
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- HANA based BW Transformation
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-24-2016
5:13 PM
1 HANA based BW Transformation
What is a SAP HANA push down in the context of BW transformations? When does a push down occur? What are the prerequisites for forcing a SAP HANA push down?
Before I start to explain how a SAP HANA based BW transformation could be created and what prerequisites are necessary to force a push down I will provide some background information on the differences between an ABAP and SAP HANA executed BW transformation.
A HANA based BW transformation executes the data transformation logic inside the SAP HANA database. Figure 1.1 shows on the left-hand side the processing steps for an ABAP based transformation and on the right-hand side for a SAP HANA based transformation.
This blog provides information on the push-down feature for transformations in SAP BW powered by SAP HANA. The content here is based on experiences with real customer issues. The material used is partly taken from the upcoming version of the SAP education course PDEBWP - BW Backend und Programming. (Updated on 05/06/2019)
| PDEBWP - BW Backend und Programming - BW and Best Practices |
|---|
In this course you will be taught those specialist skills which are indispensable for every BW consultant, learning first-hand from a trainer/consultant with many years of project experience. The course starts with data extraction and how DataSources (including ODP) should be enhanced and/or created.Next data staging is tackled and how the dataflow can best be influenced with ABAP and/or SQL-script. It is not just about having high performance code, but also how to model the data architecture. Additionally, reporting, authorisations and planning (BI-IP/BPC) are examined and how to best implement one’s own coding. This 5 day course is full of practical exercises and is a “must” for every BW consultant. |
This blog is planned as part of a blog series which shares experiences collected while working on customer issues. The listed explanations are primarily based on releases between BW 7.40 SP09 and BW 7.5 SP00.
The following additional blogs are planned / available:
- HANA based Transformation (deep dive) (Added on 06/17/2016)
- HANA based BW Transformation - Analyzing and debugging(Added on 06/23/2016)
- SAP HANA Analysis Process
- General recommendation (Added on 03/24/2017)
- HANA based BW Transformation - New features delivered by 7.50 SP04 (Added on 08/29/2016)
- Routines
- Error Handling
- HANA based BW Transformation - SAP Notes (Added on 06/09/2016)
A HANA based BW transformation is a “normal” BW transformation. The new feature is that the transformation logic is executed inside the SAP HANA database. From a design time perspective, in the Administrator Workbench, there is no difference between a HANA based BW transformation and a BW transformation that is executed in the ABAP stack. By default the BW runtime tries to push down all transformations to SAP HANA. Be aware that there are some restrictions which prevent a push down. For example a push-down to the database (SAP HANA) is not possible if a BW transformation contains one or more ABAP routines (Start-, End-, Expert- or Field-Routine). For more information see Transformations in SAP HANA Database.
| Restrictions for HANA Push-Down |
|---|
Further restrictions are listed in the Help Portal. However, the documentation is not all-inclusive. Some restrictions related to complex and "hidden" features in a BW transformation are not listed in the documentation. In this context “hidden” means that the real reason is not directly visible inside the BW transformation. The BAdI RSAR_CONNECTOR is a good example for such a “hidden” feature. A transformation using a customer specific formula implementation based on this BAdI cannot be pushed down. In this case the processing mode is switched to ABAP automatically. The BW workbench offers a check button in the BW transformation UI to check if the BW transformation is “SAP HANA executable” or not. The check will provide a list of the features used in the BW transformation which prevent a push down. |
SAP is constantly improving the push down capability by eliminating more and more restrictions In order to implement complex customer specific logic inside a BW transformation it is possible to create SAP HANA Expert Script based BW transformations. This feature is similar to the ABAP based Expert-Routine and allows customers to implement their own transformation logic in SQL Script. A detailed description of this feature is included later on.
SAP Note 2057542 - Recommendation: Usage of HANA-based Transformations provides some basic information and recommendations regarding the usage of SQL Script inside BW transformations.
1.1 HANA Push-Down
What is a SAP HANA push down in the context of BW transformations? When does a push down occur? What are the prerequisites for forcing a SAP HANA push down?
Before I start to explain how a SAP HANA based BW transformation could be created and what prerequisites are necessary to force a push down I will provide some background information on the differences between an ABAP and SAP HANA executed BW transformation.
A HANA based BW transformation executes the data transformation logic inside the SAP HANA database. Figure 1.1 shows on the left-hand side the processing steps for an ABAP based transformation and on the right-hand side for a SAP HANA based transformation.

Figure 1.1: Execution of SAP BW Transformations
An ABAP based BW transformation loads the data package by package from the source database objects into the memory of the Application Server (ABAP) for further processing. The BW transformation logic is executed inside the Application Server (ABAP) and the transformed data packages are shipped back to the Database Server. The Database Server writes the resulting data packages into the target database object. Therefore, the data is transmitted twice between database and application server.
During processing of an ABAP based BW transformation, the source data package is processed row by row (row-based). The ABAP based processing allows to define field-based rules, which are processed as sequential processing steps.
For the HANA based BW transformation the entire transformation logic is transformed into a CalculationScenario (CalcScenario). From a technical perspective the Metadata for the CalcScenario are stored as a SAP HANA Transformation in BW (see transaction RSDHATR).
This CalcScenario is embedded into a ColumnView. To select data from the source object, the DTP creates a SQL SELECT statement based on this ColumnView (see blog »HANA based BW Transformation - Analyzing and debugging«) and the processing logic of the CalcScenario applies all transformation rules (defined in the BW transformation) to the selected source data. By shifting the transformation logic into the CalcScenario, the data can be transferred directly from the source object to the target object within a single processing step. Technically this is implemented as an INSERT AS SELECT statement that reads from the ColumnView and inserts into the target database object of the BW transformation. This eliminates the data transfer between Database Server and Application Server (ABAP). The complete processing takes place in SAP HANA.
1.2 Create a HANA based BW Transformation
The following steps are necessary to push down a BW transformation:
- Create a SAP HANA executable BW transformation
- Create a Data Transfer Process (DTP) to execute the BW transformation in SAP HANA
1.2.1 Create a standard SAP HANA executable BW transformation
A standard SAP HANA executable BW transformation is a BW transformation without SAP HANA specific implementation, which forces a SAP HANA execution.
The BW Workbench tries to push down new BW transformations by default.
The activation process checks a BW transformation for unsupported push down features such as ABAP routines. For a detailed list of restrictions see SAP Help -Transformations in SAP HANA Database. If none of these features are used in a BW transformation, the activation process will mark the BW transformation as SAP HANA Execution Possible see (1) in Figure 1.2.

Figure 1.2: First simple SAP HANA based Transformation
When a BW transformation can be pushed down, the activation process generates all necessary SAP HANA runtime objects. The required metadata is also assembled in a SAP HANA Transformation (see Transaction RSDHATR). The related SAP HANA Transformation for a BW transformation can be found in menu Extras => Display Generated HANA Transformation, see (2) in Figure 1.2.
From a technical perspective a SAP HANA Transformation is a SAP HANA Analysis Process (see Transaction RSDHAAP) with a strict naming convention. The naming convention for a SAP HANA Transformation is TR_<< Program ID for Transformation (Generated)>>, see (3) in Figure 1.2. A SAP HANA Transformation is only a runtime object which cannot not been explicit created or modified.
The tab CalculationScenario is only visible if the Export Mode (Extras => Export Mode On/Off) is switched on. The tab shows the technical definition of the corresponding CalculationScenario which includes the transformation logic and the SQLScript procedure (if the BW transformation is based on a SAP HANA Expert Script).
If the transformation is marked as SAP HANA Execution Possible, see (1) in Figure 1.2 the first precondition is given to push down and execute the BW transformation inside the database (SAP HANA). That means if the flag SAP HANA Execution Possible is set the BW transformation is able to execute in both modes (ABAP and HANA) and the real used processing mode is set inside the DTP. To be prepared for both processing modes the BW transformation framework generates the runtime objects for both modes. Therefore the Generated Program (see Extras => Display Generated Program) for the ABAP processing will also be visible.
The next step is to create the corresponding DTP, see paragraph 1.2.4 »Create a Data Transfer Process (DTP) to execute the BW transformation in SAP HANA«.
1.2.2 Create a SAP HANA transformation with SAP HANA Expert Script
If the business requirement is more complex and it is not possible to implement these requirements with the standard BW transformation feature, it is possible to create a SQLScript procedure (SAP HANA Expert Script). When using a SAP HANA Expert Script to implement the business requirements the BW framework pushes the transformation logic down to the database. Be aware that there is no option to execute a BW transformation with a SAP HANA Expert Script in the processing mode ABAP, only processing mode HANA applies.
From the BW modelling perspective a SAP HANA Expert Script is very similar to an ABAP Expert Routine. The SAP HANA Expert Script replaces the entire BW transformation logic. The SAP HANA Expert Script has two parameters, one importing (inTab) and one exporting (outTab) parameter. The importing parameter provides the source data package and the exporting parameter is used to return the result data package.
However, there are differences from the perspective of implementation between ABAP and SQLScript. An ABAP processed transformation loops over the source data and processes them row by row. A SAP HANA Expert Script based transformation tries to processes the data in one block (INSERT AS SELECT). To get the best performance benefit of the push down it is recommended to use declarative SQLScript Logic to implement your business logic within the SAP HANA Expert Script, see blog »General recommendations«.
The following points should be considered before the business requirements are implemented with SAP HANA Expert Script:
- ABAP is from today's perspective, the more powerful language than SQL Script
- Development support features such as syntax highlighting, forward navigation based on error messages, debugging support, etc. is better in the ABAP development environment.
- SQL script development experience is currently not as widespread as ABAP development experience
- A HANA executed transformation is not always faster
From the technical perspective the SAP HANA Expert Script is a SAP HANA database procedure. From the BW developer perspective the SAP HANA Expert Script is a SAP HANA database procedure implemented as a method in an AMDP (ABAP Managed Database Procedure) class.
The AMDP class is be generated by the BW framework and can only be modified within the ABAP Development Tools for SAP NetWeaver (ADT), see https://tools.hana.ondemand.com/#abap. The generated AMDP class cannot not be modified in the SAP GUI like Class editor (SE24) or the ABAP Workbench (SE80). Therefore it is recommended to implement the entire dataflow in the Modeling Tools for SAP BW powered by SAP HANA, see https://tools.hana.ondemand.com/#bw. The BW transformation itself must still be implemented in the Data Warehousing Workbench (RSA1).
Next I’ll give a step by step introduction to create a BW transformation with a SAP HANA Expert Script.
Step 1: Start a SAP HANA Studio with both installed tools:
- ABAP Development Tools for SAP NetWeaver (ADT) and
- Modeling Tools for SAP BW powered by SAP HANA
Now we must switch into the BW Modeling Perspective. To open the BW Modeling Perspective go to Window => Other .. and select in the upcoming dialog the BW Modeling Perspective, see Figure 1.3.

Figure 1.3: Open the BW Modeling Perspective
To open the embedded SAP GUI a BW Project is needed. It is necessary to create the BW Project before calling the SAP GUI. To create a new BW Project open File => New => BW Project. To create a BW Project a SAP Logon Connection is required, choose the SAP Logon connection and use the Next button to enter your user logon data.
Recommendations: After entering your logon data it is possible to finalize the wizard and create the BW Project. I recommend to use the Next wizard page to change the project name. The default project name is:
<System ID>_<Client>_<User name>_<Language>
I normally add at the end a postfix for the project type such as _BW for the BW Project. For an ABAP project later on I will use the postfix _ABAP. The reason I do that is both projects are using the same symbol in the project viewer and the used postfix makes it easier to identify the right project.
Once the BW Project is created we can open the embedded SAP GUI. The BW Modeling perspective toolbar provides a button to open the embedded SAP GUI, see Figure 1.4.

Figure 1.4: Open the embedded SAP GUI in Eclipse
Choose the created BW Project in the upcoming dialog. Next start the BW Workbench (RSA1) within the embedded SAP GUI and create the BW transformation or switch into the edit mode for an existing one.
To create a SAP HANA Expert Script open Edit => Routines => SAP HANA Expert Script Create in the menu of the BW transformation. Confirm the request to delete the existing transformation logic. Keep in mind that all implemented stuff like Start- End- or Field-Routines and formulas will be deleted if you confirm to create a SAP HANA Expert Script.
In the next step the BW framework opens the AMDP class by calling the ABAP Development Tools for SAP NetWeaver (ADT). For this an ABAP project is needed. Select an existing ABAP Project or create a new one in the dialog.
A new window with the AMD class will appear. Sometimes it is necessary to reload the AMDP class by pressing F5. Enter your credentials if prompted.
The newly generated AMDP class, see Figure 1.5, cannot not directly be activated.

Figure 1.5: New generated AMDP Class
Before I explain the elements of the AMDP class and the method I will finalize the transformation with a simple valid SQL statement. The used SQL statement, as shown in Figure 1.6, is a simple 1:1 transformation and is only used as an example to explain the technical behavior.

Figure 1.6: Simple valid AMDP Method
Now we can activate the AMDP class and go back to the BW transformation by closing the AMDP class window. Now it is necessary to activate the BW transformation also. For a BW transformation with a SAP HANA Expert Script the flag SAP HANA Execution possible is set, see Figure 1.7.

Figure 1.7: BW Transformation with SAP HANA Script Processing
As explained before, if you use a SAP HANA Expert Script the BW transformation can only been processed in SAP HANA. It is not possible to execute the transformation on the ABAP stack. Therefore the generated ABAP program (Extras => Display Generated Program) is not available for a BW transformation with the processing type SAP HANA Expert Script.
1.2.2.1 Sorting after call of expert script
Within the BW transformation the flag Sorting after call of expert script, see Figure 1.8, (Edit => Sorting after call of expert script) can be used to ensure that the data is written in the correct order to the target.
 Figure 1.8: Sorting after call of expert script
Figure 1.8: Sorting after call of expert script If the data is extracted by delta processing the sort order of the data could be important (depending on the type of the used delta process).
By default, the flag is always set for all new transformations and it’s recommended to leave it unchanged.
For older transformations, created with a release before 7.40 SP12, the flag is not set by default. So the customer can set the flag if they need the data in a specific sort order.
Keep in mind that the flag has impact at two points:
- The input/output structure of the SAP HANA Expert Script is enhanced / reduced by the field RECORD
- The result data from the SAP HANA Expert Script will be sorted by the new field RECORD, if the flag is set, after calling the SAP HANA Expert Script
The inTab and the outTab structure of a SAP HANA Expert Script will be enhanced by the field RECORD if the flag is set. The added field RECORD is a combination of the fields REQUESTSID, DATAPAKID and RECORD from the source object of the transformation, see Figure 1.9.

Figure 1.9: Concatenated field RECORD
The RECORD field from the outTab structure is mapped to the internal field #SOURCE#.1.RECORD. Later on in a rownum node of the CalculationScenario the result data will be sorted by the new internal field #SOURCE#.1.RECORD, see Figure 1.10.
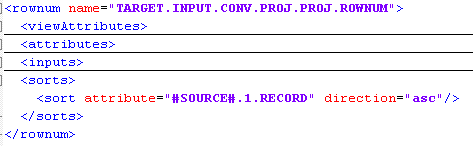
Figure 1.10: CalculationScenario note rownum
1.2.2.2 The AMDP Class
The BW transformation framework generates an ABAP class with a method called PROCEDURE. The class implements the ABAP Managed Database Procedure (AMDP) marker interface IF_AMDP_MARKER_HDB. The interface marks the ABAP class as an AMDP class. A method of an AMDP class can be written as a database procedure. Therefore the BW transformation framework creates a HANA specific database procedure declaration for the method PROCEDURE, see Figure 1.11:

Figure 1.11: Method PROCEDURE declaration
This declaration specifies the method to the HANA database (HDB), the language to SQLSCRIPT and further on defines that the database procedure is READ ONLY. The read only option means that the method / procedure must be side-effect free. Side-effect free means that only SQL elements (DML) could be used to read data. Elements like DELETE, UPDATE, INSERT used on persistent database objects are not allowed. These data modification statements can also not be encapsulated in a further procedure.
You cannot directly read data from a database object managed by ABAP like a table, view or procedure inside an AMDP procedure, see (1) in Figure 1.12. A database object managed by ABAP has to be declared before they can used inside an AMDP procedure, see (2). For more information about the USING option see AMDP - Methods in the ABAP documentation.
| Modification of the method declaration |
|---|
In case of reading from further tables inside the SQL Script it could be necessary to change (enhance) the method declaration by adding the USING option. It is important to ensure that the first part of the method declaration is stable and will not be changed. Do not change the following part of the declaration:
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY
The USING option must be added at the end of the declaration part, see Figure 1.12 |

Figure 1.12: Declaration of DDIC objects
The AMDP framework generates wrapper objects for the declared database object managed by ABAP . The view /BIC/5MDEH7I6TAI98T0GHIE3P69D1=>/BIC/ATK_RAWMAT2#covw in (3) was generated for the declared table /BIC/ATK_RAWMAT2 in (2). The blog Under the HANA hood of an ABAP Managed Database Procedure provides some further background information about AMDP processing and which objects are generated.
| AMDP Class modification |
|---|
Only the method implementation belongs to the BW transformation Meta data and only this part of the AMDP class would been stored, see table RSTRANSCRIPT. Currently the ABAP Development Tools for SAP NetWeaver (ADT) does not protect the source code which should not been modified, like in an ABAP routine. That means all modifications in the AMDP class outside the method implementation will not be transported to the next system and will be overwritten by the next activation process. The BW transformation framework regenerates the AMDP class during the activation process. |
| Reading from local table without DDIC information |
|---|
| All tables and views from the local SAP schema must be declared in the USING clause and must be defined in the ABAP DDIC. It is possible to read data from other schema without a declaration in the USING clause. If a table or view in the local SAP schema starts with the prefix /1BCAMDP/ it is not necessary to declare the table/view in the USING clause. |
Later on I’ll provide some general recommendations in a separate blog which are based on experiences we collected in customer implementations and customer incidents. The general recommendation will cover the following topics:
- Avoid preventing filter push down
- Keep internal table small
- Initial values
- Column type definition
- Avoid implicit casting
- Use of DISTINCT
- Potential pitfall at UNION / UNION ALL
- Input Parameter inside underlying HANA objects
- Internal vs. external format
- ...
| AMDP Class name |
|---|
Until version BW 7.50 SP04 the AMDP class name is generated based on the field RSTRAN-TRANPROG. From BW 7.50 SP04 the field RSTRAN-EXPERT is used to generate the AMDP class name. The metadata storage for the AMDP routines was adjusted to align the AMDP metadata storage analogous to the ABAP metadata. |
| AMDP database procedure |
|---|
Sometime, in BW 7.40, it could be happen that the corresponding database procedure is not generated. The report RSDBGEN_AMDP can be used to generate the database procedures for a given AMDP class. |
1.2.3 Dataflow with more than one BW transformation
The push down option is not restricted on data flows with one BW transformation. It is also possible to push down a complete data flow with several included BW transformations (called stacked data flow). To get the best performance benefits from the push down it is recommended to stack a data flow by a maximum of three BW transformations. More are possible but not recommended.
The used InfoSources (see SAP Help: InfoSource and Recommendations for Using InfoSources) in a stacked data flow can be used to aggregate data within the data flow if the processing mode is set to ABAP. If the processing mode set to SAP HANA the data will not be aggregated as set in the InfoSource settings. The transformation itself does not know the processing mode, therefore you will not get a message about the InfoSource aggregation behavior. The used processing mode is set in the used DTP.
That means, the BW transformation framework prepares the BW transformation for both processing modes (ABAP and HANA). During the preparation the framework will not throw a warning regarding the lack of aggregation in the processing mode HANA.
By using the check button for the HANA processing mode, within the BW transformation, you will get the corresponding message (warning) regarding the InfoSource aggregation, see Figure 1.13

Figure 1.13: HANA processing and InfoSources
| CalculationScenario in a stacked data flow |
|---|
The corresponding CalculationScenario for a BW transformation is not available if the source object is an InfoSource. That means the tab CalculationScenario is not available in the export mode of the SAP HANA transformation, see Extras => Display Generated HANA Transformation. The source object for this CalculationScenario is an InfoSource and an InfoSource cannot be used as data source object in a CalculationScenario. The related CalculationScenario can only be obtain by using the SAP HANA Transformation from the corresponding DTP. I’ll explain this behavior later on in the blog »HANA based Transformation (deep dive)«. |
1.2.4 Create a Data Transfer Process (DTP) to execute the BW transformation in SAP HANA
The Data Transfer Process (DTP) to execute a BW transformation provides a flag to control the HANA push-down of the transformation. The DTP flag SAP HANA Execution, see (1) in Figure 1.14, can be checked or unchecked by the user. However, the flag in the DTP can only be checked if the transformation is marked as SAP HANA Execution Possible, see (1) in Figure 1.2. By default the flag SAP HANA Execution will be set for each new DTP if
- the BW transformation is marked as SAP HANA execution possible and
- the DTP does not use any options which prevent a push down.
Up to BW 7.50 SP04 the following DTP options prevent a push down:
- Semantic Groups
- Error Handling - Track Records after Failed Request
The DTP UI provides a check button, like the BW transformation UI, to validate a DTP for HANA push down. In case a DTP is not able to push down the data flow (all involved BW transformations) logic, the check button will provide the reason.

Figure 1.14: DTP for the first simple SAP HANA based Transformation
In the simple transformation sample above I’m using one BW transformation to connect a persistent source object (DataSource (RSDS)) with a persistent target object (Standard DataStore Object (ODSO)). We also call this type a non-stacked dataflow - I’ll provide more information about non-stacked and stacked data flows later. The related SAP HANA Transformation for a DTP can be found in menu Extras => Display Generated HANA Transformation, see (2) in Figure 1.14. In case of a non-stacked data flow the DTP uses the SAP HANA Transformation of the BW transformation, see (3) in Figure 1.14.
The usage of a filter in the DTP does not prevent the HANA push down. ABAP Routines or BEx Variables can be used as well. The filter value(s) is calculated in a pre-step and added to the SQL SELECT statement which reads the data from the source object. We will look into this later in more detail.
1.2.5 Execute a SAP HANA based transformation
From the execution perspective, regarding the handling, a HANA based transformation behaves comparable to an ABAP based transformation, simply press the 'Execute' button or execute the DTP form a process chain.
Later on I will provide more information about packaging and parallel processing.
1.2.6 Limitations
There is no option to execute a transformation with a SAP HANA Script on the ABAP application server. With BW 7.50 SP04 (the next feature pack) it is planned to deliver further option to use SAP HANA Scripts (Start-, End- and Field-Routines are planned) within a BW transformation.
1.2.7 Feature list that prevents a push down (Added on 07/20/2016)
The official SAP Help provides a small feature list which prevents a HANA execution. Here are a more detailed list:
- Queries as InfoProvider are not supported as thesource
- ABAP Start-, End- and Field-Routines
- With BW 7.50 SP04 corresponding SQL Script routines are supported
- Formula elements that prevents a push down
- DATECONV,
- WEEK_TO_1ST_DAY,
- FISCPER_CALMONTH,
- CALMONTH_FISCPER,
- CONDENSE,
- ABORT_PACKAGE,
- SKIP_RECORD,
- SKIP_RECORD_AS_ERROR
- LOG_MESSAGE
- Customer created formulas (BAdI RSAR_CONNECTOR)
- Transfer routineCharacteristic- / InfoObject – Routine) are not supported
- 0SOURSYSTEM and 0LOGSYS are supported
- To use the field routine logic within a HANA transformation a constant rule with an initial "Constant Value" is required! (Added on 01/16/2019)
- 0SOURSYSTEM and 0LOGSYS are supported
- Rule typeTIME (Time Characteristic) with Time Distribution are not supported
- Rule groups are not supported
- InfoObject with time-dependent Attributes are not supported as source and as target
- Supported with BW 7.50 SP04
- Cube like DataStore Objects (advanced) are not supported as target
- Supported with BW 7.50 SP04
- DataStore Objects (advanced) with non-cumulative key figure(s) are not supported as target
- Supported with BW 7.50 SP04
- To read data from DataStore objects, the entire key must be provided
- Near-line connections
- Supported with BW 7.50 SP04 (Added on 09/21/2016)
- DTP Options
- Error Handling not supported
- Supported with BW 7.50 SP04
- Semantic Groups
- Error Handling not supported
Further information about supported SAP HANA execution feature are provided in the SAP note: 2329819 - SAP HANA execution in DTPs (Data Transfer Processes) - Optimizations.
- SAP Managed Tags:
- BW (SAP Business Warehouse),
- SAP HANA
Labels:
97 Comments
- « Previous
-
- 1
- 2
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
274 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
327 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
405 -
Workload Fluctuations
1
Related Content
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Navigation with filters inside a Fiori Elements oData v4 app in Technology Q&A
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- SAP Enable Now setup in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |