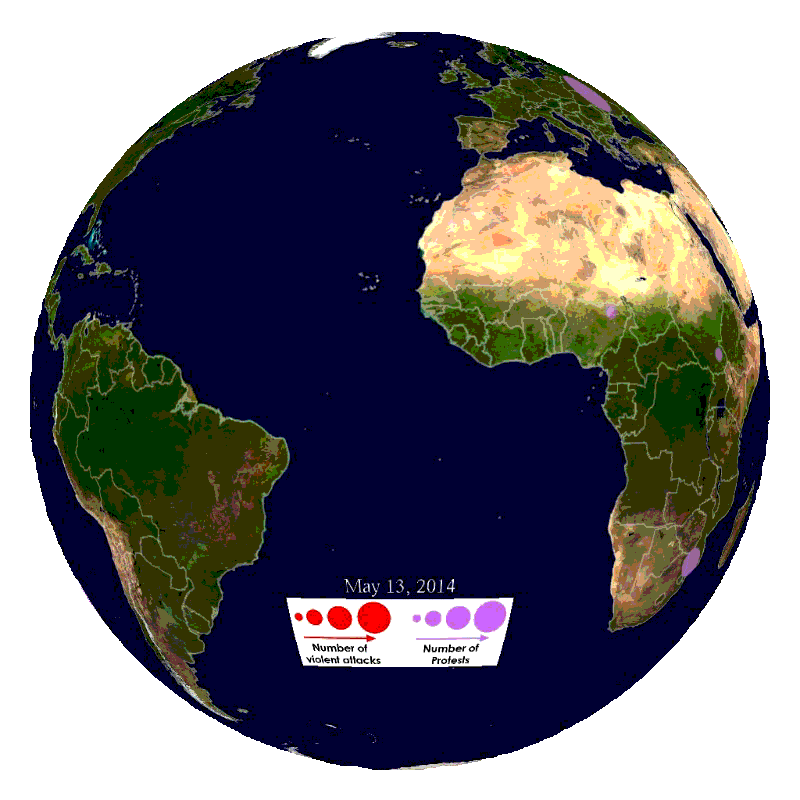
In this blog part, we will explain how to import the data into SAP HANA and SAP Vora.
But, first a quick recap of the dataset we have used.
The data we used for the demo were retrieved from the Global Database of Events, Language, and Tone data (GDELT) version 1.0 from the GDELT project.
The GDELT 1.0 event dataset comprises over 3.5 billion mentions of over 364 million distinct events from almost every corner of the earth spanning January 1979 to present and updated daily.
The file format documentation describes the various fields and their structure.
In addition, tab-delimited lookup files are available that contain the human-friendly textual labels for each of those codes to make it easier to work with the data for those who have not previously worked with CAMEO.
Lookups are available for both Event Codes and the Goldstein Scale.
In addition, details recording characteristics of the actors involved in each event are stored as a sequence of 3 character codes. Lookups are available for Event Country Codes, Type Codes, Known Group Codes, Ethnic Codes and Religion Codes.
And you can download the complete collection as a series of Event CSV files here:
You can find more details about GELT v1 here:
The easiest and fastest way to import small data files like the lookups table from GDELT to SAP HANA is probably via the "Import Data From Local File" feature from SAP HANA Studio (or the Eclipse plugin for SAP HANA).
Download the following files locally with a "csv" file extension:
But first, let's create the table structure to avoid any import issue (the import feature allows you to create the table on the fly, but you may run into data type issues which we want to avoid for you).
Open an "SAL Console" and execute the following script:
Then, to start the import wizard, use the "File > Import" menu, then search for "Import Data From Local File" under "SAP HANA Content".

Click on "Next", then pick your "Target System".
On the next dialog, use the browse button to pick your file, then make sure you apply the the following settings:

Then click on "Next".
On the next screen, use the menu with the "Map by name" option:

Then you can click on "Finish" and repeat the operation for the other files.
Since everything was running on my laptop, we didn't import the full set of data files from GDELT into SAP Vora, but just the last 15 days of event.
You can start with the download of a few Event CSV files from here to your local machine:
If you want to load all your files, you can replace:
by:
And off course, you can now see your table in the Vora Modeler and start querying your local data!

Now let’s play with the data, and for that here is the link:
This part will focus on how to import the data used in our demo from the GDELT database.
The GDELT Data
(source:http://gdeltproject.org/)
In this blog part, we will explain how to import the data into SAP HANA and SAP Vora.
But, first a quick recap of the dataset we have used.
The data we used for the demo were retrieved from the Global Database of Events, Language, and Tone data (GDELT) version 1.0 from the GDELT project.
The GDELT 1.0 event dataset comprises over 3.5 billion mentions of over 364 million distinct events from almost every corner of the earth spanning January 1979 to present and updated daily.
The file format documentation describes the various fields and their structure.
In addition, tab-delimited lookup files are available that contain the human-friendly textual labels for each of those codes to make it easier to work with the data for those who have not previously worked with CAMEO.
Lookups are available for both Event Codes and the Goldstein Scale.
In addition, details recording characteristics of the actors involved in each event are stored as a sequence of 3 character codes. Lookups are available for Event Country Codes, Type Codes, Known Group Codes, Ethnic Codes and Religion Codes.
And you can download the complete collection as a series of Event CSV files here:
http://data.gdeltproject.org/events/index.html
You can find more details about GELT v1 here:
http://gdeltproject.org/data.html#documentation
In our scenario, we decided to use SAP HANA to host the "dimension" data and SAP Vora to host the events data.
Importing the data in SAP HANA
The easiest and fastest way to import small data files like the lookups table from GDELT to SAP HANA is probably via the "Import Data From Local File" feature from SAP HANA Studio (or the Eclipse plugin for SAP HANA).
Download the following files locally with a "csv" file extension:
But first, let's create the table structure to avoid any import issue (the import feature allows you to create the table on the fly, but you may run into data type issues which we want to avoid for you).
Open an "SAL Console" and execute the following script:
CREATE SCHEMA DEMO_HANA;
CREATE COLUMN TABLE "DEMO_HANA"."COUNTRY" (
"CODE" NVARCHAR(3) NOT NULL,
"LABEL" NVARCHAR(50),
PRIMARY KEY ("CODE")
) UNLOAD PRIORITY 5 AUTO MERGE ;
CREATE COLUMN TABLE "DEMO_HANA"."EVENTCODE" (
"CAMEOEVENTCODE" NVARCHAR(5) NOT NULL,
"EVENTDESCRIPTION" NVARCHAR(100),
PRIMARY KEY ("CAMEOEVENTCODE")
) UNLOAD PRIORITY 5 AUTO MERGE ;
CREATE COLUMN TABLE "DEMO_HANA"."GOLDSTEINSCALE" (
"CAMEOEVENTCODE" NVARCHAR(5) NOT NULL,
"GOLDSTEINSCALE" DECIMAL(6,1) CS_FIXED,
PRIMARY KEY ("CAMEOEVENTCODE")
) UNLOAD PRIORITY 5 AUTO MERGE ;Then, to start the import wizard, use the "File > Import" menu, then search for "Import Data From Local File" under "SAP HANA Content".
Click on "Next", then pick your "Target System".
On the next dialog, use the browse button to pick your file, then make sure you apply the the following settings:
- Set "Field delimiter" to "Tab"
- Check "Header Row"
- Check "Import all data"
- Select "Existing" for the "Target Table", then using the "Select table" button pick the corresponding table
Then click on "Next".
On the next screen, use the menu with the "Map by name" option:
Then you can click on "Finish" and repeat the operation for the other files.
Importing the data in SAP Vora
Since everything was running on my laptop, we didn't import the full set of data files from GDELT into SAP Vora, but just the last 15 days of event.
You can start with the download of a few Event CSV files from here to your local machine:
http://data.gdeltproject.org/events/index.html
Then you can transfer the files to your SAP Vora virtual machine (using either the "shared folder" feature of your "hypervisor" or via FTP).
You can for example copy the files into a directory like: /home/vora/zip
Note: for those familiar with wget or curl, you can download the files directly to your virtual machine (but make sure your proxy is properly configured if you use one).
Also I recommend you to transfer the unzipped version of the files, so it will be faster, but then you will need to unzip them using them with a command like this:
mkdir /home/vora/csv
unzip "/home/vora/zip/*.zip" -d /home/vora/csvThe uncompressed files are "CSV", but they use tabs as delimiters, and are not using quotes to delimit fields, which will not ease the import in the disk engine (it works fine with the relational engine however).
So, you can run the following command to transform the csv files into a more standard format:
for i in /home/vora/csv/*.CSV; do sed -e 's/"/\\"/g' -e 's/<tab>/","/g' -e 's/^/"/' -e 's/$/"/' "$i" > "${i/.CSV}".csv; done
Make sure you replace the "<tab>" by an actual tab (using CTRL+V, Tab key).
Then, we need to import the data into Hadoop HDFS with the following command (executed as the vora user:
sudo hdfs dfs -mkdir /user/hdfs
sudo hdfs dfs -mkdir /user/hdfs/csv
sudo hdfs dfs -put /home/vora/csv/*.csv /user/hdfs/csv
sudo hdfs dfs -chmod -R 777 /user/hdfsWe used "sudo" here, because Hadoop is currently installed and running as the "root" user.
Now that the files are on the Hadoop HDFS, you can run the following SQL command from the Vora tools SQL Editor to create the tables:
- as a "disk engine" table:
DROP TABLE IF EXISTS EVENTS_DE;
CREATE TABLE EVENTS_DE (
GLOBALEVENTID BIGINT,
SQLDATE INTEGER,
MONTHYEAR INTEGER,
YYEAR INTEGER,
FRACTIONDATE VARCHAR(20),
ACTOR1CODE VARCHAR(20),
ACTOR1NAME VARCHAR(255),
ACTOR1COUNTRYCODE VARCHAR(3),
ACTOR1KNOWNGROUPCODE VARCHAR(3),
ACTOR1ETHNICCODE VARCHAR(3),
ACTOR1RELIGION1CODE VARCHAR(3),
ACTOR1RELIGION2CODE VARCHAR(3),
ACTOR1TYPE1CODE VARCHAR(3),
ACTOR1TYPE2CODE VARCHAR(3),
ACTOR1TYPE3CODE VARCHAR(3),
ACTOR2CODE VARCHAR(15),
ACTOR2NAME VARCHAR(255),
ACTOR2COUNTRYCODE VARCHAR(3),
ACTOR2KNOWNGROUPCODE VARCHAR(3),
ACTOR2ETHNICCODE VARCHAR(3),
ACTOR2RELIGION1CODE VARCHAR(3),
ACTOR2RELIGION2CODE VARCHAR(3),
ACTOR2TYPE1CODE VARCHAR(3),
ACTOR2TYPE2CODE VARCHAR(3),
ACTOR2TYPE3CODE VARCHAR(3),
ISROOTEVENT INTEGER,
EVENTCODE VARCHAR(4),
EVENTBASECODE VARCHAR(3),
EVENTROOTCODE VARCHAR(2),
QUADCLASS INTEGER,
GOLDSTEINSCALE DECIMAL(1,1),
NUMMENTIONS INTEGER,
NUMSOURCES INTEGER,
NUMARTICLES INTEGER,
AVGTONE DOUBLE,
ACTOR1GEO_TYPE INTEGER,
ACTOR1GEO_FULLNAME VARCHAR(255),
ACTOR1GEO_COUNTRYCODE VARCHAR(2),
ACTOR1GEO_ADM1CODE VARCHAR(5),
ACTOR1GEO_LAT DECIMAL(9,4),
ACTOR1GEO_LONG DECIMAL(9,4),
ACTOR1GEO_FEATUREID VARCHAR(10),
ACTOR2GEO_TYPE INTEGER,
ACTOR2GEO_FULLNAME VARCHAR(255),
ACTOR2GEO_COUNTRYCODE VARCHAR(3),
ACTOR2GEO_ADM1CODE VARCHAR(5),
ACTOR2GEO_LAT DECIMAL(9,4),
ACTOR2GEO_LONG DECIMAL(9,4),
ACTOR2GEO_FEATUREID VARCHAR(10),
ACTIONGEO_TYPE INTEGER,
ACTIONGEO_FULLNAME VARCHAR(255),
ACTIONGEO_COUNTRYCODE VARCHAR(3),
ACTIONGEO_ADM1CODE VARCHAR(5),
ACTIONGEO_LAT DECIMAL(9,4),
ACTIONGEO_LONG DECIMAL(9,4),
ACTIONGEO_FEATUREID VARCHAR(50),
DATEADDED INTEGER,
SOURCEURL VARCHAR(255)
) USING
com.sap.spark.engines.disk
OPTIONS (
storagebackend "hdfs",
files "/user/hdfs/csv/20170318.export.csv",
format "csv",
tableName "EVENTS_DISK",
tableSchema "GLOBALEVENTID BIGINT, SQLDATE INTEGER, MONTHYEAR INTEGER, YYEAR INTEGER, FRACTIONDATE VARCHAR(20), ACTOR1CODE VARCHAR(20), ACTOR1NAME VARCHAR(255), ACTOR1COUNTRYCODE VARCHAR(3), ACTOR1KNOWNGROUPCODE VARCHAR(3), ACTOR1ETHNICCODE VARCHAR(3), ACTOR1RELIGION1CODE VARCHAR(3), ACTOR1RELIGION2CODE VARCHAR(3), ACTOR1TYPE1CODE VARCHAR(3), ACTOR1TYPE2CODE VARCHAR(3), ACTOR1TYPE3CODE VARCHAR(3), ACTOR2CODE VARCHAR(15), ACTOR2NAME VARCHAR(255), ACTOR2COUNTRYCODE VARCHAR(3), ACTOR2KNOWNGROUPCODE VARCHAR(3), ACTOR2ETHNICCODE VARCHAR(3), ACTOR2RELIGION1CODE VARCHAR(3), ACTOR2RELIGION2CODE VARCHAR(3), ACTOR2TYPE1CODE VARCHAR(3), ACTOR2TYPE2CODE VARCHAR(3), ACTOR2TYPE3CODE VARCHAR(3), ISROOTEVENT INTEGER, EVENTCODE VARCHAR(4), EVENTBASECODE VARCHAR(3), EVENTROOTCODE VARCHAR(2), QUADCLASS INTEGER, GOLDSTEINSCALE DECIMAL(1,1), NUMMENTIONS INTEGER, NUMSOURCES INTEGER, NUMARTICLES INTEGER, AVGTONE DOUBLE, ACTOR1GEO_TYPE INTEGER, ACTOR1GEO_FULLNAME VARCHAR(255), ACTOR1GEO_COUNTRYCODE VARCHAR(2), ACTOR1GEO_ADM1CODE VARCHAR(5), ACTOR1GEO_LAT DECIMAL(9,4), ACTOR1GEO_LONG DECIMAL(9,4), ACTOR1GEO_FEATUREID VARCHAR(10), ACTOR2GEO_TYPE INTEGER, ACTOR2GEO_FULLNAME VARCHAR(255), ACTOR2GEO_COUNTRYCODE VARCHAR(3), ACTOR2GEO_ADM1CODE VARCHAR(5), ACTOR2GEO_LAT DECIMAL(9,4), ACTOR2GEO_LONG DECIMAL(9,4), ACTOR2GEO_FEATUREID VARCHAR(10), ACTIONGEO_TYPE INTEGER, ACTIONGEO_FULLNAME VARCHAR(255), ACTIONGEO_COUNTRYCODE VARCHAR(3), ACTIONGEO_ADM1CODE VARCHAR(5), ACTIONGEO_LAT DECIMAL(9,4), ACTIONGEO_LONG DECIMAL(9,4), ACTIONGEO_FEATUREID VARCHAR(50), DATEADDED INTEGER, SOURCEURL VARCHAR(255)"
);
SELECT * FROM EVENTS_DE LIMIT 10;- as a "relational" table:
DROP TABLE IF EXISTS EVENTS_RE;
CREATE TABLE EVENTS_RE(
GLOBALEVENTID BIGINT,
SQLDATE INTEGER,
MONTHYEAR INTEGER,
YYEAR INTEGER,
FRACTIONDATE VARCHAR(20),
ACTOR1CODE VARCHAR(20),
ACTOR1NAME VARCHAR(255),
ACTOR1COUNTRYCODE VARCHAR(3),
ACTOR1KNOWNGROUPCODE VARCHAR(3),
ACTOR1ETHNICCODE VARCHAR(3),
ACTOR1RELIGION1CODE VARCHAR(3),
ACTOR1RELIGION2CODE VARCHAR(3),
ACTOR1TYPE1CODE VARCHAR(3),
ACTOR1TYPE2CODE VARCHAR(3),
ACTOR1TYPE3CODE VARCHAR(3),
ACTOR2CODE VARCHAR(15),
ACTOR2NAME VARCHAR(255),
ACTOR2COUNTRYCODE VARCHAR(3),
ACTOR2KNOWNGROUPCODE VARCHAR(3),
ACTOR2ETHNICCODE VARCHAR(3),
ACTOR2RELIGION1CODE VARCHAR(3),
ACTOR2RELIGION2CODE VARCHAR(3),
ACTOR2TYPE1CODE VARCHAR(3),
ACTOR2TYPE2CODE VARCHAR(3),
ACTOR2TYPE3CODE VARCHAR(3),
ISROOTEVENT INTEGER,
EVENTCODE VARCHAR(4),
EVENTBASECODE VARCHAR(3),
EVENTROOTCODE VARCHAR(2),
QUADCLASS INTEGER,
GOLDSTEINSCALE DECIMAL(3,1),
NUMMENTIONS INTEGER,
NUMSOURCES INTEGER,
NUMARTICLES INTEGER,
AVGTONE DOUBLE,
ACTOR1GEO_TYPE INTEGER,
ACTOR1GEO_FULLNAME VARCHAR(255),
ACTOR1GEO_COUNTRYCODE VARCHAR(2),
ACTOR1GEO_ADM1CODE VARCHAR(5),
ACTOR1GEO_LAT DECIMAL(9,4),
ACTOR1GEO_LONG DECIMAL(9,4),
ACTOR1GEO_FEATUREID VARCHAR(10),
ACTOR2GEO_TYPE INTEGER,
ACTOR2GEO_FULLNAME VARCHAR(255),
ACTOR2GEO_COUNTRYCODE VARCHAR(3),
ACTOR2GEO_ADM1CODE VARCHAR(5),
ACTOR2GEO_LAT DECIMAL(9,4),
ACTOR2GEO_LONG DECIMAL(9,4),
ACTOR2GEO_FEATUREID VARCHAR(10),
ACTIONGEO_TYPE INTEGER,
ACTIONGEO_FULLNAME VARCHAR(255),
ACTIONGEO_COUNTRYCODE VARCHAR(3),
ACTIONGEO_ADM1CODE VARCHAR(5),
ACTIONGEO_LAT DECIMAL(9,4),
ACTIONGEO_LONG DECIMAL(9,4),
ACTIONGEO_FEATUREID VARCHAR(50),
DATEADDED INTEGER,
SOURCEURL VARCHAR(255)
) USING
com.sap.spark.vora
OPTIONS (
storagebackend "hdfs",
files "/user/hdfs/csv/20170318.export.csv",
format "csv",
schema "GLOBALEVENTID BIGINT, SQLDATE INTEGER, MONTHYEAR INTEGER, YYEAR INTEGER, FRACTIONDATE VARCHAR(20), ACTOR1CODE VARCHAR(20), ACTOR1NAME VARCHAR(255), ACTOR1COUNTRYCODE VARCHAR(3), ACTOR1KNOWNGROUPCODE VARCHAR(3), ACTOR1ETHNICCODE VARCHAR(3), ACTOR1RELIGION1CODE VARCHAR(3), ACTOR1RELIGION2CODE VARCHAR(3), ACTOR1TYPE1CODE VARCHAR(3), ACTOR1TYPE2CODE VARCHAR(3), ACTOR1TYPE3CODE VARCHAR(3), ACTOR2CODE VARCHAR(15), ACTOR2NAME VARCHAR(255), ACTOR2COUNTRYCODE VARCHAR(3), ACTOR2KNOWNGROUPCODE VARCHAR(3), ACTOR2ETHNICCODE VARCHAR(3), ACTOR2RELIGION1CODE VARCHAR(3), ACTOR2RELIGION2CODE VARCHAR(3), ACTOR2TYPE1CODE VARCHAR(3), ACTOR2TYPE2CODE VARCHAR(3), ACTOR2TYPE3CODE VARCHAR(3), ISROOTEVENT INTEGER, EVENTCODE VARCHAR(4), EVENTBASECODE VARCHAR(3), EVENTROOTCODE VARCHAR(2), QUADCLASS INTEGER, GOLDSTEINSCALE DECIMAL(3,1), NUMMENTIONS INTEGER, NUMSOURCES INTEGER, NUMARTICLES INTEGER, AVGTONE DOUBLE, ACTOR1GEO_TYPE INTEGER, ACTOR1GEO_FULLNAME VARCHAR(255), ACTOR1GEO_COUNTRYCODE VARCHAR(2), ACTOR1GEO_ADM1CODE VARCHAR(5), ACTOR1GEO_LAT DECIMAL(9,4), ACTOR1GEO_LONG DECIMAL(9,4), ACTOR1GEO_FEATUREID VARCHAR(10), ACTOR2GEO_TYPE INTEGER, ACTOR2GEO_FULLNAME VARCHAR(255), ACTOR2GEO_COUNTRYCODE VARCHAR(3), ACTOR2GEO_ADM1CODE VARCHAR(5), ACTOR2GEO_LAT DECIMAL(9,4), ACTOR2GEO_LONG DECIMAL(9,4), ACTOR2GEO_FEATUREID VARCHAR(10), ACTIONGEO_TYPE INTEGER, ACTIONGEO_FULLNAME VARCHAR(255), ACTIONGEO_COUNTRYCODE VARCHAR(3), ACTIONGEO_ADM1CODE VARCHAR(5), ACTIONGEO_LAT DECIMAL(9,4), ACTIONGEO_LONG DECIMAL(9,4), ACTIONGEO_FEATUREID VARCHAR(50), DATEADDED INTEGER, SOURCEURL VARCHAR(255)"
);
SELECT * FROM EVENTS_RE LIMIT 10;If you want to load all your files, you can replace:
files "/user/hdfs/csv/20170318.export.csv",by:
files "/user/hdfs/csv/*",And off course, you can now see your table in the Vora Modeler and start querying your local data!
Now let’s play with the data, and for that here is the link:
- SAP Managed Tags:
- SAP Inside Track,
- SAP HANA,
- SAP Vora
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
422 -
Workload Fluctuations
1
Related Content
- Onboarding Users in SAP Quality Issue Resolution in Technology Blogs by SAP
- How to host static webpages through SAP CPI-Iflow in Technology Blogs by Members
- Accelerate Business Process Development with SAP Build Process Automation Pre-Built Content in Technology Blogs by SAP
- Streamlining Time Sheet Approvals in SuccessFactors: Time Sheet Approval Center in Technology Blogs by Members
- Edit Query Disabled from File server data source in Data Management SAC in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |