
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA SPS 12: New Developer Features; Database ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-20-2016
4:12 PM
In this blog, I would like to introduce you to the new features for the database developer in SAP HANA 1.0 SPS12. We will focus more on the database development topic including the HANA Deployment Infrastructure, Core Data Services, as well as SQLScript. If you are interested in the new features for XS Advanced(XSA), or the SAP WebIDE for SAP HANA, please check out this blog by my colleague thomas.jung.
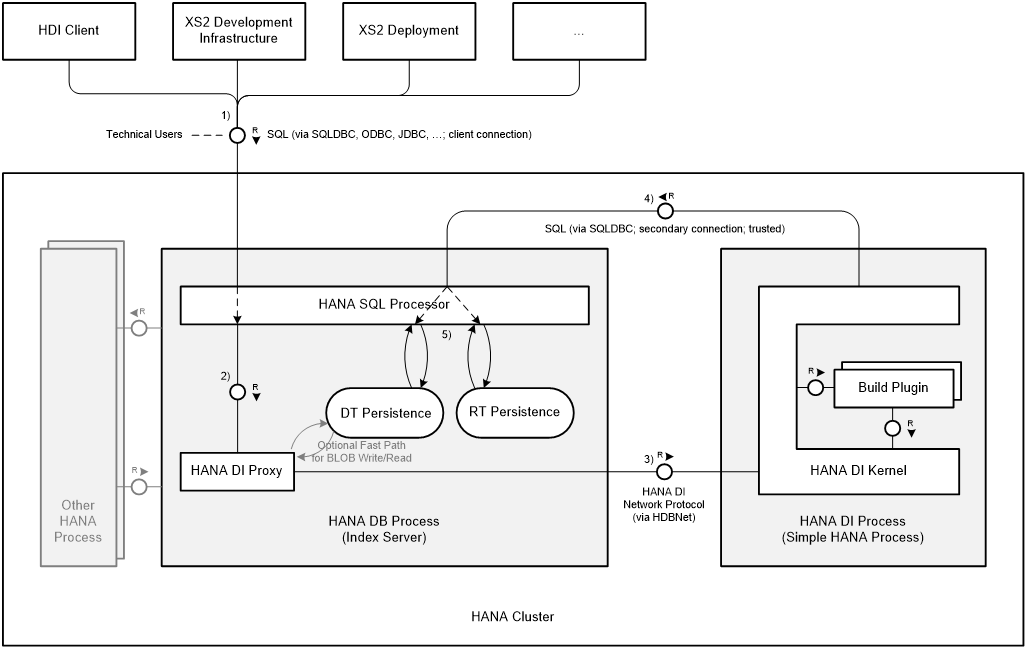
HANA Deployment Infrastructure(HDI)
The HANA Deployment Infrastructure, HDI for short, was first introduced in HANA 1.0 SPS11 as part of the rollout of XS Advanced(XSA). While XSA was officially released, at the time there was very little tooling for XSA, and the developer experience was not quite complete. Now that we have shipped the SAP HANA WebIDE for SAP HANA back in mid March, we’ve improved the experience quite a bit and filled several important gaps. So with SPS12, we want to re-introduce the concept of the HANA Deployment Infrastructure.
The vison of the HANA Deployment infrastructure is to simplify the deployment of database objects into the HANA database. We wanted to describe the HANA persistency model using file based design time artifacts, for exampele .hbdcds and .hdbprocedure files, and so on. We wanted an all-or-nothing approach, so if there are many dependent artifacts within your container, and any one of them fail to get created in the DB, then the entire build will fail and nothing gets created. We wanted a dependency based incremental deployment, which means we don’t want to drop everything and recreate it every time we build, we only want the changed objects to be adjusted. We wanted complete isolation of the applications database objects. This is achieved by the concept of containers, where each container corresponds to an underlying schema. This adds additional security since each underlying schema, containing its deployed objects, is owned by a specific schema technical user.
Defined, HANA Deployment Infrastructure is a service layer of the HANA database that simplifies the deployment of HANA database artifacts by providing a declarative approach for defining database objects and ensuring a consistent deployment into the database, based on a transactional all-or-nothing deployment model and implicit dependency management. HDI is based on the concept of containers, which allows for multiple deployments of the same application. This means you could have two versions of the same application running on the same HANA instance at the same time. Additionally, the focus of HDI is deployment only, so there is no versioning or life cycle management built into it. You would use Git for repository and version management, and Gerrit for code review and approvals workflow. Lastly, HDI supports the creation of database object only, so it does not support javascript, odata services, or any other application layer artifacts.
Again, we use a container concept in HDI where each container is a database schema. Actually it is a set of schemas, one main schema where the runtime objects reside, and several other supporting schemas used by the infrastructure itself. All of the artifact definitions, such as a CDS file, need to be defined in a schema-free way, where as in the past, you would put a schema annotation in your CDS file. This is no -longer supported when using XSA/HDI. The database objects within the container are owned by a container specific technical user and only this user has access to the objects within that container. You can reference other artifacts outside of your container via database synonyms.
HDI lives on top of the database conceptually. The HDI build interface is implemented as a node.js module. This node.js module simply calls the HDI APIs within HANA. This set of HDI APIs, which are implemented as stored procedures, are actually copied into each container schema in HANA, so each container gets its own copy of the API upon creation. Within these APIs, of course we are simply using SQL to create the runtime objects themselves. Finally, HDI runs inside its own process as part of the overall HANA core, one process per logical database.
The following is a list of artifacts which are supported by HDI. New artifacts added as of SPS12 largely deal with Text Analysis and Text Mining.
| Tables | Synonyms & Configurations | Public Synonyms |
| Virtual Tables & Configurations | Roles | Text Analysis Configuration |
| Indexes | BI Views/Calculation Views | Text Analysis Dictionaries |
| Fulltext Indexes | Core Data Services | Text Analysis Extraction Rules |
| Constraints | Data Control Language(DCL) | Text Analysis Extraction Rules Includes |
| Triggers | Analytical Privileges | Text Analysis Extraction Rules Lexicons |
| Views | AFFLANG Procedures | Text Mining Configurations |
| Projection Views & Configurations | Virtual Function Packages | |
| Scalar/Table Functions | Table Data w/ CSV Files | |
| Virtual Functions & Configurations | Table Data w/ Properties Files | |
| Table Types | Search Rule Sets | |
| Procedures | Flowgraph | |
| Procedure Libraries | Replication Task | |
| Sequences | Structured Privileges | |
| Graph Workspaces |
Core Data Services(CDS)
There have been several new features added in SPS12 for Core Data Services, or CDS. CDS was introduced in HANA 1.0 SPS06 and continues to be enriched with each SPS.
Graphical Editor
We introduced a new graphical editor for CDS artifacts in the SAP WebIDE for SAP HANA during the SPS11 delivery of the tool. This new graphical editor displays types as well as entities and views. It also shows the associations between entities as well as external dependencies. Of course you still have the ability to open the CDS artifact via the text editor as well.

Auto Merge
AUTO MERGE has been supported for quite some time with HANA core SQL, but only now supported in the context of CDS with SPS12. AUTO MERGE is used to enable the automatic delta merge. You can simply include AUTO MERGE or NO AUTO MERGE within the technical configuration section of an entity definition.
entity MyEntity {
<element_list>
} technical configuration {
[no] auto merge;
};
Index Sort Order
As of SPS12, within the definition of an index, you can now define the sort order per column. You can use ASC for ascending order, and DESC for descending order. You have the option to sort by a column grouping or by an individual column. Ascending is the default order when the order specification is omitted.
entity MyEntity {
key id : Integer;
a : Integer;
b : Integer;
c : Integer;
s {
m : Integer;
n : Integer;
};
} technical configuration {
index MyIndex1 on (a, b) asc;
unique index MyIndex2 on (c asc, s desc);
index MyIndex3 on (c desc, s.n);
};
Explicit Specification of CDS Types for View Elements
In a CDS view definition, it is now possible in SPS12 to specify the type of a select item based on an expression. For example, in the following example, if you define a column as A + B as S1, the resulting type is lost. You can now explicitly define the type.
type MyInteger : Integer;
entity E {
a : MyInteger;
b : MyInteger;
};
view V as select from E {
// has type MyInteger
a,
// has type Integer, information about
// user defined type is lost
a+b as s1,
// has type MyInteger, explicitly specified
a+b as s2 : MyInteger
};
Defining Associations in Views
Another new features in SPS12, is associations in view definitions. In order to define an association as a view element, you need to define an ad-hoc association in the MIXIN section and then put this association into the select list. In the ON-condition of such an association you need to use the pseudo-identifier $PROJECTION to signal that the following element name is to be resolved in the select list of the view rather than in the entity in the FROM clause.
entity E {
a : Integer;
b : Integer;
};
entity F {
x : Integer;
y : Integer;
};
view VE as select from E mixin {
f : Association[1] to VF on f.vy = $projection.vb;
} into {
a as va,
b as vb,
f as vf
};
view VF as select from F {
x as vx,
y as vy
};
CDS Extensibility
The CDS extension mechanism, delivered with SPS12, allows adding properties to existing artifact definitions without modifying the original source files. The benefit is that a complete artifact definition can be split across several files with different lifecycles and code owners. The EXTEND statement changes the existing runtime object, it does not define any additional runtime object in the database. The extensibility feature uses the concept of extension packages. An extension package or simply package is a set of extend statements, normal artifact definitions (e.g. types which are used in an extend declaration), and extension relationships or dependencies. Each CDS source file belongs to exactly one package, i.e. all the definitions in this file contribute to that package. On the other hand, a package usually contains the contributions from several CDS source files. A package is defined by a special CDS source file named .package.hdbcds. The name of the package defined in the file must be identical to the namespace that is applicable for the file (as given by the relevant .hdinamespace file). With this new feature, we are able to extend several different aspects of a CDS file including; adding new elements to a structure type of entity, adding new select items to a view, adding new artifacts to an existing context, assigning further annotations to an artifact or element, and extending the technical configuration section of an existing entity.
Let's have a look at an excessively simplified CRM scenario below. The base application has a CDS file called "Address.hdbcds" which contains a Type called "Address", it also has another CDS file called "CRM.hdbcds" which uses the "Address.hdbcds" CDS file. Within the "CRM.hdbcds" file, we then have a context called "CRM" which contains an entity called “Customer” which has a column called “name” of type string and “address” of type "Address".

In this first extension package call “banking”, we extend the "CRM" context and add a new type called “BankingAccount”. We then extend the "Customer" entity and add a new element called “account” which uses the Type called “BankingAccount”, so we have a new column called "account.BIC" and "account.IBAN" added to the "Customer" table.
In the second extension, we further extend the "Customer" entity by extending the types which it uses. First we will extend the "Address" type from the original "Address.hdbcds" file, and then extend the "BankingAccount" type which was defined by the previous extension. So in this case the "onlineBanking" extension depends on the "banking" extension, hence the reason why we have the DEPENDS clause in the package definition.

The final result is that we have new columns in the "Customer" entity, "account.BIC" and "acocunt.IBAN", which were created by the "banking" extension, and "address.email" and "account.PIN", which were created by the "onlineBanking" extension.

SQLScript
SQLScript continues to be the stored procedure language used to take full advantage of the core capabilities of HANA such as massive parallel processing. Several new language features have been added in HANA 1.0 SPS12.
Global Session Variables
As of SPS12, we now have the concept of global session variables in SQLScript. Global session variables can be used to share scalar values between procedures and functions that are running in the same session. These are not visible from any other running session. We can use the SET statement to set a key/value pair in one procedure, and use the built in function called SESSION_CONTEXT to retrieve that value in a nested procedure or function call.
-- Set Session Variable Value
PROCEDURE CHANGE_SESSION_VAR (
IN NEW_VALUE NVARCHAR(50))
AS
BEGIN
SET 'MY_VAR' = :new_value;
CALL GET_VALUE( );
END
-- Retrieve Session Variable Value
PROCEDURE GET_VALUE ( )
AS
BEGIN
DECLARE VAR NVARCHAR(5000);
var = SESSION_CONTEXT('MY_VAR');
END;
Default empty for Table User Defined Functions
In SPS10, we introduced the ability to use the DEFAULT EMPTY extension when defining IN and OUT parameters of a procedure. This is useful for initializing a table parameter before its use within the procedure. As of SPS12, we now bring this same functionality to Table User Defined Functions as well.
FUNCTION myfunc IN intab TABLE(a INT) DEFAULT EMPTY)
RETURNS TABLE(a INT)
AS
BEGIN
RETURN SELECT * FROM :intab;
END;
SELECT * FROM myfunc();
Signatures for Anonymous Blocks
Anonymous Blocks were releases in SPS10, and allowed us to write SQLScript code in the SQL console without having to create a container, for example a procedure or function. This was a nice feature for creating quick and dirty test coding. The only problem was that it did not support input and output parameters. As of SPS12, we have added this feature. You can now define these parameters in the same way you would when defining parameters for a procedure. Both simple types and table types are supported as well as types defined via Core Data Services.
DO ( IN im_var INT => 5,
OUT ex_var INT => ?,
IN im_tab "dev602.data::MD.Employees" =>
"dev602.data::MD.Employees",
OUT ex_tab "dev602.data::MD.Employees" => ?)
BEGIN
ex_var := im_var;
ex_tab = select * from :im_tab;
END
Enhancements for Implicit SELECT in Nested Calls
With this new feature in SPS12, implicit results from nested procedure calls are carried to the outermost procedure’s result. You must first set a parameter value in the indexserver.ini configuration file. This changes the default behavior system wide.
alter system alter configuration ('indexserver.ini', 'system') set ('sqlscript', 'carry_nested_implicit_result') = 'true' with reconfigure;
Until SP11, the nested implicit result is not carried to the caller. Its lifecycle goes with the nested call's lifecycle. With this example, it is closed when the nested call statement("call proc2") is closed. From SP12, you can carry the nested implicit result with configuration change. When this configuration is on, the callee's implicit result sets are carried to the caller.
Enhancements for Header-Only Procedure and Functions
Header-only procedures and functions were first introduced in SPS10 and allowed developers to create procedures and functions with minimum metadata first using the HEADER ONLY extension. The body of the procedure and function could then be injected into the container later using the ALTER PROCEDURE or ALTER FUNCTION statement. This allowed procedures and functions to be created without having to worry about the interdependencies between the procedures and functions. As of SPS12, we now have the ability to call a HEADER ONLY procedure from within a trigger, as well as the ability to create a view on a HEADER ONLY Table User Defined Function.
- SAP Managed Tags:
- SAP HANA
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- Supporting Multiple API Gateways with SAP API Management – using Azure API Management as example in Technology Blogs by SAP
- Extend Your Crystal Reports Solutions in the DHTML Viewer With a Free Function Library in Technology Blogs by Members
- Customer & Partner Roundtable for SAP BTP ABAP Environment #12 in Technology Blogs by SAP
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- App to automatically configure a new ABAP Developer System in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |