これから3回にわたって「SAP HANA運用管理の基礎」というタイトルで連載します。初回は「永続化の仕組み」について説明します。そして、第2回「バックアップのメカニズム」、第3回「システムレプリケーションのメカニズム」と書いてここで一区切りとしたいと思います。セーブポイント、スナップショットを軸に永続化、バックアップ、システムレプリケーションの3つをまとめて効率的に理解します。
HANAの永続化の仕組み
データボリューム、ログボリューム
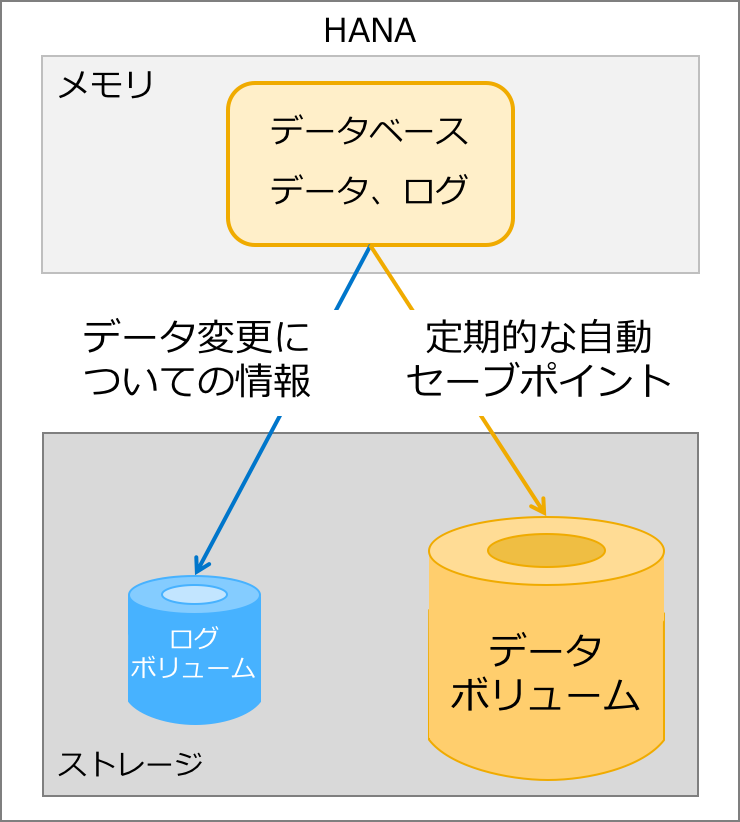
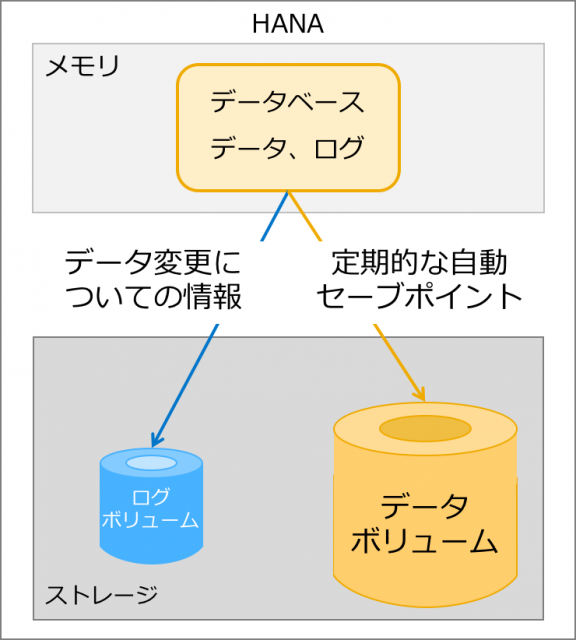
以下は、HANAの永続化の説明でよく使われる図なのですが、この図からわかることは、一般的なディスクベースのデータベースシステムと異なり、データベースの本体と永続化先(ここではデータボリュームとログボリューム)が異なるメディアに書かれる、ということです。HANAはメモリー上のデータベースを永続化のためにハードディスクに書く必要があることを示しています。
- 図1
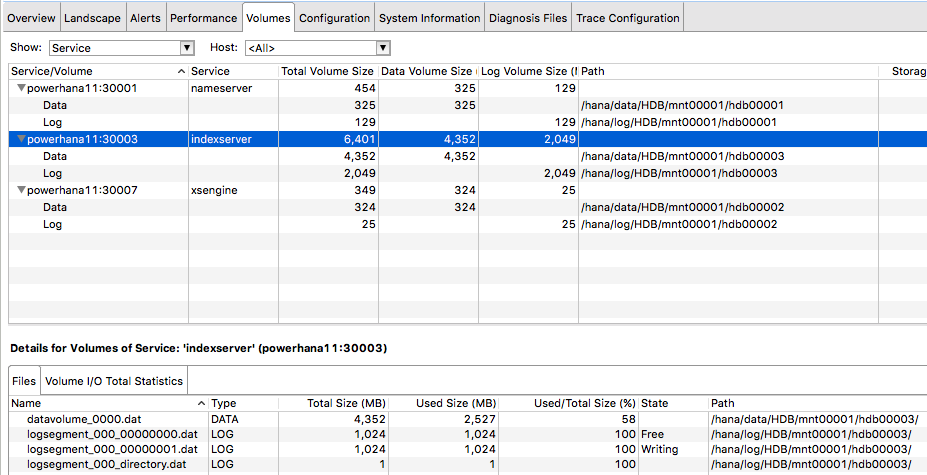
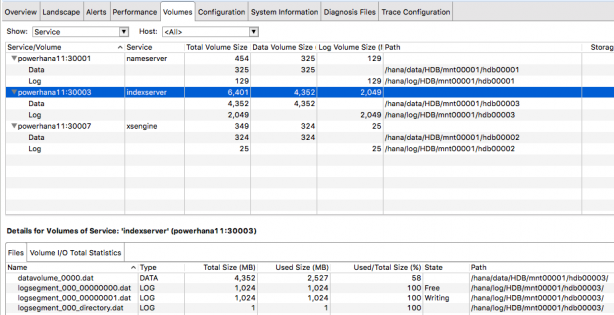
ちなみに、データボリューム、ログボリュームはHANA Studioでは以下のように確認できます。上半分は、nameserver、indexserver、xsengine(データベースを保持するサービス)について、データボリューム、ログボリュームの情報(サイズ、場所など)が表示されます。どれかをマウスで選択すると、下半分にファイルレベルの情報が表示されます。(なぜか、nameserverについては表示されません。)
- 図2
システムビューで同じ情報を確認する場合は、SYS.M_VOLUMES, SYS.M_DATA_VOLUMES, SYS.M_LOG_SEGMENTS あたりを参照することになります。
セーブポイントによる永続化
このため、HANAにはメモリー上のデータベースを永続化するための以下のような仕組みが必要になります。
セーブポイントは、データをデータボリュームに書き出す仕組みです。SAPの文書の中では、書き出すアクションだけでなく書き出したもの自体もセーブポイントと呼ぶようです。なのでくどい表現ですが、セーブポイントが起動されるとデータベースの内容がデータボリュームに書き出されセーブポイントが出来上がるということになります(図3)。
セーブポイントは常に1つで次回のセーブポイントで上書きされます。

- 図3
ログの書き出しは、変更内容(Redo log)をログボリュームに書き出す仕組みです。これは、commitが実行された時に加えて、ログのメモリ側の領域であるLog Bufferがフルになったときや、セーブポイントが実行されたとき、など複数のイベントをきっかけとして書き出されます。セーブポイントの実行間隔は設定で変更できますが、規定値では5分になっています。従って、メモリー上のデータベースは以下の2つから直近のデータベース状態をメモリー上に再現できることになります。
- セーブポイント
- 直近のセーブポイント以降に書かれたRedo log
実際、HANAインスタンスが起動するときには、まずセーブポイントの内容がメモリー上にロードされ、次にセーブポイント以降に書かれたRedo logが適用され(replay)直近の状態になります。(上記説明では、コミットされなかった変更を戻す作業(undo)が省略されています。undo logはセーブポイントの中に含まれています。詳しい説明は、別の機会に。)
セーブポイントは、以下のように明示的に実行することも可能です。Linux/Unixでのsyncコマンドみたいなものでしょうか。
ALTER SYSTEM SAVEPOINT;
システムビュー
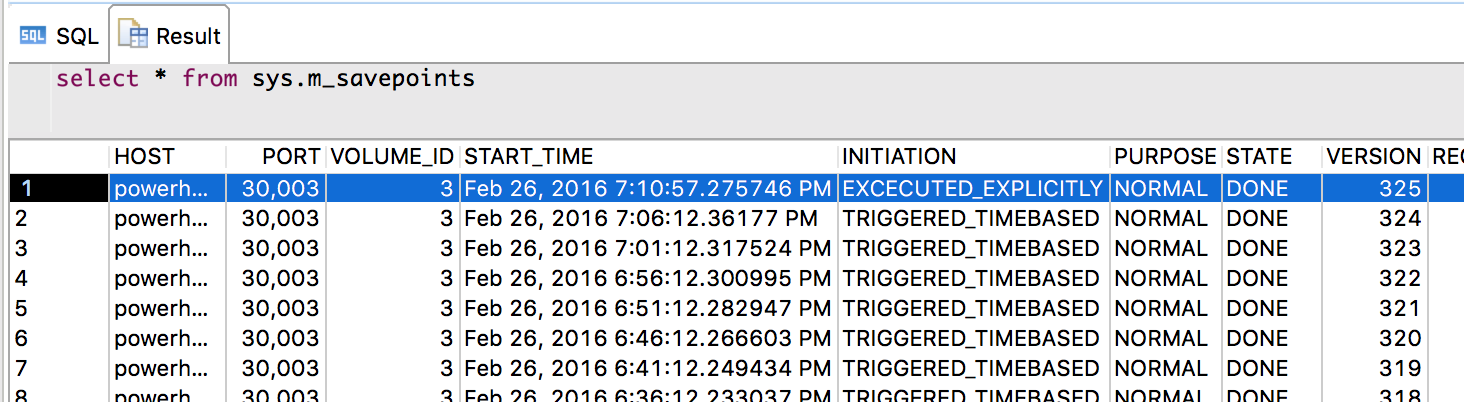
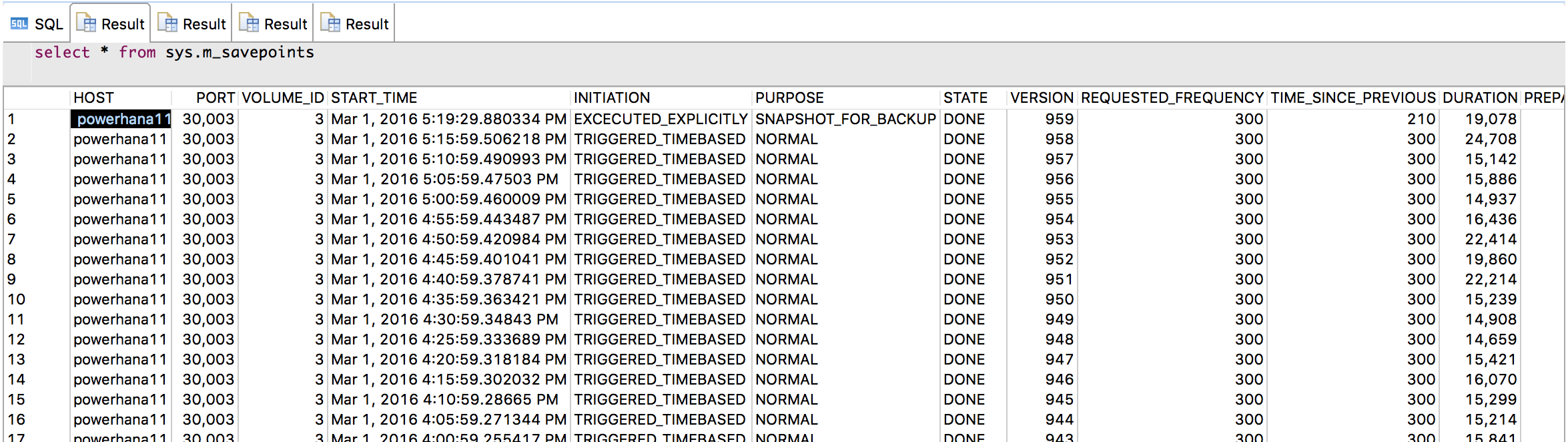
セーブポイントの実行状況を知りたい場合は、SYS.M_SAVEPOINTSを参照します。1行目はINITIATIONカラムが"EXECUTED EXPICITLY"となっているので、管理者が明示的に実行したか、バックアップなどにより起動されたかのどちらかであることを示します。”TRIGGERED_TIMEBASED”は5分ごとのタイマー起動であることを示します。
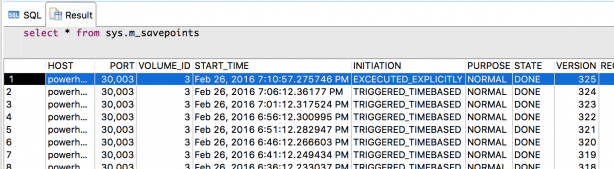
- 図4
セーブポイントの構造
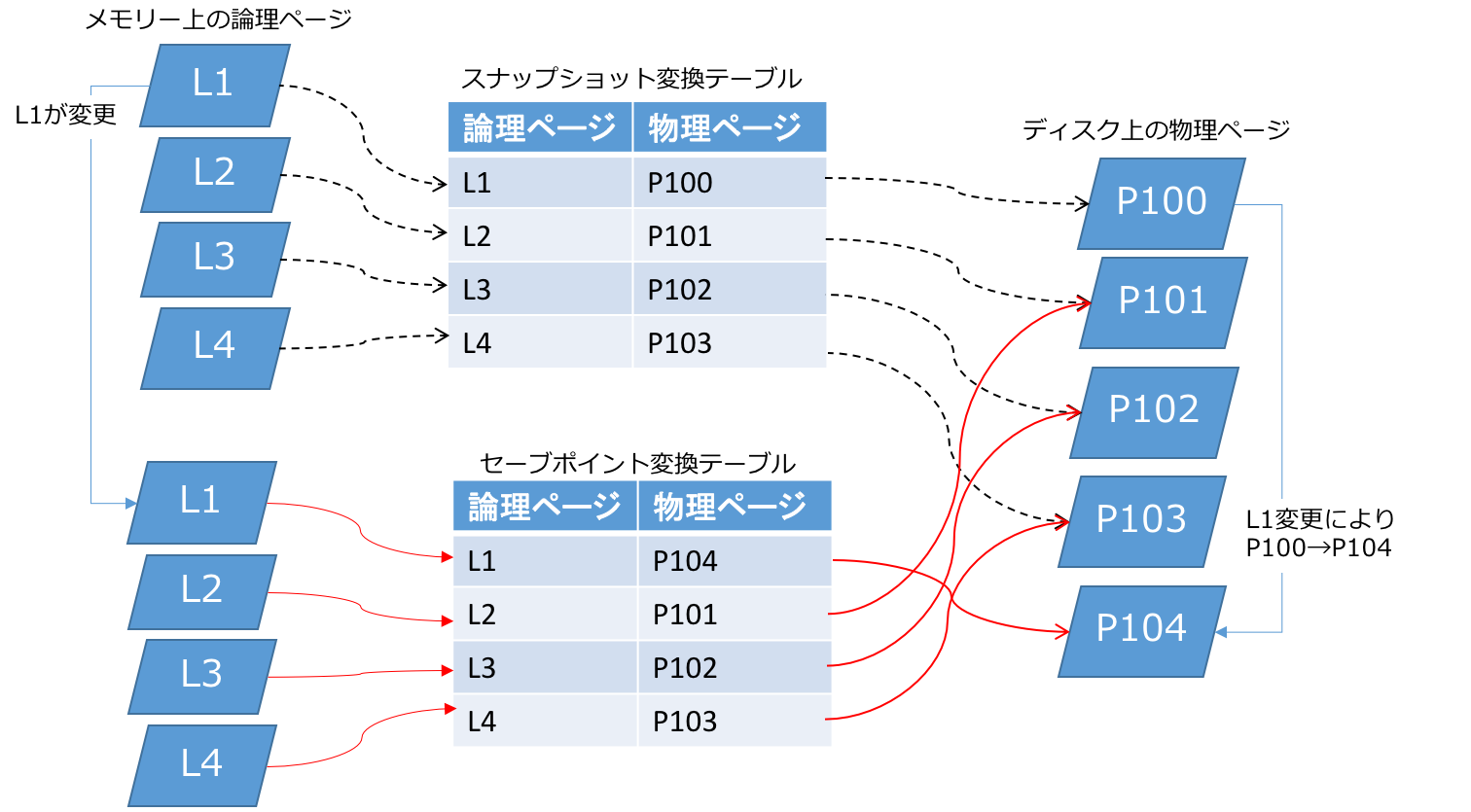
HANAのテーブルはページに分割されて管理され、ページ単位でディスクからメモリーに読み込まれたり(ロード)、メモリーからディスクに書かれたり(セーブポイント)します。このとき、ディスク上に存在するページを物理ページと呼び、メモリー上のデータベースを構成するページを論理ページと呼びます。(図5)
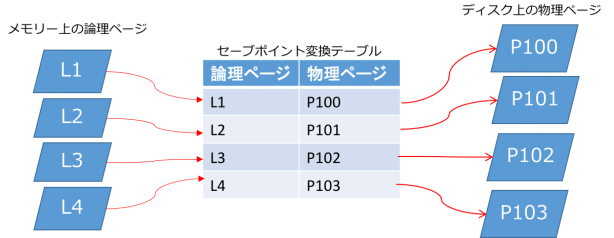
- 図5
HANAは仕様上、更新された論理ページに対応する物理ページを上書きせず、常に新しいページを割り当てます。従って、更新が発生すると新旧のページが混在した状態になりますが、変換テーブルによって、論理ページと物理ページの関係が決定されることになります。
つまり、セーブポイントの実体は、ディスク上の変換テーブル及びそのテーブルにぶらさがる物理ページ群、ということになります。
セーブポイントのこのような構造は、スナップショットによりある時点のデータベースの状態を保存したり、システムレプリケーションで更新差分を扱うための布石となっています。
スナップショット
何らかの理由でデータベースのある時点の状態を保存したい場合があります。セーブポイントは5分ごとに書き換えられるのでそういった用途には使えません。このような時にスナップショットが使われます。スナップショットは、保存可能な(つまり上書きされない)セーブポイントです。バックアップやシステムレプリケーションの際に暗黙的に作成されるか、ユーザーが明示的に作成します。
明示的なスナップショットの作り方は、以下の通り。
BACKUP DATA CREATE SNAPSHOT;
使い終わったら必ず削除しましょう。
BACKUP DATA DROP SNAPSHOT;
セーブポイントが直近の永続化されたデータベースイメージであり、常に上書きされるのに対してスナップショットはある時点のデータベースイメージで、複数作成することができ、上書きされることはありません。

- 図6
スナップショットの構造
概念的には図6のような理解でいいのですが、実際はスナップショットはセーブポイントの”丸ごとぶっこぬき”コピーではありません。丸ごとコピーは効率も悪いですし。実際には、スナップショットとセーブポイントは同じ構造で、こんな感じになっています。
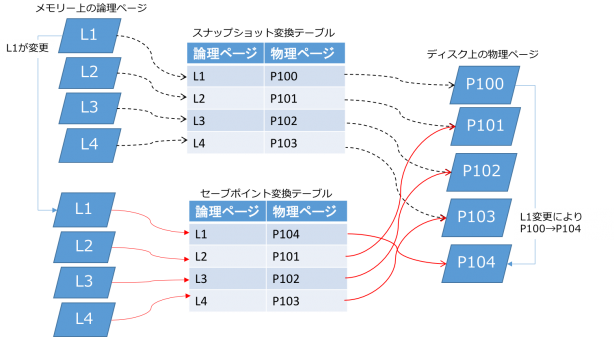
- 図7
- ある時点でスナップショットを作ると、図7の上半分に描かれたスナップショット用の変換テーブルが作成されます。このテーブルには物理テーブルP100,P101,P102,P103がぶら下がっています。
- 仮にここでL1が更新されたとします。5分以内に次のセーブポイントが走ります。この時、L1に対応するP103は更新されずに新しい物理ページP104が割り当てられます。
- 同時にセーブポイント用の変換テーブルが再作成されます。この時点でこのセーブポイントはスナップショットよりも1世代新しいことになります。
スナップショットが保存可能という意味は、スナップショットの変換テーブルにぶら下がった物理ページは削除されないということです。図7ではP103が該当します。スナップショットがもし作成されなければ、P103はすべてのトランザクションから参照されなくなった時点でガベージコレクトされて削除されますが、実際はスナップショットが存在する間、P103も存在し続けることになります。
システムビュー
スナップショットを作成した時のシステムビューを見てみます。
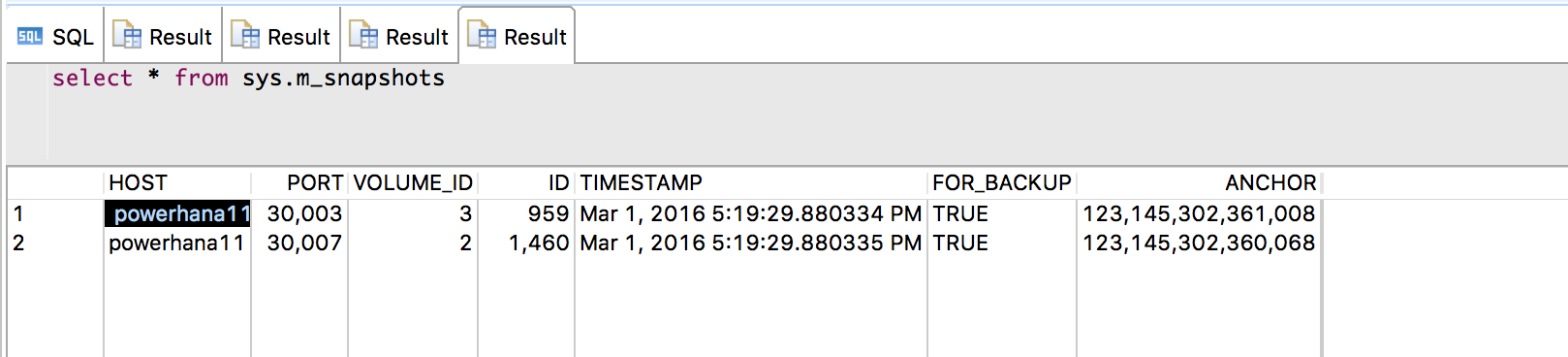
まず、先に説明したsys.m_savepointsです。スナップショットを作成するとm_savepointsにも記録されることから、セーブポイントによりスナップショットがつくられることがわかります。先頭が該当行です。
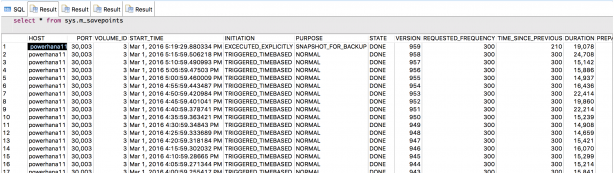
次は、sys.m_snapshotsです。
2行登録されているのは、サービスごと(indexserver, xsengine)に記録されているためです。
- 図9
スナップショットの簡単な実験
スナップショットがデータベースのある時点の状態を保存できることを示す簡単な実験です。
以下のSQL、コマンドを上から順に実行します。
最後のクエリー、結果はどうなるでしょうか?
- SYSTEMユーザーのSQLコンソールで以下を実行。
- BACKUP DATA CREATE SNAPSHOT;
- CREATE TABLE system.t1 ( c1 int);
- INSERT INTO t1 VALUES(1);
- SELECT * FROM system.t1;
- HANA管理者のLinuxコマンドプロンプトで以下を実行。
- HDB stop
- hdbnsutil -useSnapshot
- HDB start
- SYSTEMユーザーのSQLコンソールで以下を実行。
答えは、テーブルがみつからずにSQL文がエラーになる、です。順番に説明すると
- スナップショット作成
- テーブルt1を作成・データ登録
- シャットダウン
- hdbnsutil -useSnapshotでスナップショットを使用してブートするように設定
- ブート
- SQLを実行する
なので、SQLを実行した時には、データベースの状態はテーブルt1を作成する前の状態に戻っているわけです。’-useSnapshot’ の意味を説明していませんでしたが、勘のいい人は分かったと思います。
テストやラボで、使用後に環境を元に戻したい場合に便利ですので活用してください。
以上、HANAの永続化を理解する上で重要な機能であるセーブポイントとスナップショットについて説明しました。
今回は検証及びスクリーンショットの採取のために日本IBM社から環境をご提供いただきました。
- モデル:IBM Power S824
- CPU :24コア(3.52GHz)
- メモリー:2TB
- OS:SUSE Linux Enterprise Server 11 SP4
- SAP HANA:SPS11

次回はバックアップについて説明します。