
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Vora (v 1.2) Introduction – Part II
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-17-2016
11:15 PM
I have covered the basic introduction of SAP HANA Vora's environment in the blog part I.
Here I will cover more detail on the architecture behind SAP HANA Vora version 1.2.
The Hadoop environment is a cluster in which thousands of nodes can form the platform for storage, access, and analysis of big structured data, as well as complex, unstructured data. The SAP HANA Vora solution is built to run as another service on top of the Hadoop ecosystem.
If you have worked on Hadoop, you probably are aware of the architecture of the platform. For those who are new to Hadoop, here is some basic information to help understand how SAP HANA Vora is placed in the Hadoop environment.
Hadoop is a combination of many open-source components that work together to support the distributed processing of large datasets. The data is distributed across many nodes in a cluster on what is called Hadoop distributed file systems (HDFS). Basically the nodes are nothing but less-expensive commodity systems running a version of Linux. The other major components are YARN, which manages all the Hadoop cluster resources such as memory allocation; Apache Spark; Zookeeper, which is the coordinator to manage all the services running on Hadoop; and the HBase database, which is a Hadoop database to run on top of these clusters of nodes.
Hive SQL, Spark SQL, and Pig Scripting are query languages that can be used to query the Hadoop data from the cluster’s HDFSs (Refer to Fig 1 in Part I). These tools support the distributed processing of large structured and unstructured datasets across a cluster of multiple nodes, at times running into thousands of nodes. Apache Ambari (for HDP distribution) is used for provisioning the services to any number of nodes within the cluster.
SAP HANA Vora runs as one service on the platform. The SAP HANA Vora instance holds data in memory and boosts the performance of Apache Spark. This instance contains the SAP HANA Vora engine and Spark Worker, both installed on the nodes that hold the data for processing (called data nodes in the cluster). SAP HANA Vora interacts with the Spark in-memory data-processing engine to improve performance. SAP HANA Vora enables the analytical process of Hadoop, and enables hierarchy reporting by allowing hierarchies to be built on top of the Big Data.
Fig 1 shows an illustration of how SAP HANA Vora works with the Apache Spark framework in the Hadoop platform.
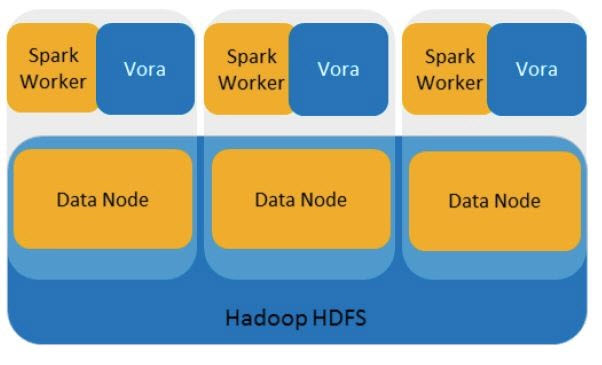
Fig 1. The architectures of Hadoop, Apache Spark, and SAP HANA Vora
SAP HANA Vora Components
SAP HANA Vora is packaged with two major components
With the latest SAP HANA Vora version 1.2, SAP HANA Vora starts a few services, such as metadata cataloging, discovery, and distributed logging, to work with the Big Data platform. Let’s take a look at the details of each service and how they work together in the execution process.
The services can be managed using Apache Ambari from the cluster’s main dashboard.
Figure 2 SAP HANA Vora services as shown in the Apache Ambari management screen
SAP HANA Vora Base
The SAP HANA Vora base component is not a service, but it contains all the necessary libraries and binaries. It is the base set of tools that helps all the SAP HANA Vora components work effectively. This component is installed on all the nodes in the cluster.
SAP HANA Vora Catalog Server
The SAP HANA Vora Catalog server provides the necessary information whenever the SAP HANA requests metadata, which it identifies by communicating with the DLog server that maintains the metadata persistence. The SAP HANA Vora Catalog server allows the SAP HANA to store and retrieve generic hierarchical and versioned key values, which it requires in order to synchronize parallel updates.
The catalog acts as a proxy to other metadata stores, such as HDFS NameNode, and caches their metadata locally for better performance. It also determines the preferred locations of a given file stored on the HDFS based on the locations of its data blocks.
VORA Discovery Service
The major supporting component of the SAP HANA Vora is the Discovery service. This manages the service endpoints in the cluster, such as SAP HANA Vora Catalog, SAP HANA Vora engines, AppServer (which provides the run time for web applications like SAP HANA Vora Tools), Zookeeper, and the SAP HANA Vora Distributed Log (DLog). The Discovery Service is installed in all the nodes either in server mode or in client mode. A minimum of three nodes needs to be running in the server mode in the whole cluster, while the service can run in the client mode in the rest of the nodes.
The SAP HANA Vora Discovery Service uses the Consul Discovery Service (from HashiCorp) and manages all the service registrations and runs health checks on them. The Consul Discovery service can be accessed using the browser from any Discovery Server or client node on port 8500. From this (web) page you can monitor the health of all the services that are registered to the Consul Discovery Service and the details on each of the services, like the type of service provided by any particular node in the cluster. The SAP HANA Vora Discovery service requires Zookeeper, HDFS from Hadoop, and SAP HANA Vora Base to be available in order for it to provide its service.
SAP HANA Vora DLog (Discovery Log) Service
The SAP HANA Vora DLog service is a manager that provides metadata persistence for SAP HANA Vora Catalog. The DLog service needs the SAP HANA Vora Discovery Service to be running for it to work. Depending on the number of nodes available, one DLog server is needed, though you can have up to five DLog servers.
SAP HANA Vora Thrift server
The SAP HANA Vora Thrift server is a gateway that is compatible with the Hive Java Database Connectivity (JDBC) driver, which installs on a single node. This is installed on a node where the Discovery Service, DLog, and Catalog Service are not deployed, normally called a Jump node or an Edge node. This service is used when a front-end tool such as SAP Lumira makes a generic JDBC connection to run visualization on top of data from SAP HANA Vora or Apache Spark.
SAP HANA Vora Tools
SAP HANA Vora Tools provide a browser interface connecting at the default port (Port 9225) where you can look into the tables’ and views’ data (the first 1,000 rows are displayed), and export the data to a Comma Separated Value (CSV) format (Figure 4). The browser also has a SQL Editor for creating and running SQL Scripts and a modeler for creating custom data models. The tables in the SAP HANA Vora context are not available automatically in the web front end for data retrieval (currently, as of version 1.2).
Before the table or view can be successfully accessed in the SAP HANA Vora tools browser, the SAP HANA Vora catalog tables and views have to be registered with the register table command using the SQL Editor in the Vora tools browser.

Figure 3 SAP HANA Vora Tools browser
SAP HANA Vora V2Server
The SAP HANA Vora V2Server is the relational, in-memory SQL processing engine. It communicates with HDFS through an HDFS plug-in, and with other SAP HANA Vora engines during hash-partitioned data loading. The SAP HANA Vora V2Server needs the SAP HANA Vora Catalog Service to be running, and this V2Server has to be running on all the data nodes of the cluster for data processing.
SAP HANA Vora extension
SAP HANA Vora and SAP HANA data sources can work with the Apache Spark’s SQLContext standard application programming interface (API). However, using SAP HANA Vora’s extended data source API, called SapSQLContext, provides additional functionalities, such as DDL/SQL parsers, hierarchy enablement, and OLAP modeling. It adds the semantics for persistent tables managed by SAP HANA Vora engines. Here are some details on the benefits of the SAP HANA Vora extension.
I will cover more on how you can consume Big Data from the Hadoop environment using SAP HANA Vora and how it can be federated with other systems such as SAP HANA in the next blogs.
Here I will cover more detail on the architecture behind SAP HANA Vora version 1.2.
The Hadoop environment is a cluster in which thousands of nodes can form the platform for storage, access, and analysis of big structured data, as well as complex, unstructured data. The SAP HANA Vora solution is built to run as another service on top of the Hadoop ecosystem.
If you have worked on Hadoop, you probably are aware of the architecture of the platform. For those who are new to Hadoop, here is some basic information to help understand how SAP HANA Vora is placed in the Hadoop environment.
Hadoop is a combination of many open-source components that work together to support the distributed processing of large datasets. The data is distributed across many nodes in a cluster on what is called Hadoop distributed file systems (HDFS). Basically the nodes are nothing but less-expensive commodity systems running a version of Linux. The other major components are YARN, which manages all the Hadoop cluster resources such as memory allocation; Apache Spark; Zookeeper, which is the coordinator to manage all the services running on Hadoop; and the HBase database, which is a Hadoop database to run on top of these clusters of nodes.
Hive SQL, Spark SQL, and Pig Scripting are query languages that can be used to query the Hadoop data from the cluster’s HDFSs (Refer to Fig 1 in Part I). These tools support the distributed processing of large structured and unstructured datasets across a cluster of multiple nodes, at times running into thousands of nodes. Apache Ambari (for HDP distribution) is used for provisioning the services to any number of nodes within the cluster.
SAP HANA Vora runs as one service on the platform. The SAP HANA Vora instance holds data in memory and boosts the performance of Apache Spark. This instance contains the SAP HANA Vora engine and Spark Worker, both installed on the nodes that hold the data for processing (called data nodes in the cluster). SAP HANA Vora interacts with the Spark in-memory data-processing engine to improve performance. SAP HANA Vora enables the analytical process of Hadoop, and enables hierarchy reporting by allowing hierarchies to be built on top of the Big Data.
Fig 1 shows an illustration of how SAP HANA Vora works with the Apache Spark framework in the Hadoop platform.
Fig 1. The architectures of Hadoop, Apache Spark, and SAP HANA Vora
SAP HANA Vora Components
SAP HANA Vora is packaged with two major components
- SAP HANA Vora engine
- SAP HANA Vora Apache Spark extension library
With the latest SAP HANA Vora version 1.2, SAP HANA Vora starts a few services, such as metadata cataloging, discovery, and distributed logging, to work with the Big Data platform. Let’s take a look at the details of each service and how they work together in the execution process.
The services can be managed using Apache Ambari from the cluster’s main dashboard.
Figure 2 SAP HANA Vora services as shown in the Apache Ambari management screen
SAP HANA Vora Base
The SAP HANA Vora base component is not a service, but it contains all the necessary libraries and binaries. It is the base set of tools that helps all the SAP HANA Vora components work effectively. This component is installed on all the nodes in the cluster.
SAP HANA Vora Catalog Server
The SAP HANA Vora Catalog server provides the necessary information whenever the SAP HANA requests metadata, which it identifies by communicating with the DLog server that maintains the metadata persistence. The SAP HANA Vora Catalog server allows the SAP HANA to store and retrieve generic hierarchical and versioned key values, which it requires in order to synchronize parallel updates.
The catalog acts as a proxy to other metadata stores, such as HDFS NameNode, and caches their metadata locally for better performance. It also determines the preferred locations of a given file stored on the HDFS based on the locations of its data blocks.
VORA Discovery Service
The major supporting component of the SAP HANA Vora is the Discovery service. This manages the service endpoints in the cluster, such as SAP HANA Vora Catalog, SAP HANA Vora engines, AppServer (which provides the run time for web applications like SAP HANA Vora Tools), Zookeeper, and the SAP HANA Vora Distributed Log (DLog). The Discovery Service is installed in all the nodes either in server mode or in client mode. A minimum of three nodes needs to be running in the server mode in the whole cluster, while the service can run in the client mode in the rest of the nodes.
The SAP HANA Vora Discovery Service uses the Consul Discovery Service (from HashiCorp) and manages all the service registrations and runs health checks on them. The Consul Discovery service can be accessed using the browser from any Discovery Server or client node on port 8500. From this (web) page you can monitor the health of all the services that are registered to the Consul Discovery Service and the details on each of the services, like the type of service provided by any particular node in the cluster. The SAP HANA Vora Discovery service requires Zookeeper, HDFS from Hadoop, and SAP HANA Vora Base to be available in order for it to provide its service.
SAP HANA Vora DLog (Discovery Log) Service
The SAP HANA Vora DLog service is a manager that provides metadata persistence for SAP HANA Vora Catalog. The DLog service needs the SAP HANA Vora Discovery Service to be running for it to work. Depending on the number of nodes available, one DLog server is needed, though you can have up to five DLog servers.
SAP HANA Vora Thrift server
The SAP HANA Vora Thrift server is a gateway that is compatible with the Hive Java Database Connectivity (JDBC) driver, which installs on a single node. This is installed on a node where the Discovery Service, DLog, and Catalog Service are not deployed, normally called a Jump node or an Edge node. This service is used when a front-end tool such as SAP Lumira makes a generic JDBC connection to run visualization on top of data from SAP HANA Vora or Apache Spark.
SAP HANA Vora Tools
SAP HANA Vora Tools provide a browser interface connecting at the default port (Port 9225) where you can look into the tables’ and views’ data (the first 1,000 rows are displayed), and export the data to a Comma Separated Value (CSV) format (Figure 4). The browser also has a SQL Editor for creating and running SQL Scripts and a modeler for creating custom data models. The tables in the SAP HANA Vora context are not available automatically in the web front end for data retrieval (currently, as of version 1.2).
Before the table or view can be successfully accessed in the SAP HANA Vora tools browser, the SAP HANA Vora catalog tables and views have to be registered with the register table command using the SQL Editor in the Vora tools browser.
Figure 3 SAP HANA Vora Tools browser
SAP HANA Vora V2Server
The SAP HANA Vora V2Server is the relational, in-memory SQL processing engine. It communicates with HDFS through an HDFS plug-in, and with other SAP HANA Vora engines during hash-partitioned data loading. The SAP HANA Vora V2Server needs the SAP HANA Vora Catalog Service to be running, and this V2Server has to be running on all the data nodes of the cluster for data processing.
SAP HANA Vora extension
SAP HANA Vora and SAP HANA data sources can work with the Apache Spark’s SQLContext standard application programming interface (API). However, using SAP HANA Vora’s extended data source API, called SapSQLContext, provides additional functionalities, such as DDL/SQL parsers, hierarchy enablement, and OLAP modeling. It adds the semantics for persistent tables managed by SAP HANA Vora engines. Here are some details on the benefits of the SAP HANA Vora extension.
- The extended SapSQLContext API, bundled with SAP HANA Vora, provides the full integration between SAP HANA Vora and Apache Spark. This makes the data sources filterable and the data can be pruned at the source level for data aggregations and selections. This vastly increases the performance of the Apache Spark jobs.
- The extended SapSQLContext API supports advanced features, such as PrunedFilteredAggregatedScan, PrunedFilteredExpressionsScan, CatalystSource, ExpressionSupport, DropRelation, AppendRelation, and SqlLikeRelation.
- SAP HANA provide OLAP-style capabilities to data on Hadoop, including hierarchy implementations. This helps to analyze the data with parent-/child-like hierarchical grouping, performing complex computations at different levels of the hierarchy, by allowing hierarchical data structures defined on top of the Hadoop data.
- SAP HANA also allow data processing between the SAP HANA and Hadoop environments, and offer the ability to combine data between these two systems and then process it in Apache Spark or in SAP HANA applications.
- SAP HANA Vora supports Apache Spark SQL, as well as coding languages such as Scala, Java, and Python. Using SAP HANA Vora, you can develop applications from Spark-based environments using the extension.
I will cover more on how you can consume Big Data from the Hadoop environment using SAP HANA Vora and how it can be federated with other systems such as SAP HANA in the next blogs.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
422 -
Workload Fluctuations
1
Related Content
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- Error while HANA Cloud tenant in Python on SAP HANA Cloud in Technology Q&A
- Embracing TypeScript in SAPUI5 Development in Technology Blogs by Members
- Consuming SAP with SAP Build Apps - Connectivity options for low-code development - part 2 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |