
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA 2.0 SPS 0: New Developer Features; Databa...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-01-2016
6:51 PM
In this blog, I would like to introduce you to the new features for the database developer in SAP HANA 2.0 SPS 0. We will focus more on the database development topic including Core Data Services, as well as SQLScript. If you are interested in the new features for XS Advanced(XSA), or the SAP WebIDE for SAP HANA, please check out this blog by my colleague thomas.jung.
GENERATE {ALWAYS|BY DEFAULT} AS IDENTITY
The first new feature for CDS is the GENERATE AS IDENTITY clause when defining entities within a CDS artifact. Previously, if you wanted to auto-increment a key field, you had to create a separate artifact, an .hdbsequence in order to manage the auto-increment configuration. Now in SAP HANA 2.0 SPS 0, we have the ability to define this configuration directly in the CDS artifact itself. During deploy-time, a sequence is actually generated for you automatically. Using the ALWAYS keyword, means that the value will always be generated, but if you use the BY DEFAULT, the value is generated but can actually be overridden. In the code sample below, we see that the ADDRESSID column is auto-incremented by 1 starting at 1000000001.

GENERATE ALWAYS AS <expression>
In SAP HANA 2.0 SPS 0, we also now support the use of GENERATE ALWAYS AS <expression> which allows you to create calculated columns. The element which is defined, corresponds to a field in the database table that is persisted and has an actual value, not calculated on the fly. In the code sample below, we see that there is a new column called CITY_POSTALCODE which is a string. The value of this column is defined as the concatenation of the CITY and POSTALCODE columns. Again, this concatenation is done during INSERT, and the value is stored in the physical table.

LIMIT & OFFSET in Queries
LIMIT and OFFSET have been supported by SQL in SAP HANA for quite some time, but now in SAP HANA 2.0 SPS 0, we can now use them within the context of CDS when defining views. LIMIT of course defines the number of rows to be returned after the OFFSET has been applied. OFFSET skips the first n rows of the selected dataset. LIMIT and OFFSET, when used together, are commonly used for pagination logic.

Subqueries
Another feature which has been supported by SQL in SAP HANA, but now brought to CDS is the use of subqueries when defining views.

Odata.publish
Finally, in SAP HANA 2.0 SPS 0, we have introduced a new annotation called @Odata.publish which allows you to expose the entities and views within the CDS artifact for consumption via Odata. There is no longer any need for a separate xsodata artifact. In SAP HANA 2.0 SPS 0, the Odata service is consumable only from a java module. In a future support package, we will add support for consumption from javascript modules as well.

For more information on Core Data Services, please see the Core Data Services Reference Guide.
Performance Improvements
With SAP HANA 2.0 SPS 0, we’ve released a newly architected execution engine for SQLScript which will improve the overall performance and lays the foundation for further improvements in the future as well. While these improvements are “under the hood”, meaning that as a developer you don’t really have to code anything specific to take advantage, it is important that developers know what is happening and what is different from previous releases. First, we have changed the way that we handle parameters of scalar variables. Previously, when using procedure parameters within a SELECT statement, we always replaced the actual value in the prepared statement before execution. Now in SAP HANA 2.0 SPS 0, we use query parameters instead which allows us to leverage the query plan cache even if the values of the scalar parameter change. We’ve also added several new optimizations including the concept of dead code elimination. Basically the optimizer will remove statements which have no effect on the current execution. For example, if you have a procedure with an IF statement like IF ( :im_var = 0 ) and im_var is a parameter whose value is 1, then the entire IF statement will be optimized out of the execution plan altogether. These are just a few examples of the enhancements and optimizations that come with the new SQLScript execution engine architecture in SAP HANA 2.0 SPS 0.
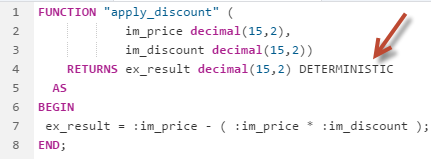
User-Defined Function Result Caching
Scalar functions can be deterministic which means that if a function is called with the same parameters, the same result will be returned every time. In these cases, it makes sense to cache the result of this scalar function. In SAP HANA 2.0 SPS 0, we have introduced a new keyword, DETERMINISTIC which you can define at the end of the result parameter of a scalar UDF. This will force the results of the scalar UDF to be cached. Subsequent calls of the function with the same input parameters will leverage the cache instead of executing the call again, which improves performance.
Size Operators for Tables
In previous releases, if you wanted to get the number of records in an intermediate table or physical table, you had to do a SELECT COUNT* or a combination of CARDINALITY and ARRAY_AGG functions to get this value. Now there is a new function called RECORD_COUNT which can be used instead. This function can be used for both physical tables as well as table variables and parameters.

Initialization of Declared Table Variables
In previous releases, declared intermediate table variables were not initialized by default. If they were not initialized before referenced this would lead to an error. Many times, developers would issue a SELECT FROM DUMMY to initialize the table with 0 rows. This was not really a nice way to handle this problem, so instead we’ve changed the behavior slightly and now there is no need to explicitly initialize the table variable as it is done automatically for you.

Explicit Parallelization of Read/Write Procedures
Previously, we did not support the use of CALL statement within a PARALLEL EXECUTION block. Now in SAP HANA 2.0 SPS 0, we now allow this with some limitations. The table referenced in a parallel execution block should be a column table, a table without triggers, a table without foreign keys and referenced only once inside of the parallel execution block.

MAP_MERGE Operator
Another new function is the MAP_MERGE function which allows you to apply each row of a tabular input to a mapper function and union all intermediate result tables into one. In the example on the left we have a procedure called get_address which executes a simple select against the address table and passes results to the output parameter. In the anonymous block below that, we loop through employees and for each employee, we call the get_address procedure and union the results of that call to the output of the block. Yes, this could be done a number of better ways, but perhaps you have a situation where you must do some processing for each row of a result set. This is where MAP_MERGE can help. If we take the same scenario and change things to use the MAP_MERGE as shown on the right, we first need to translate our procedure into a table function. Only table functions are supported as the mapper function. Then in the anonymous block below that, we can then do our SELECT to get the employees, and pass this intermediate results table for employees as well as the get_address_func mapper function to the MAP_MERGE statement. The result is that the MAP_MERGE will iterate over the employees results table, and execute the get_address_func function for each row, and finally union the results of each into the output parameter result set. In using the mapper function, it is quite a bit faster than doing the logic on the left.

BIND_AS<parameter|variable> for Parameterization Control
As mentioned earlier, we’ve changed the way that we handle scalar parameters values during execution. We no longer replace the actual value in the prepared statement and instead use query parameters. In doing so, performance should be improved, but there is always a chance that certain circumstances prevent improved performance. In order to mitigate the risk, we’ve introduced the BIND_AS<Parameter|Value> which can be used to control the parameterization behavior of scalar variables. This allows you to manually override the optimizers parameterization decision and general configuration. By using the BIND_AS, you can define how the values and query parameters are utilized in the prepare statement. As you can see in the example below, when using BIND_AS_VALUE and BIND_AS_PARAMETER, it does not matter how the value is passed to the CALL statement, whether by a static value or a parameter, the prepared statement will always be the same because of the use of BIND_AS function. If the BIND_AS function was not used here, then the prepared statements could be different based on how the parameters are passed.


For more information on SQLScript, please see the SQLScript Reference Guide.
Core Data Services(CDS)
GENERATE {ALWAYS|BY DEFAULT} AS IDENTITY
The first new feature for CDS is the GENERATE AS IDENTITY clause when defining entities within a CDS artifact. Previously, if you wanted to auto-increment a key field, you had to create a separate artifact, an .hdbsequence in order to manage the auto-increment configuration. Now in SAP HANA 2.0 SPS 0, we have the ability to define this configuration directly in the CDS artifact itself. During deploy-time, a sequence is actually generated for you automatically. Using the ALWAYS keyword, means that the value will always be generated, but if you use the BY DEFAULT, the value is generated but can actually be overridden. In the code sample below, we see that the ADDRESSID column is auto-incremented by 1 starting at 1000000001.
GENERATE ALWAYS AS <expression>
In SAP HANA 2.0 SPS 0, we also now support the use of GENERATE ALWAYS AS <expression> which allows you to create calculated columns. The element which is defined, corresponds to a field in the database table that is persisted and has an actual value, not calculated on the fly. In the code sample below, we see that there is a new column called CITY_POSTALCODE which is a string. The value of this column is defined as the concatenation of the CITY and POSTALCODE columns. Again, this concatenation is done during INSERT, and the value is stored in the physical table.
LIMIT & OFFSET in Queries
LIMIT and OFFSET have been supported by SQL in SAP HANA for quite some time, but now in SAP HANA 2.0 SPS 0, we can now use them within the context of CDS when defining views. LIMIT of course defines the number of rows to be returned after the OFFSET has been applied. OFFSET skips the first n rows of the selected dataset. LIMIT and OFFSET, when used together, are commonly used for pagination logic.
Subqueries
Another feature which has been supported by SQL in SAP HANA, but now brought to CDS is the use of subqueries when defining views.
Odata.publish
Finally, in SAP HANA 2.0 SPS 0, we have introduced a new annotation called @Odata.publish which allows you to expose the entities and views within the CDS artifact for consumption via Odata. There is no longer any need for a separate xsodata artifact. In SAP HANA 2.0 SPS 0, the Odata service is consumable only from a java module. In a future support package, we will add support for consumption from javascript modules as well.
For more information on Core Data Services, please see the Core Data Services Reference Guide.
SQLScript
Performance Improvements
With SAP HANA 2.0 SPS 0, we’ve released a newly architected execution engine for SQLScript which will improve the overall performance and lays the foundation for further improvements in the future as well. While these improvements are “under the hood”, meaning that as a developer you don’t really have to code anything specific to take advantage, it is important that developers know what is happening and what is different from previous releases. First, we have changed the way that we handle parameters of scalar variables. Previously, when using procedure parameters within a SELECT statement, we always replaced the actual value in the prepared statement before execution. Now in SAP HANA 2.0 SPS 0, we use query parameters instead which allows us to leverage the query plan cache even if the values of the scalar parameter change. We’ve also added several new optimizations including the concept of dead code elimination. Basically the optimizer will remove statements which have no effect on the current execution. For example, if you have a procedure with an IF statement like IF ( :im_var = 0 ) and im_var is a parameter whose value is 1, then the entire IF statement will be optimized out of the execution plan altogether. These are just a few examples of the enhancements and optimizations that come with the new SQLScript execution engine architecture in SAP HANA 2.0 SPS 0.
User-Defined Function Result Caching
Scalar functions can be deterministic which means that if a function is called with the same parameters, the same result will be returned every time. In these cases, it makes sense to cache the result of this scalar function. In SAP HANA 2.0 SPS 0, we have introduced a new keyword, DETERMINISTIC which you can define at the end of the result parameter of a scalar UDF. This will force the results of the scalar UDF to be cached. Subsequent calls of the function with the same input parameters will leverage the cache instead of executing the call again, which improves performance.
Size Operators for Tables
In previous releases, if you wanted to get the number of records in an intermediate table or physical table, you had to do a SELECT COUNT* or a combination of CARDINALITY and ARRAY_AGG functions to get this value. Now there is a new function called RECORD_COUNT which can be used instead. This function can be used for both physical tables as well as table variables and parameters.
Initialization of Declared Table Variables
In previous releases, declared intermediate table variables were not initialized by default. If they were not initialized before referenced this would lead to an error. Many times, developers would issue a SELECT FROM DUMMY to initialize the table with 0 rows. This was not really a nice way to handle this problem, so instead we’ve changed the behavior slightly and now there is no need to explicitly initialize the table variable as it is done automatically for you.
Explicit Parallelization of Read/Write Procedures
Previously, we did not support the use of CALL statement within a PARALLEL EXECUTION block. Now in SAP HANA 2.0 SPS 0, we now allow this with some limitations. The table referenced in a parallel execution block should be a column table, a table without triggers, a table without foreign keys and referenced only once inside of the parallel execution block.
MAP_MERGE Operator
Another new function is the MAP_MERGE function which allows you to apply each row of a tabular input to a mapper function and union all intermediate result tables into one. In the example on the left we have a procedure called get_address which executes a simple select against the address table and passes results to the output parameter. In the anonymous block below that, we loop through employees and for each employee, we call the get_address procedure and union the results of that call to the output of the block. Yes, this could be done a number of better ways, but perhaps you have a situation where you must do some processing for each row of a result set. This is where MAP_MERGE can help. If we take the same scenario and change things to use the MAP_MERGE as shown on the right, we first need to translate our procedure into a table function. Only table functions are supported as the mapper function. Then in the anonymous block below that, we can then do our SELECT to get the employees, and pass this intermediate results table for employees as well as the get_address_func mapper function to the MAP_MERGE statement. The result is that the MAP_MERGE will iterate over the employees results table, and execute the get_address_func function for each row, and finally union the results of each into the output parameter result set. In using the mapper function, it is quite a bit faster than doing the logic on the left.
BIND_AS<parameter|variable> for Parameterization Control
As mentioned earlier, we’ve changed the way that we handle scalar parameters values during execution. We no longer replace the actual value in the prepared statement and instead use query parameters. In doing so, performance should be improved, but there is always a chance that certain circumstances prevent improved performance. In order to mitigate the risk, we’ve introduced the BIND_AS<Parameter|Value> which can be used to control the parameterization behavior of scalar variables. This allows you to manually override the optimizers parameterization decision and general configuration. By using the BIND_AS, you can define how the values and query parameters are utilized in the prepare statement. As you can see in the example below, when using BIND_AS_VALUE and BIND_AS_PARAMETER, it does not matter how the value is passed to the CALL statement, whether by a static value or a parameter, the prepared statement will always be the same because of the use of BIND_AS function. If the BIND_AS function was not used here, then the prepared statements could be different based on how the parameters are passed.
For more information on SQLScript, please see the SQLScript Reference Guide.
- SAP Managed Tags:
- SAP HANA, platform edition
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
297 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Extend Your Crystal Reports Solutions in the DHTML Viewer With a Free Function Library in Technology Blogs by Members
- Customer & Partner Roundtable for SAP BTP ABAP Environment #12 in Technology Blogs by SAP
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- App to automatically configure a new ABAP Developer System in Technology Blogs by Members
- What’s new in Mobile development kit client 24.4 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |