
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Conversions in SAP Gateway Foundation - Part 2
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-23-2017
9:55 AM
In the first blog post of this series we focused on a simple example of an alpha conversion for a property in an OData service. Before we discuss more elaborate features and issues with the built-in conversion facilities of SAP Gateway Foundation we need to understand a few details of the stack.
This post will shed light to some aspects of the service model and the data transfer between the different layers of SAP Gateway Foundation. While we stick to the feature of conversions the explanations foster an understanding of the runtime behavior of SAP Gateway Foundation in other contexts, too.
OData services mainly expose their model information in two resources:
The service document describes addressable entity sets and function imports and the metadata document provides details about the entity types / complex types and their (navigation) properties including their defining attributes, and including annotations. A service consumer uses this information to interact with the service.
SAP Gateway Foundation assumes the task to process OData requests translating them into appropriate calls to the data provider (see stack overview below). SAP Gateway Foundation provides a number of features to support the service implementation – one of those being the execution of conversions. We have already seen that the required information (the name of the conversion exit, for example) is provided through the implementation of the model provider class. Or, it is automatically determined when using certain model APIs. This conversion information becomes part of the model, too.
To summarize, the model describes structure and behavior of the service:
It is important to understand that the service model contains a lot more data that controls the service behavior than those exposed to the service consumer.
The following data is part of the model and directly or indirectly related to conversions but not exclusively used for this purpose:
While the last bullet point is not that obvious the ABAP data type information is the most complex data set, is of huge importance to conversions, and might be the source of issues and incidents. The data type information is best understood if we look at the data transfer inside SAP Gateway Foundation which will also reveal where conversions are executed.
The framework in SAP Gateway Foundation that processes OData requests is made up of different components and layers. The so-called hub component comprises the OData library and the hub framework layer. The hub component may run on a separate system, the FIORI frontend server, for example. The backend component contains the backend framework layer and delegates the request processing to the service-specific model and data provider classes.
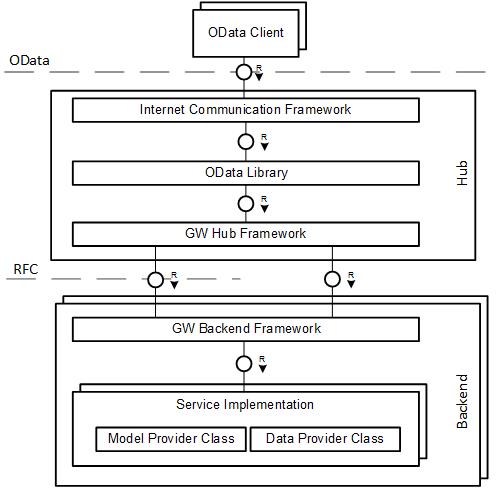
We will start with an analysis of the outbound data flow, that is, the flow from the provisioning of data in the data provider class to the final http response payload. And, we stick to the example in the first blog post:
To respond to an entity set
The framework transfers the content of the provider data container into the internal data container in two steps:
Again, the internal data container is an internal table but the row structure is generated by the backend or hub framework layer at runtime. The data types used are derived from the service model. The ABAP data types of the internal data container need to match the EDM Types of the corresponding properties representing the sales order header in our example. Later on, the OData library serializes the OData response from the internal data container.
Please observe that the internal data container is being generated both in the hub and backend framework layer in case of a hub deployment scenario – the internal data container content is serialized and transferred through an RFC connection between the systems. In case of a co-deployment scenario there is one instance of the internal data container.
The first step of moving the data between the data containers is already a transformation. The containers may be deeply structured when
In our example, the field
The second step was the starting point of the whole discussion. So, the provider data container forms the input to the outbound conversions with the result being stored in the internal data container from which the OData response is created.
Now, the field
For the other direction we need to distinguish between two cases:
The data flow in the second case is very similar to what we discussed above: the request payload is de-serialized into the internal data container and then transferred to a provider data container including conversion execution on-demand. We will see this in the last chapter.
To-be-converted data from the URI is handled slightly differently. There is no internal data container. Instead, the data is forwarded to the backend framework layer in a string representation. When the data provider tries to retrieve the data it has to provide a proper data container. The string representation is then translated into the expected format including inbound conversion execution.
Let us see how the data provider accesses the data provided by the framework and how response data is being returned.
We get back to our example of the sales order header from the first blog post of this series. Suppose we need to implement the
The request URI may look like
The structure field
Similarly, function import parameters can be retrieved with method
The structure of a row of
To get the converted information you need to pick on line in
Similarly, methods
As we can see, when the data provider retrieves the “input” information the framework delivers the data into the provider data containers having applied the inbound conversions.
The way back has already been described above. Let us focus on a very specific example to illustrate potential differences between the provider and the internal data container and to highlight the importance of the ABAP data type information in the model.
Suppose your entity type contains a language. In most cases, language fields in the ABAP Dictionary are typed with data element
The provider data container will be similar to the table definition in the ABAP Dictionary, that is, the one-character language code is provided to the framework. The internal data container constructed by the framework will contain a two-character representation that can be serialized into the OData response. The framework executes the outbound conversion
This post will shed light to some aspects of the service model and the data transfer between the different layers of SAP Gateway Foundation. While we stick to the feature of conversions the explanations foster an understanding of the runtime behavior of SAP Gateway Foundation in other contexts, too.
Service Model
OData services mainly expose their model information in two resources:
- the service document –
GET …/<service>/ - the metadata document –
GET …/<service>/$metadata
The service document describes addressable entity sets and function imports and the metadata document provides details about the entity types / complex types and their (navigation) properties including their defining attributes, and including annotations. A service consumer uses this information to interact with the service.
SAP Gateway Foundation assumes the task to process OData requests translating them into appropriate calls to the data provider (see stack overview below). SAP Gateway Foundation provides a number of features to support the service implementation – one of those being the execution of conversions. We have already seen that the required information (the name of the conversion exit, for example) is provided through the implementation of the model provider class. Or, it is automatically determined when using certain model APIs. This conversion information becomes part of the model, too.
To summarize, the model describes structure and behavior of the service:
- for the service consumer providing views onto the model defined by the OData specification like the service and the metadata document and
- for the SAP Gateway Foundation framework providing views onto the model required to process service requests.
It is important to understand that the service model contains a lot more data that controls the service behavior than those exposed to the service consumer.
The following data is part of the model and directly or indirectly related to conversions but not exclusively used for this purpose:
- The conversion switches discussed in the first blog post of this series
- The conversion exit on property level
- Unit or currency code semantics on property level and references to such properties
- ABAP data type information on property level
While the last bullet point is not that obvious the ABAP data type information is the most complex data set, is of huge importance to conversions, and might be the source of issues and incidents. The data type information is best understood if we look at the data transfer inside SAP Gateway Foundation which will also reveal where conversions are executed.
Data Transfer
Layering
The framework in SAP Gateway Foundation that processes OData requests is made up of different components and layers. The so-called hub component comprises the OData library and the hub framework layer. The hub component may run on a separate system, the FIORI frontend server, for example. The backend component contains the backend framework layer and delegates the request processing to the service-specific model and data provider classes.
Outbound Data Flow
We will start with an analysis of the outbound data flow, that is, the flow from the provisioning of data in the data provider class to the final http response payload. And, we stick to the example in the first blog post:
To respond to an entity set
GET-request the data provider selects data from database table VBAK and will probably store this data in an internal table with a similar structure. The data is provided to the framework as a reference to such an internal table. The row structure with the data types involved are defined by the data provider. Therefore, we call this internal table the provider data container.The framework transfers the content of the provider data container into the internal data container in two steps:
- The data is moved from the provider data container to the internal data container.
- Conversions are applied to relevant fields of the provider data container writing the result of the conversion into the internal data container.
Again, the internal data container is an internal table but the row structure is generated by the backend or hub framework layer at runtime. The data types used are derived from the service model. The ABAP data types of the internal data container need to match the EDM Types of the corresponding properties representing the sales order header in our example. Later on, the OData library serializes the OData response from the internal data container.
Please observe that the internal data container is being generated both in the hub and backend framework layer in case of a hub deployment scenario – the internal data container content is serialized and transferred through an RFC connection between the systems. In case of a co-deployment scenario there is one instance of the internal data container.
The first step of moving the data between the data containers is already a transformation. The containers may be deeply structured when
$expand is used. Therefore, the data is transferred using a serialization/de-serialization with an ID transformation – this process “converts” some of the representations already. With release 7.50 the framework uses the deep move-corresponding (move-corresponding expanding nested tables) if possible. The tricky point is that the ID transformation differs from the deep move-corresponding in some details – the framework pre-analyzes the model and decides upon a proper usage to ensure compatibility between the different releases.In our example, the field
VBELN of the internal data container would still carry the value with leading zeros after the first step.The second step was the starting point of the whole discussion. So, the provider data container forms the input to the outbound conversions with the result being stored in the internal data container from which the OData response is created.
Now, the field
VBELN contains the value without leading zeros after execution of the alpha conversion.Inbound Data Flow
For the other direction we need to distinguish between two cases:
- To-be-converted data may be part of the request URI – keys, function import parameters, filter literals
- To-be-converted data may be part of the request payload for
POST,PUT, andPATCHrequests
The data flow in the second case is very similar to what we discussed above: the request payload is de-serialized into the internal data container and then transferred to a provider data container including conversion execution on-demand. We will see this in the last chapter.
To-be-converted data from the URI is handled slightly differently. There is no internal data container. Instead, the data is forwarded to the backend framework layer in a string representation. When the data provider tries to retrieve the data it has to provide a proper data container. The string representation is then translated into the expected format including inbound conversion execution.
Data Provider
Retrieving Data from the Framework
Let us see how the data provider accesses the data provided by the framework and how response data is being returned.
We get back to our example of the sales order header from the first blog post of this series. Suppose we need to implement the
GET_ENTITY method of the data provider to retrieve a single sales order header based on its key VBELN.The request URI may look like
/…/<service>/SD_HEADER_SET(Vbeln=‘21351’). The data provider class needs to calldata ls_vbak type vbak.
io_tech_request_context->get_converted_keys(
importing
es_key_values = ls_vbak ).The structure field
LS_VBAK-VBELN would contain value ‘0000021351’, that is, the value after application of the alpha conversion. The original value from the request URI is still available through methodio_tech_request_context->get_keys( ).Similarly, function import parameters can be retrieved with method
GET_CONVERTED_PARAMETERS from io_tech_request_context. GET_PARAMETERS delivers the original values from the request URI.$filter is a very complex and powerful system query option. To reduce complexity we focus on select options although not every filter expression can be translated into select options. A simple (not quite reasonable) example:/…/<service>/SD_HEADER_SET?$filter=Vbeln eq ‘21351’data:
lo_filter type ref to /iwbep/if_mgw_req_filter,
lt_select_option type /iwbep/t_mgw_select_option.
lo_filter = io_tech_request_context->get_filter( ).
lt_select_option = lo_filter->get_filter_select_options( ).The structure of a row of
lt_select_option is made up of the name of the affected ABAP field and a range table containing sign, option, and low/high values. The latter values are typed as STRING and contain the unconverted ABAP literals. For the above example:| SIGN (CHAR 1) | OPTION (CHAR 2) | LOW (STRING) | HIGH (STRING) |
| I | EQ | 21351 |
To get the converted information you need to pick on line in
lt_select_option, that is, the range information for one single field. Then call method CONVERT_SELECT_OPTIONdata:
ltr_vbeln type range of vbeln_va.
lo_filter->convert_select_option(
exporting
is_select_option = ls_select_option
importing
et_select_option = ltr_vbeln ).
ltr_vbeln is a range table for the specific document number field. Low and high values are typed with the respective data element. Using the above terminology, it is the (range) provider data container.Similarly, methods
GET_OSQL_WHERE_CLAUSE and GET_OSQL_WHERE_CLAUSE_CONVERT are the two methods at io_request_context that would deliver the $filter expression as an OSQL WHERE-clause, if possible. Either the literals are delivered in the ABAP format before or after applying the inbound conversions.As we can see, when the data provider retrieves the “input” information the framework delivers the data into the provider data containers having applied the inbound conversions.
Returning Data to the Framework
The way back has already been described above. Let us focus on a very specific example to illustrate potential differences between the provider and the internal data container and to highlight the importance of the ABAP data type information in the model.
Suppose your entity type contains a language. In most cases, language fields in the ABAP Dictionary are typed with data element
SPRAS, a one-character code – see field SPRAS in table T001. Data element SPRAS refers to domain SPRAS carrying the conversion exit ISOLA that translates the one-character language code into the corresponding two-character ISO representation. Please observe that the output length of domain SPRAS is set to two. The language property in the entity type is probably typed with Edm.String (max length 2) to expose the ISO language code.The provider data container will be similar to the table definition in the ABAP Dictionary, that is, the one-character language code is provided to the framework. The internal data container constructed by the framework will contain a two-character representation that can be serialized into the OData response. The framework executes the outbound conversion
ISOLA on the way from the provider to the internal data container. If you would switch off the conversion then the one-character code would appear in the two-character language property.
- SAP Managed Tags:
- OData,
- SAP Gateway,
- NW ABAP Gateway (OData)
Labels:
18 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
402 -
Workload Fluctuations
1
Related Content
- S/4HANA 2023 FPS00 Upgrade in Technology Blogs by Members
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- How to Connect a S/4HANA Cloud Private Edition System to SAP Start in Technology Blogs by SAP
- SAP Analytics Cloud (SAC) Integration with On-Premise Systems from SAP Basis End #ATR in Technology Blogs by Members
- SAP Enterprise Architecture: Positioning Blockchain Database as an Enterprise Technology Standard 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 4 |