
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data provisioning using SAP HANA Enterprise Inform...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-23-2016
6:49 PM
Table of Contents
1 Objective of the Document. 2
2 Scope of the document. 3
3 product overview.. 3
3.1 SAP HANA Options. 3
3.1.1 SAP HANA Enterprise Information management (EIM) 3
3.1.2 Smart data integration. 3
3.1.3 Smart data quality. 3
4 Installation and configuration of EIM.. 4
4.1 Enable Data Provisioning server for SDI 5
4.2 Enable Script server for SDQ.. 5
4.3 Install delivery unit HANA_IM_DP (Data Provisioning) 5
4.4 Install and register Data Provisioning Agent 6
4.5 Once installed open the Data Provisioning agent 7
4.6 Make sure the agent is started, connect and register it with the necessary adapter ...
4.6.1 Open the SAP Data provisioning agent 8
4.6.2 Connect to HANA (Click on Connect to HANA button) 8
4.6.3 Register the agent 8
4.6.4 Start the agent 9
5 Register the file adapter. 10
5.1 IBM DB2 Log Reader: 11
5.2 Oracle Log Reader 11
5.3 MS SQL Server Log Reader 11
5.4 DB2 ECC. 11
5.5 Oracle ECC. 12
5.6 MS SQL Server ECC. 12
5.7 IBM DB2 for z/OS. 12
5.8 File. 12
5.9 Hive. 12
5.10 OData. 12
5.11 SAP HANA. 12
5.12 SAP ASE. 12
5.13 Teradata. 12
5.14 Twitter 12
6 Prototype : File Adapter. 12
6.1 Preparing the source file. 12
6.1.1 Converting the text file to a config file. 13
6.1.2 Creating a remote source. 14
6.1.3 Create a virtual table. 15
6.2 Preparing the target HANA CDS entity. 16
6.3 Creating a flowgraph to transform and move data from source to target 20
7 Open evaluation steps / Limitations. 23
8 Privileges required for HANA eim.. 25
9 References. 27
The scope of this document is to analyze the technical capabilities and functional feasibility of the Smart data Integration (SDI) and Smart data Quality (SDQ) appliances provided by HANA. This document also intends to throw some light over the product architecture and various transformational capabilities that can be achieved over the big data.
The document will cover the various technical capabilities and the different interfaces that are a part of the tool. We would also be throwing some light on the available data sources in data provisioning agent which can be used to extract data. The document also explains the process of data transformation and loading using the flowgraph model provided by HANA.
SAP HANA is a modern in-memory platform that is deployable as an on-premise appliance or in the cloud. As an appliance, SAP HANA combines software components from SAP optimized on proven hardware provided by SAP’s hardware partners. In the cloud, SAP HANA is offered as a comprehensive infrastructure combined with managed services. SAP HANA can be deployed through the following cloud offerings: SAP HANA One, SAP HANA Cloud Platform and SAP HANA Enterprise Cloud.
SAP offers options and additional capabilities for SAP HANA. To use these SAP HANA options and capabilities in a production system, you must purchase the appropriate software license from SAP. The SAP HANA options and capabilities listed below are available in connection with the platform and enterprise editions of SAP HANA, depending on the software license used.
Enterprise Information Management (EIM) enhances, cleanses, and transforms data to make it more accurate and useful. With the speed advantage of SAP HANA, the new SAP HANA EIM option can connect with any source, provision and cleanse data, and load data into SAP HANA on-premise or in the cloud, and for supported systems, it can write back to the original source .
The EIM capabilities in SAP HANA EIM offers:
SAP HANA EIM consists of two main areas, smart data integration and smart data quality, as described below.
Real-time, high-speed data provisioning, bulk data movement, and federation. SAP HANA EIM
Provides built-in adapters and an SDK so you can build your own Smart data integration includes the following features and tools:
Real-time, high-speed data provisioning, bulk data movement, and federation. SAP HANA EIM
provides built-in adapters and an SDK so you can build your own Smart data integration includes the following features and tools:

Fig 1 The HANA In Memory Platform extracts data from various data sources, This platform consists of the SDQ layer over the SDI layer and is synced with the current data

Fig 2: The SAP HANA EIM services are installed in the SAP HANA enterprise server, along with the core HANA components; the data provisioning agent tool will be installed at the source system, from where the source data is extracted. The SAP HANA server can then be accessed via front end tools like SAP HANA Studio which are shipped as part of core HANA bundle by SAP
When Hana is installed, by default the DP server is not activated, in order to have the ability to use SDI it needs to be enabled. The value needs to be change to 1

To take advantage of the SDQ functionality the script server value needs to be change to 1

The specific delivery unit needs to be downloading and upload from the studio or the web interface, this will provide you:


The Data Provisioning Agent is used to make the bridge between Hana and source system .Using the DPA allows live replication.
The agent is part of the package download earlier

Run and installed it as needed

Domain: Global\SAP_ID




To get the Agent Name / Agent Hostname : open command prompt à Type ‚ipconfig‘ à IPv4 address


All the adapters are by default deployed by the Data Provisioning agent, we just need to register the correct agent to read the data from that source
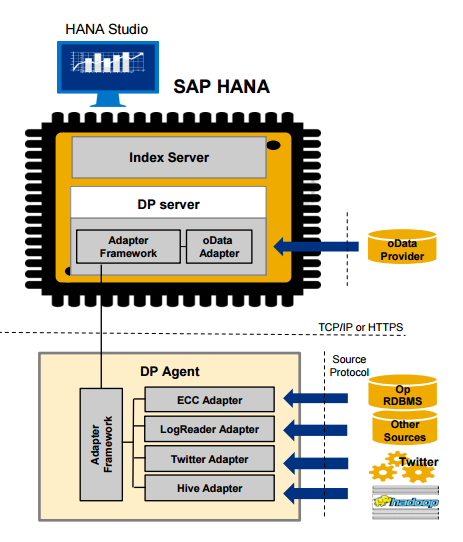
Fig 3: The various adapters responsible for extracting data from their respective sources interact with the adapter framework on the SAP HANA server
The various available adapters in data provisioning agent are:
This adapter retrieves data from DB2 and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from Oracle and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from MS SQL Server and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from an SAP ERP system running on DB2. It can also receive changes that occur to tables in real time. The only difference between this adapter and the DB2LogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata
This adapter retrieves data from an SAP ERP system running on Oracle. It can also receive changes that occur to tables in real time. The only difference between this adapter and the OracleLogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata.
This adapter retrieves data from an SAP ERP system running on SQL Server. It can also receive changes that occur to tables in real time. The only difference between this adapter and the MssqlLogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata.
This adapter retrieves data from DB2 for z/OS and can write back to a virtual table.
This adapter retrieves data from formatted and unformatted text files.
This adapter retrieves data from HADOOP.
This adapter retrieves data from an OData service.
This adapter retrieves data from SAP HANA and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from SAP ASE and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from Teradata and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
This adapter retrieves data from Twitter. It can also receive new data from Twitter in real time.
Objective: Reading data from flat file and loading it into a HANA CDS entity after transforming (performing concatenation, sorting and table comparison)
Below a sample csv file created with 4 columns and stored at the below path. In this case we have created a .txt file and stored it at the local machine. This file can be migrated to any distant server too.

C:\usr\sap\dataprovagent\FileServer
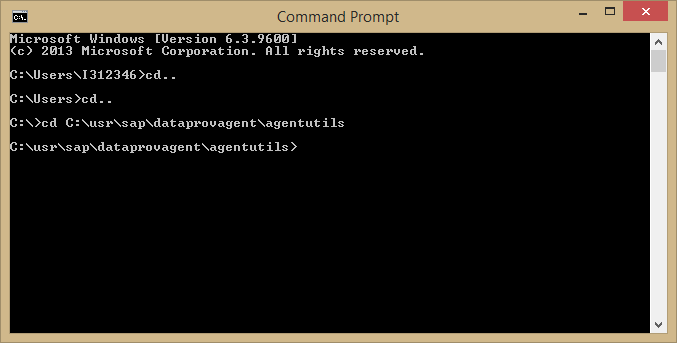
Open the windows command prompt and go the below path
C:\usr\sap\dataprovagent\agentutils
Run the following command
createfileformat.bat -file C:\usr\sap\dataprovagent\FileServer\<filename> -cfgdir C:\usr\sap\dataprovagent\FileServer\FileDefinitions

This DP agent utility would create a configuration file for the sourcetext file with the extension .cfg, this file can be found at the below location
C:\usr\sap\dataprovagent\FileServer\FileDefinitions

As we see, the columns re correctly read and the COLUMN_DELIMETER is automatically set as comma.
We will now create a remote source which will connect to the distant source to read the cfg file and the text file containing the data
Open the HANA Studio and run the below code snippet in SQL console:
<Agent> à IP address of the source server which is registered using DP agent
<User SID> à Type –whoami –user in the command prompt at the source server)
Check if the remote source is created the following path
Goto SYSTEMS tab à Provisioning à Remote Sources à <Source name> à <File name>

Right click on the file and create a virtual table to replicate data from flat file. Now our source has been created, which is a flat file.

A virtual table with prefix VT_ (specified by user) is created
The virtual table now has all columns and few additional ones from the source file

Create a new project in HANA studio and SHARE the same

Create a new file with extension .hdbdd and provide input in the following format
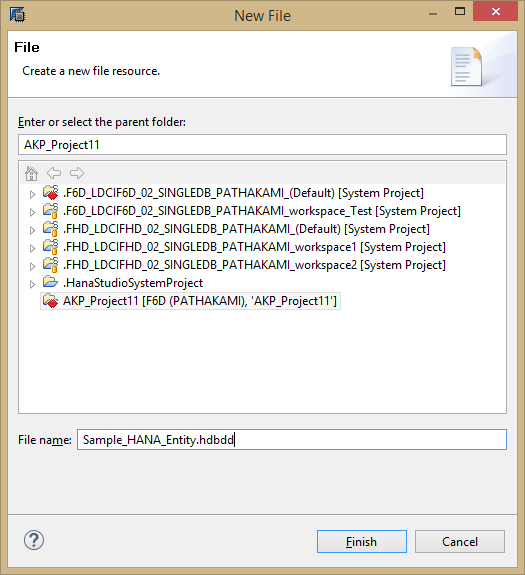
Define the columns, keys and the catalog object (refer the sample snippet below)
Right click and activate the file
A new column store table is created as below:

Now, within this project; create a new flowgraph, which will automatically be suffixed with .hdbflowtask


Create source by dragging from right palette

Create Target by dragging from right palette
The palette is an arrangement of transformations with similar functionality. Currently there are the following 4 palettes in HANA EIM:

Now we want to transform the data and perform the following transformations; Concatenation, Sorting, Table compare to load only the new and changed data
After adding the respective transformations, the final flowgraph looks like this:

Details of the transformation added:
Save and activate the flow graph:

Choose the execution option

Verify the data in target
Tip: You can use the below SQl to check the number of rows which have been affected by the flowgraph
So with this we complete the process of extracting, transforming and loading the data from a sample text file source to a HANA CDS entity
Special case: Handling versioning in flowgraph
Over here, as an extension to the prototype we have shown above, we would like to maintain a version of the data instead of removing or updating it.
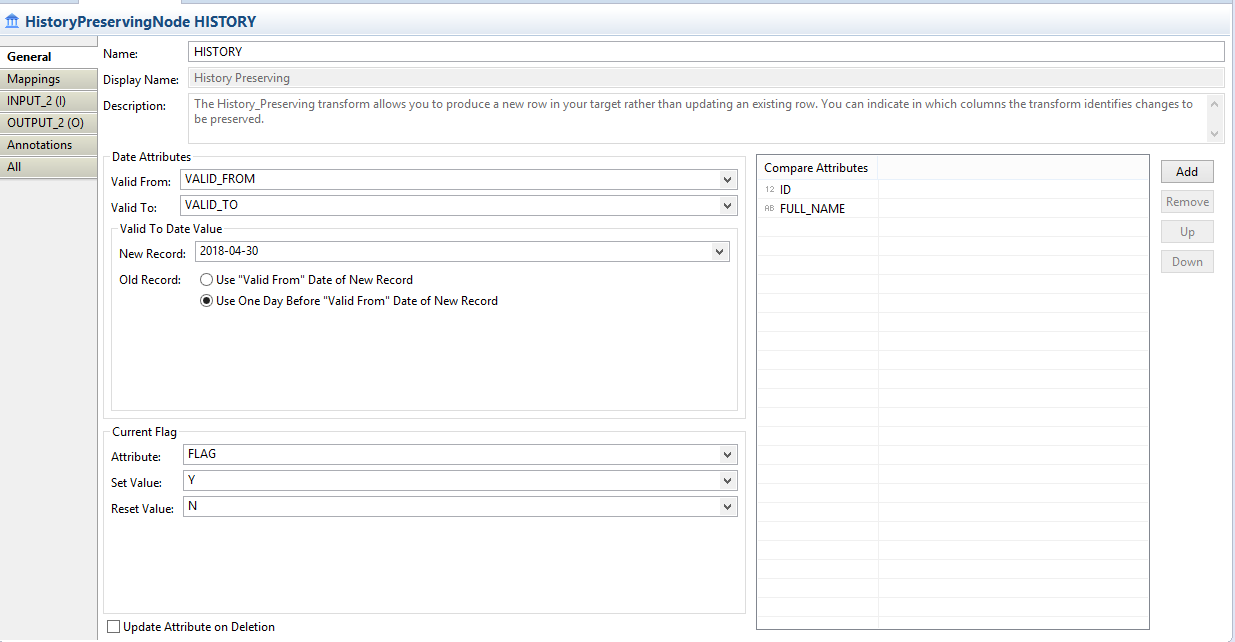
For this we will use a special transformation known as “HISTORY PRESERVING” transformation.
Just add this transformation to the existing flowgraph model (as shown below):

Now we need to set the configuration for this transformation (refer the screenshot below)
Once this is set, run save, activate and run the flowgraph.



[1]http://help.sap.com/saphelp_hana_options_eim/helpdata/en/cb/5eb74b179f4ded9a84224fe6e7ecf5/frameset....
[2]http://help.sap.com/download/multimedia/hana_options_eim/SAP_HANA_EIM_Administration_Guide_en.pdf
[3]SAP HANA Academy channel on Youtube
1 Objective of the Document. 2
2 Scope of the document. 3
3 product overview.. 3
3.1 SAP HANA Options. 3
3.1.1 SAP HANA Enterprise Information management (EIM) 3
3.1.2 Smart data integration. 3
3.1.3 Smart data quality. 3
4 Installation and configuration of EIM.. 4
4.1 Enable Data Provisioning server for SDI 5
4.2 Enable Script server for SDQ.. 5
4.3 Install delivery unit HANA_IM_DP (Data Provisioning) 5
4.4 Install and register Data Provisioning Agent 6
4.5 Once installed open the Data Provisioning agent 7
4.6 Make sure the agent is started, connect and register it with the necessary adapter ...
4.6.1 Open the SAP Data provisioning agent 8
4.6.2 Connect to HANA (Click on Connect to HANA button) 8
4.6.3 Register the agent 8
4.6.4 Start the agent 9
5 Register the file adapter. 10
5.1 IBM DB2 Log Reader: 11
5.2 Oracle Log Reader 11
5.3 MS SQL Server Log Reader 11
5.4 DB2 ECC. 11
5.5 Oracle ECC. 12
5.6 MS SQL Server ECC. 12
5.7 IBM DB2 for z/OS. 12
5.8 File. 12
5.9 Hive. 12
5.10 OData. 12
5.11 SAP HANA. 12
5.12 SAP ASE. 12
5.13 Teradata. 12
5.14 Twitter 12
6 Prototype : File Adapter. 12
6.1 Preparing the source file. 12
6.1.1 Converting the text file to a config file. 13
6.1.2 Creating a remote source. 14
6.1.3 Create a virtual table. 15
6.2 Preparing the target HANA CDS entity. 16
6.3 Creating a flowgraph to transform and move data from source to target 20
7 Open evaluation steps / Limitations. 23
8 Privileges required for HANA eim.. 25
9 References. 27
1 Objective of the Document
The scope of this document is to analyze the technical capabilities and functional feasibility of the Smart data Integration (SDI) and Smart data Quality (SDQ) appliances provided by HANA. This document also intends to throw some light over the product architecture and various transformational capabilities that can be achieved over the big data.
2 Scope of the document
The document will cover the various technical capabilities and the different interfaces that are a part of the tool. We would also be throwing some light on the available data sources in data provisioning agent which can be used to extract data. The document also explains the process of data transformation and loading using the flowgraph model provided by HANA.
3 Product Overview
SAP HANA is a modern in-memory platform that is deployable as an on-premise appliance or in the cloud. As an appliance, SAP HANA combines software components from SAP optimized on proven hardware provided by SAP’s hardware partners. In the cloud, SAP HANA is offered as a comprehensive infrastructure combined with managed services. SAP HANA can be deployed through the following cloud offerings: SAP HANA One, SAP HANA Cloud Platform and SAP HANA Enterprise Cloud.
3.1 SAP HANA Options
SAP offers options and additional capabilities for SAP HANA. To use these SAP HANA options and capabilities in a production system, you must purchase the appropriate software license from SAP. The SAP HANA options and capabilities listed below are available in connection with the platform and enterprise editions of SAP HANA, depending on the software license used.
3.1.1 SAP HANA Enterprise Information management (EIM)
Enterprise Information Management (EIM) enhances, cleanses, and transforms data to make it more accurate and useful. With the speed advantage of SAP HANA, the new SAP HANA EIM option can connect with any source, provision and cleanse data, and load data into SAP HANA on-premise or in the cloud, and for supported systems, it can write back to the original source .
The EIM capabilities in SAP HANA EIM offers:
- A simplified landscape — one environment in which to provision and consume data.
- Access to more data formats.
- In-memory performance, which means increased speed and decreased latency.
SAP HANA EIM consists of two main areas, smart data integration and smart data quality, as described below.
3.1.2 Smart Data Integration
Real-time, high-speed data provisioning, bulk data movement, and federation. SAP HANA EIM
Provides built-in adapters and an SDK so you can build your own Smart data integration includes the following features and tools:
- Replication Editor in the SAP HANA Web-based Development Workbench, which lets you set up batch or real-time data replication scenarios in an easy-to-use web application
- Smart data integration transformations, exposed as new nodes in the application function Modeler delivered with SAP HANA studio and SAP HANA Web-based Development Workbench, Which lets you set up batch or real-time data transformation scenarios
- Data provisioning agent, a lightweight component that hosts data provisioning adapters, Which enables data federation, replication and transformation scenarios for on-premise or in cloud Deployments
- Data provisioning adapters for connectivity to remote sources
- Adapter SDK to create custom adapters
- SAP HANA Cockpit integration for monitoring Data Provisioning agents, remote subscriptions and data loads
3.1.3 Smart Data Quality
Real-time, high-speed data provisioning, bulk data movement, and federation. SAP HANA EIM
provides built-in adapters and an SDK so you can build your own Smart data integration includes the following features and tools:
- Replication Editor in the SAP HANA Web-based Development Workbench, which lets you setup batch or real-time data replication scenarios in an easy-to-use web application
- Smart data integration transformations, exposed as new nodes in the application function modeler delivered with SAP HANA studio and SAP HANA Web-based Development Workbench, which lets you set up batch or real-time data transformation scenarios
- Data provisioning agent, a lightweight component that hosts data provisioning adapters, which enables data federation, replication and transformation scenarios for on-premise or incloud deployments
- Data provisioning adapters for connectivity to remote sources
- Adapter SDK to create custom adapters
- SAP HANA Cockpit integration for monitoring Data Provisioning agents, remote subscriptions and data loads
Fig 1 The HANA In Memory Platform extracts data from various data sources, This platform consists of the SDQ layer over the SDI layer and is synced with the current data
4 Installation and configuration of EIM
Fig 2: The SAP HANA EIM services are installed in the SAP HANA enterprise server, along with the core HANA components; the data provisioning agent tool will be installed at the source system, from where the source data is extracted. The SAP HANA server can then be accessed via front end tools like SAP HANA Studio which are shipped as part of core HANA bundle by SAP
4.1 Enable Data Provisioning server for SDI
When Hana is installed, by default the DP server is not activated, in order to have the ability to use SDI it needs to be enabled. The value needs to be change to 1
4.2 Enable Script server for SDQ
To take advantage of the SDQ functionality the script server value needs to be change to 1
4.3 Install delivery unit HANA_IM_DP (Data Provisioning)
The specific delivery unit needs to be downloading and upload from the studio or the web interface, this will provide you:
- The monitoring functionality
- The proxy application to provide a way to communicate with the DPA (cloud scenario)
- The admin application for DPA configuration (cloud scenario)https://support.sap.com/software/installations/a-z-index.html
4.4 Install and register Data Provisioning Agent
The Data Provisioning Agent is used to make the bridge between Hana and source system .Using the DPA allows live replication.
The agent is part of the package download earlier
Run and installed it as needed
Domain: Global\SAP_ID
4.5 Once installed open the Data Provisioning agent
4.6 Make sure the agent is started, connect and register it with the necessary adapter
4.6.1 Open the SAP Data provisioning agent
4.6.2 Connect to HANA (Click on Connect to HANA button)
4.6.3 Register the agent
To get the Agent Name / Agent Hostname : open command prompt à Type ‚ipconfig‘ à IPv4 address
4.6.4 Start the agent
5 Register the file adapter
All the adapters are by default deployed by the Data Provisioning agent, we just need to register the correct agent to read the data from that source
Fig 3: The various adapters responsible for extracting data from their respective sources interact with the adapter framework on the SAP HANA server
The various available adapters in data provisioning agent are:
5.1 IBM DB2 Log Reader:
This adapter retrieves data from DB2 and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
5.2 Oracle Log Reader
This adapter retrieves data from Oracle and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
5.3 MS SQL Server Log Reader
This adapter retrieves data from MS SQL Server and can write back to a virtual table. It can also receive and pass along changes that occur to tables in real time.
5.4 DB2 ECC
This adapter retrieves data from an SAP ERP system running on DB2. It can also receive changes that occur to tables in real time. The only difference between this adapter and the DB2LogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata
5.5 Oracle ECC
This adapter retrieves data from an SAP ERP system running on Oracle. It can also receive changes that occur to tables in real time. The only difference between this adapter and the OracleLogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata.
5.6 MS SQL Server ECC
This adapter retrieves data from an SAP ERP system running on SQL Server. It can also receive changes that occur to tables in real time. The only difference between this adapter and the MssqlLogReaderAdapter is that this adapter uses the data dictionary in the SAP ERP system when browsing metadata.
5.7 IBM DB2 for z/OS
This adapter retrieves data from DB2 for z/OS and can write back to a virtual table.
5.8 File
This adapter retrieves data from formatted and unformatted text files.
5.9 Hive
This adapter retrieves data from HADOOP.
5.10 OData
This adapter retrieves data from an OData service.
5.11 SAP HANA
This adapter retrieves data from SAP HANA and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
5.12 SAP ASE
This adapter retrieves data from SAP ASE and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
5.13 Teradata
This adapter retrieves data from Teradata and can write back to a virtual table (real-time only). It can also receive and pass along changes that occur to tables in real time.
5.14 Twitter
This adapter retrieves data from Twitter. It can also receive new data from Twitter in real time.
6 Prototype : File Adapter
Objective: Reading data from flat file and loading it into a HANA CDS entity after transforming (performing concatenation, sorting and table comparison)
6.1 Preparing the source file
Below a sample csv file created with 4 columns and stored at the below path. In this case we have created a .txt file and stored it at the local machine. This file can be migrated to any distant server too.
C:\usr\sap\dataprovagent\FileServer
6.1.1 Converting the text file to a config file
Open the windows command prompt and go the below path
C:\usr\sap\dataprovagent\agentutils
Run the following command
createfileformat.bat -file C:\usr\sap\dataprovagent\FileServer\<filename> -cfgdir C:\usr\sap\dataprovagent\FileServer\FileDefinitions
This DP agent utility would create a configuration file for the sourcetext file with the extension .cfg, this file can be found at the below location
C:\usr\sap\dataprovagent\FileServer\FileDefinitions
As we see, the columns re correctly read and the COLUMN_DELIMETER is automatically set as comma.
6.1.2 Creating a remote source
We will now create a remote source which will connect to the distant source to read the cfg file and the text file containing the data
Open the HANA Studio and run the below code snippet in SQL console:
CREATE REMOTE SOURCE "<Remote_src_Name>" ADAPTER "FileAdapter" AT LOCATION AGENT "<Agent>"
CONFIGURATION '<?xml version="1.0" encoding="UTF-8"?>
<ConnectionProperties name="ConnectionInfo">
<PropertyEntry name="rootdir">C:\usr\sap\dataprovagent\FileServer</PropertyEntry>
<PropertyEntry name="fileformatdir">C:\usr\sap\dataprovagent\FileServer\FileDefinitions</PropertyEntry>
</ConnectionProperties>'
WITH CREDENTIAL TYPE 'PASSWORD' USING
'<CredentialEntry name="AccessTokenEntry">
<password><user SID></password>
</CredentialEntry>';
<Agent> à IP address of the source server which is registered using DP agent
<User SID> à Type –whoami –user in the command prompt at the source server)
Check if the remote source is created the following path
Goto SYSTEMS tab à Provisioning à Remote Sources à <Source name> à <File name>
6.1.3 Create a virtual table
Right click on the file and create a virtual table to replicate data from flat file. Now our source has been created, which is a flat file.
A virtual table with prefix VT_ (specified by user) is created
The virtual table now has all columns and few additional ones from the source file
6.2 Preparing the target HANA CDS entity
Create a new project in HANA studio and SHARE the same
Create a new file with extension .hdbdd and provide input in the following format
Define the columns, keys and the catalog object (refer the sample snippet below)
namespace AKP_Project11;
@Schema: 'PATHAKAMI'
Context Test_HE{
@Catalog.tableType: #COLUMN
entity Test_HE{
key ID: hana.TINYINT;
FULL_NAME: hana.VARCHAR(200);
DESIGNATION: hana.VARCHAR(200);
}
}Right click and activate the file
A new column store table is created as below:
6.3 Creating a flowgraph to transform and move data from source to target
Now, within this project; create a new flowgraph, which will automatically be suffixed with .hdbflowtask
Create source by dragging from right palette
Create Target by dragging from right palette
The palette is an arrangement of transformations with similar functionality. Currently there are the following 4 palettes in HANA EIM:
- General: Contains basic SQL transformations like Source, target, Filter, Join, Sort etc.
- Data Provisioning: It contains the transformations which are specifically needed for change data capture / Data Provisioning. E.g. table comparison, History Preserving, Lookup etc.
- Predictive analysis library: Contains transformations which are used for analysis or predictive analysis. E.g. Social Network Analysis
- Business Function Library: Contains transformations which are of special use to customers for handling data. E.g. Annual Depreciation, Accumulate etc.
Now we want to transform the data and perform the following transformations; Concatenation, Sorting, Table compare to load only the new and changed data
After adding the respective transformations, the final flowgraph looks like this:
Details of the transformation added:
- Procedure: We are using a procedure in this case to concatenate the FIRST_NAME and the LAST_NAME columns. The procedure code looks like follows.
create procedure "PRO_CONCAT" (IN TT_IN "PATHAKAMI"."TT_IP_EMP" , OUT TT_OUT "PATHAKAMI"."TT_OP_EMP")
reads sql data as
begin
TT_OUT = select * from (select ID as ID , concat (FIRST_NAME , LAST_NAME) as FULL_NAME, DOB AS DOB, VALID_FROM as VALID_FROM,
VALID_TO as VALID_TO, FLAG as FLAG from :TT_IN);
end;- Table comparison: This transformation is responsible for comparing the source and target tables and load only the delta. In other words, only the new/updated rows in the source will be replicated to the target. This is an important factor for performance gain.
Save and activate the flow graph:
Choose the execution option
Verify the data in target
Tip: You can use the below SQl to check the number of rows which have been affected by the flowgraph
select Task_name, processed_records
from "SYS"."M_TASKS"
where end_time = (select MAX(END_TIME) from "SYS"."M_TASKS")
So with this we complete the process of extracting, transforming and loading the data from a sample text file source to a HANA CDS entity
7 Open evaluation steps / Limitations
- The scheduling of multiple flow graphs to run after each other is still to be evaluated, this is required in cases where multiple steps of loading are required in intermediate tables.
- The HANA Web IDE does not allow changing or editing the connections between different nodes of the various transformations.
- The performance of flowgraph for huge set of data is yet to be evaluated.
- Implicit data type conversions between co-related data types like INTEGER and TINYINT is not handled within the flowgraph.
- While creating the HANA CDS entity, we have to explicitly specify and type each and every column, key which we need in the entity; going further we would expect to build a HANA CDS entity directly on top of an existing table in HANA.
- The Business Function Library and Predictive Analysis Library are yet to be evaluated.
- Version handling (especially two-dimensional versioning) in FRDP is to be evaluated using this tool.
- Functioning of this tool with HANA in cloud is to be evaluated…
Special case: Handling versioning in flowgraph
Over here, as an extension to the prototype we have shown above, we would like to maintain a version of the data instead of removing or updating it.
For this we will use a special transformation known as “HISTORY PRESERVING” transformation.
Just add this transformation to the existing flowgraph model (as shown below):
Now we need to set the configuration for this transformation (refer the screenshot below)
Once this is set, run save, activate and run the flowgraph.
8 Privileges required for HANA EIM
9 References
[1]http://help.sap.com/saphelp_hana_options_eim/helpdata/en/cb/5eb74b179f4ded9a84224fe6e7ecf5/frameset....
[2]http://help.sap.com/download/multimedia/hana_options_eim/SAP_HANA_EIM_Administration_Guide_en.pdf
[3]SAP HANA Academy channel on Youtube
- SAP Managed Tags:
- SAP HANA
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- FAQ for C4C Certificate Renewal in Technology Blogs by SAP
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Mistral gagnant. Mistral AI and SAP Kyma serverless. in Technology Blogs by SAP
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- It’s Official - SAP BTP is Again a Leader in G2’s Reports in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 13 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |