
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Remote Sources and Virtual Tables from HANA to Vor...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-31-2017
10:43 PM
Creating Remote Sources and Virtual Tables in HANA to Hive and Vora can be accomplished using HANA Studio to create remote sources and virtual tables, but what about using DDL?
There are 3 types of connections that can be created from HANA to Vora or Hive using a Remote Source. Two use the SparkController, while the third uses the newly available HANA Wire Protocol.
SparkController 2.0 can support HANA 1.0 SPS11 or 12 and HANA 2.0 and access Vora 1.2 or 1.3 or Hive on a Hadoop Cluster.
The use of the HANA Wire Protocol requires Vora 1.3 and the enablement of the wire protocol support in the Vora Transaction Coordinator service. (As of this writing, only Vora Disk tables can be accessed using the HANA Wire Protocol connection, not in-memory tables).
For these examples, we will be using HANA 12 SPS122.5, Vora 1.3.65 and the SparkController 2.0.0.
Details on configuring the SparkControllers for this exercise can be found in: https://blogs.sap.com/2016/10/13/configuring-multiple-sparkcontrollers-ambari-hana-dlm-hive-vora-acc...
First things first, let's set up some simple test data.
Now we need to load this into Hive and Vora. We can run everything from the Vora spark shell:
Now we have 3 tables loaded into various datastores, we can switch to HANA Studio, but as we are using DDL, we can also use hdbsql.
We will use the SparkSQL HANA adapter to connect to the SparkControllers for Hive and Vora in-memory access.
Creating the Hive remote source
Creating the Vora remote source
Lastly, we will use the new HANA Wire Protocol to access the table in the Vora disk store.
Creating the HANA Wire remote source
Refreshing and Expanding all the folders underneath the Provisioning folder should show the new remote datasources and the tables available for virtual table creation in HANA:
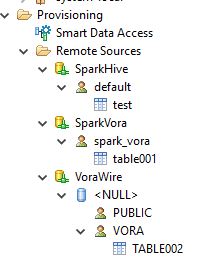
Any of these tables can be created in HANA as a virtual table for access by HANA by selecting the table and using a right-mouse click and creating the table in a HANA schema:


but we will use DDL to create these tables instead.
The tables will now appear in your Catalog/<schema>/Tables folder as virtual tables:
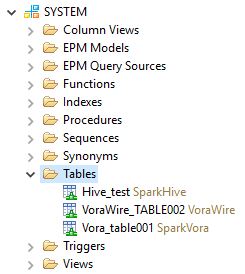
You can now use them as you would any other virtual table.
As of this writing, the following notes apply:
Chris
There are 3 types of connections that can be created from HANA to Vora or Hive using a Remote Source. Two use the SparkController, while the third uses the newly available HANA Wire Protocol.
SparkController 2.0 can support HANA 1.0 SPS11 or 12 and HANA 2.0 and access Vora 1.2 or 1.3 or Hive on a Hadoop Cluster.
The use of the HANA Wire Protocol requires Vora 1.3 and the enablement of the wire protocol support in the Vora Transaction Coordinator service. (As of this writing, only Vora Disk tables can be accessed using the HANA Wire Protocol connection, not in-memory tables).
For these examples, we will be using HANA 12 SPS122.5, Vora 1.3.65 and the SparkController 2.0.0.
Details on configuring the SparkControllers for this exercise can be found in: https://blogs.sap.com/2016/10/13/configuring-multiple-sparkcontrollers-ambari-hana-dlm-hive-vora-acc...
First things first, let's set up some simple test data.
- Log into a console and create the test data:
>su - vora
>echo 1,2,Hello > test.csv
>hadoop fs -put test.csv
>hadoop fs -ls /user/vora
[...]
-rw-r--r-- 3 vora hdfs 10 2017-01-06 21:12 /user/vora/test.csv
[...]
The test data is now in the local file system and hdfs.
Now we need to load this into Hive and Vora. We can run everything from the Vora spark shell:
>$VORA_SPARK_HOME/bin/start-spark-shell.sh
....
SQL context available as sqlContext.
scala>- First we will create a Hive 'test' table in the 'default' Hive database:
scala> import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.hive.HiveContext
scala> val hc = new HiveContext(sc)
hc: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@457512b
scala> hc.sql("CREATE TABLE IF NOT EXISTS test(a1 INT, a2 INT, a3 STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
res0: org.apache.spark.sql.DataFrame = [result: string]
scala> hc.sql("LOAD DATA LOCAL INPATH '/home/vora/test.csv' INTO TABLE test")
res1: org.apache.spark.sql.DataFrame = [result: string]
scala> val result = sqlContext.sql("FROM test SELECT a1, a2, a3")
result: org.apache.spark.sql.DataFrame = [a1: int, a2: int, a3: string]
scala> result.show()
+---+---+-----+
| a1| a2| a3|
+---+---+-----+
| 1| 2|Hello|
+---+---+-----+
scala> sys.exit
- Now, let's load the same data into Vora in-memory engine:
scala> import org.apache.spark.sql.SapSQLContext
import org.apache.spark.sql.SapSQLContext
scala> val vc = new SapSQLContext(sc)
vc: org.apache.spark.sql.SapSQLContext = org.apache.spark.sql.SapSQLContext@7a6ccc46
scala> val testsql = """
CREATE TABLE table001 (a1 double, a2 int, a3 string)
USING com.sap.spark.vora
OPTIONS (
files "/user/vora/test.csv"
)"""
testsql: String =
"
CREATE TABLE table001 (a1 double, a2 int, a3 string)
USING com.sap.spark.vora
OPTIONS (
files "/user/vora/test.csv"
)"
scala> vc.sql(testsql)
res0: org.apache.spark.sql.DataFrame = []
scala> vc.sql("show tables").show
+---------+-----------+
|tableName|isTemporary|
+---------+-----------+
| table001| false|
+---------+-----------+
scala>
- and for the last table, we will load the data into the Vora disk engine:
scala> val testsql = """
CREATE TABLE TABLE002 (A1 double, A2 int, A3 string)
USING com.sap.spark.engines.disk
OPTIONS (
files "/user/vora/test.csv",
csvdelimiter ",",
format "csv",
tableName "TABLE002",
tableSchema "A1 double, A2 integer, A3 varchar(10)",
storagebackend "hdfs"
)"""
testsql: String =
"
CREATE TABLE TABLE002 (A1 double, A2 int, A3 string)
USING com.sap.spark.engines.disk
OPTIONS (
files "/user/vora/test.csv",
csvdelimiter ",",
format "csv",
tableName "TABLE002",
tableSchema "A1 double, A2 integer, A3 varchar(10)",
storagebackend "hdfs"
)"
scala> vc.sql(testsql).show
++
||
++
++
scala> vc.sql("select * from TABLE002").show
+---+---+-----+
| A1| A2| A3|
+---+---+-----+
|1.0| 2|Hello|
+---+---+-----+
scala> sys.exit
>
Now we have 3 tables loaded into various datastores, we can switch to HANA Studio, but as we are using DDL, we can also use hdbsql.
We will use the SparkSQL HANA adapter to connect to the SparkControllers for Hive and Vora in-memory access.
Creating the Hive remote source
- Start HANA Studio and navigate to the server you want to use. Open a SQL Console window. To create the Hive Remote source, issue the following command (using the DSN name of your Hive-configured SparkController):
CREATE REMOTE SOURCE "SparkHive" ADAPTER "sparksql"
CONFIGURATION 'port=7860;ssl_mode=disabled;server=<HiveSparkControllerServerDNS>'
WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=hanaes;password=hanaes'
Statement 'CREATE REMOTE SOURCE "SparkHive" ADAPTER "sparksql" CONFIGURATION ...'
successfully executed in 107 ms 32 µs (server processing time: 3 ms 655 µs) - Rows Affected: 0
Creating the Vora remote source
- Issue the following in the HANA Studio SQL Console to create a Vora remote source using the Vora-configured SparkController:
CREATE REMOTE SOURCE "SparkVora" ADAPTER "sparksql"
CONFIGURATION 'port=7860;ssl_mode=disabled;server=<VoraSparkControllerServerDNS>'
WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=hanaes;password=hanaes
Statement 'CREATE REMOTE SOURCE "SparkVora" ADAPTER "sparksql" CONFIGURATION ...'
successfully executed in 114 ms 748 µs (server processing time: 3 ms 398 µs) - Rows Affected: 0
Lastly, we will use the new HANA Wire Protocol to access the table in the Vora disk store.
Creating the HANA Wire remote source
- First, Vora has to be configured to use the Wire. Log into the Vora Manager GUI:http://<Vora Manager Node:19000/vora-manager/web/select 'Services' and open the 'Vora Transaction Coordinator' service 'Configuration' tab. Ensure that 'HANA Wire activation' is selected and that an 'Instance number for Vora Transaction Coordinator' has been assigned:

- From the HANA Studio SQL Console window, you can now issue the following command (replacing the <TC Server DNS Name> with the server name of your Vora Transaction Coordinator service and the <TC HANA Wire Port> with 30<Instance number for Vora Transaction Coordinator>5 e.g. 30115):
CREATE REMOTE SOURCE "VoraWire" ADAPTER "voraodbc"
CONFIGURATION 'ServerNode=<TC Server DNS Name>:<TC HANA Wire Port>;Driver=libodbcHDB'
WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=hanaes;password=hanaes';
Statement 'CREATE REMOTE SOURCE "VoraWire" ADAPTER "voraodbc" CONFIGURATION ...'
successfully executed in 105 ms 922 µs (server processing time: 3 ms 317 µs) - Rows Affected: 0
Refreshing and Expanding all the folders underneath the Provisioning folder should show the new remote datasources and the tables available for virtual table creation in HANA:
Any of these tables can be created in HANA as a virtual table for access by HANA by selecting the table and using a right-mouse click and creating the table in a HANA schema:
but we will use DDL to create these tables instead.
- From the SQL Console, issue the following DDL commands for each table:
create virtual table "<schema>"."Hive_test"
at "SparkHive"."hive"."default"."test";
create virtual table "<schema>"."Vora_table001"
at "SparkVora"."vora"."spark_vora"."table001";
create virtual table "<schema>"."VoraWire_TABLE002"
at "VoraWire"."voraodbc"."VORA"."TABLE002";
--I used my default "SYSTEM" schema in place of "<schema>"
Statement 'create virtual table "SYSTEM"."Hive_test" at "SparkHive"."hive"."default"."test"'
successfully executed in 1.618 seconds (server processing time: 1.511 seconds) - Rows Affected: 0
Statement 'create virtual table "SYSTEM"."Vora_table001" at "SparkVora"."vora"."spark_vora"."table001"'
successfully executed in 2.096 seconds (server processing time: 1.964 seconds) - Rows Affected: 0
Statement 'create virtual table "SYSTEM"."VoraWire_TABLE002" at "VoraWire"."voraodbc"."VORA"."TABLE002"'
successfully executed in 2.451 seconds (server processing time: 2.342 seconds) - Rows Affected: 0
Duration of 3 statements: 6.166 seconds
The tables will now appear in your Catalog/<schema>/Tables folder as virtual tables:
You can now use them as you would any other virtual table.
As of this writing, the following notes apply:
- The HANA Wire activation only supports tables cataloged in the Vora disk engine.
- Re-starting Vora will require the Vora disk tables to be re-loaded (see the 'SAP HANA Vora Developer Guide').
- As you can see from step 4, cataloging a Vora disk table in HANA requires the table name in Uppercase and additional tableSchema options to allow HANA to use HANA datatypes instead of Vora/Spark datatypes (e.g. Varchar(x) instead of string)
Chris
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
326 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- It has never been easier to print from SAP with Microsoft Universal Print in Technology Blogs by Members
- SAP Sustainability Footprint Management: Q1-24 Updates & Highlights in Technology Blogs by SAP
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors in Technology Blogs by SAP
- Taking Data Federation to the Next Level: Accessing Remote ABAP CDS View Entities in SAP HANA Cloud in Technology Blogs by SAP
- API Composition with Graph: customizing your Business Data Graphs with Model Extensions in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |