When using SAP HANA for analytical purposes, it is interesting to have rates (interest, participation, benefit, etc) being computed by HANA, instead of BI tools, for performance reasons. It is very easy to use a calculation view to compute those rates.
Let's take an example the following calculation view, which is using one analytical view (called SALES) and one attribute view (called PRODUCT). There is a join in between the 2 views on PRODUCTKEY, and some objects have been added to output. I want to compute the benefit between the SALESAMOUNT and the TOTALPRODUCTCOST as a rate, the formula would be SALESAMOUNT/TOTALCOST*100 (to get a percentage) so I added the BENEFIT to the output of the JOIN; well this is a MISTAKE, let's see why!

When adding this calculated measure at the JOIN level, it will be aggregated as a SUM (or COUNT/MIN/MAX) which cannot apply to the aggregation of a rate:

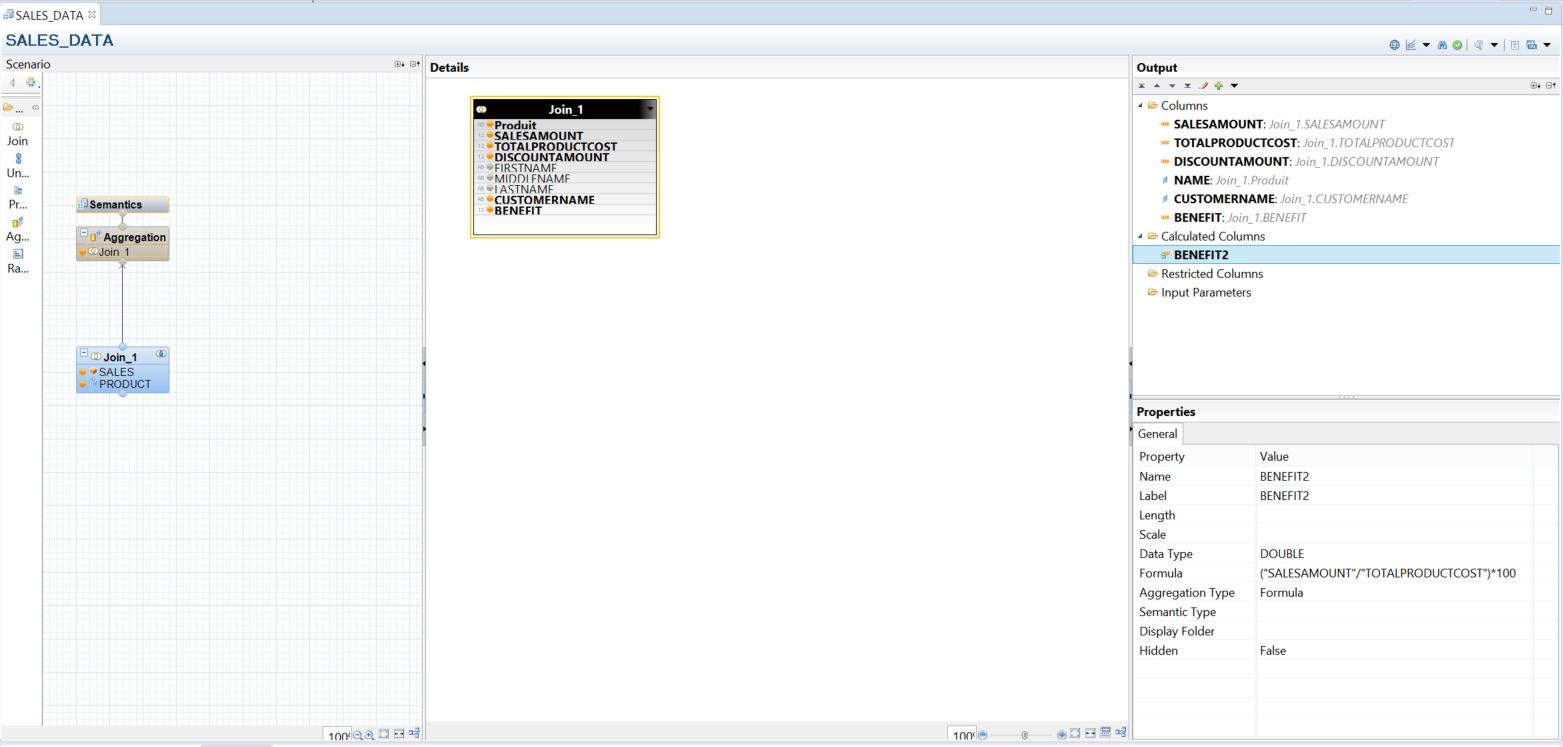
We have to add the calculated column at the AGGREGATION level as BENEFIT2 using the same formula, in order to make it work. As shown in the previous image, it will aggregate as "Formula" instead of "Sum", basically it will be computed after the aggregation of the object used inside the formula:
Let's see how this applies to a data set, I have added Customer Name and Product as dimensions, and SALESAMOUNT, TOTALPRODUCTCOST, BENEFIT and BENEFIT2 as measures. Both calculated columns work as expected as we have ALL the dimensions columns in the data preview, it means that there is no difference between the data at the JOIN level vs AGGREGATION level in our the calculation view:

But the error in Benefit shows up fast, as soon as I aggregate a smaller number of dimensions; let's use only the Customer Name as dimension column:

As you can see, BENEFIT shows up like a sum of rates which is not useful, where the BENEFIT2 shows a calculated rate on pre-aggregated values of the SALESAMOUNT and TOTALPRODUCTCOST for each customer.
