
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- HANA Smart Data Integration - The one stop solutio...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-11-2016
9:09 AM
In the data handling related market there is a pure Use-Case driven thinking. Customers requires to do data transformations? Provide an ETL tool. Customer requires the same data in another system? Provide a Replication tool. Customer requires access to the remote data? Provide Data Federation options in the database. Cloud Integration? Another product. Big Data? Yet another product. Data Quality? Data Preparation? The list goes on and on.
This Use-Case driven approach is way too limited. Just because the target is in the cloud, does that mean less sources, less transformation options are required? Certainly not. And the same can be said about any other combination.
The reason for the situation is partly historical and partly because no vendor has all the building blocks to provide a one stop solution for all - except SAP with Hana.
Playing Lego with Hana
Actually, thinking about it, all of the above use cases can be broken down into three types of components: Data Access - Data Transformation - Data Output. Each of the three types come in different flavors...
All use cases are now just combinations of these building blocks. With the main advantages that only one product - Hana - is to be used, only one connectivity is to be set up to each source, one central place for monitoring and administration, one UI to design the transformations. And as a consequence, the ability to move from one method to the other with a flip of a switch.
In order to provide better insight, imagine a user does make the following journey with Hana...
Setting up the connectivity to the source
For fun the remote system should be something different for a change, it shall be the CNN.com headlines provided via the RSS Adapter.
In the Adapter layer the user created a remote source using the RSS Adapter and pointing to the URL http://rss.cnn.com/rss/cnn_latest.rss.

This RSS Adapter provides a single remote table only, the RSSFEED table, with all recent headlines. In order to select data, this remote table was imported into the Hana catalog as virtual table, it was called V_RSSFEED.

Now Hana has all the required information to allow using CNN.com as data source and above Lego bricks can be combined.
Virtual table access (Smart Data Access)

 The data to be accessed is in a remote system and should be presented to the user. How these queries are executed does not matter. Could be the SQL console, a Business Intelligence tool, another application, BW,.... at the end it is all the same: A query like "select * from cnn_headlines" is executed in order to retrieve the data. (Note: The object cnn_headlines is a database view pointing to the virtual table as additional layer of abstraction.)
The data to be accessed is in a remote system and should be presented to the user. How these queries are executed does not matter. Could be the SQL console, a Business Intelligence tool, another application, BW,.... at the end it is all the same: A query like "select * from cnn_headlines" is executed in order to retrieve the data. (Note: The object cnn_headlines is a database view pointing to the virtual table as additional layer of abstraction.)

This functionality by itself is unique in the database market already. Other database vendors allow Data Federation for database sources only and certainly do not allow adding adapters created by somebody else.
According to marketing this Smart Data Access functionality is the preferred method for Hana, as the remote data is realtime by definition - the data is retrieved whenever the query is executed - and no data duplication. Fine.
But a few problems with Data Federation become obvious here already.
If one of above reasons suggest it would be better to copy the data into Hana instead, it calls for a batch data movement use case.
Batch data movement


Here the task is quite simple, pull the data from the source, transform it into the target table schema and load all rows into the target table. Using the FlowGraph UI it is a matter of seconds dragging in the virtual table as source and connecting it to a new Hana column table as target table.

For the user nothing changed. He still does execute the same query "select * from cnn_headlines" as before but now this database view points to the loaded T_CNN_HEADLINES table in Hana. Hence the query is executed with Hana performance, has all the history and the source system is relieved from the additional resource consumption. Except that this dataflow has to be executed tomorrow again to get the changes.
In today's world that would need to be executed more frequently. Every hour? Every 10 minutes? Every second? The desire is to bring the latency down to a sub second level, meaning executing the dataflow that often. At some frequency it does not make sense anymore since one reason for copying the data was to reduce the load on the source system by redirecting the user queries into a Hana table. Yet the source system is queried for changes more frequently than users would have? Does most definitely make no sense.
The key problem is the pull-mechanism. The batch job has to run just because there might(!) be new data. Would be much better if the source does send the changed data by itself - a push mode.
Realtime Data Movement


In the push mode the adapter does whatever is required to be informed about changes in the source. For database adapters that is done by following the transaction log. Internet sources often provide a streaming protocol. ...whatever make sense. The RSS protocol is too trivial, it provides neither of these options but at least the http protocol header can be used to figure out quickly if there was a change or not.
The other consequence of the push method is that the source can tell the type of change for each row, e.g. in case a row has been deleted in the source. Therefore the dataflow has to deal with those deleted records somehow. Again, implementing that as a batch pull logic, this can get very difficult as each source is different. The user has to design a flow that handles deleted rows. Likely in addition to the one dealing with insert/updates. Another one if the second source table got changed. Another..... It gets ugly quickly. In Hana all the differences are handled by the adapter and hence the FlowGraph editor got the logic to turn (almost) every dataflow into a realtime push transformation.
As a result, turning the above batch dataflow into a realtime push version is as simple as opening the properties of the source table and selecting "realtime".

Internally such realtime enable FlowGraph is turned into two runtime objects actually. First an batch dataflow performing the initial load of the target table. And a second dataflow with a parameter of datatype TableType as input, which is called with all changed rows.
CalcView like transformations
The idea of the CalcView in Hana is to read the data, transform it and show the results whenever the user queries such view. Isn't that just another combination? Pulling the data, performing the transformations and presenting the data to the end user. With the main difference, in this editor all Hana Transformations can be used: Data Quality, Predictive, Statistic,....

Service call

As a FlowGraph supports passing parameters, this can be used to design data transformation services. Something that looks and feels like a procedure with input and out parameters and does complex transformations inbetween. With that it is possible to utilize all the transformations Hana provides in other applications. Thanks to the simple to use FlowGraph editor even end users can make modifications to these dataflows.
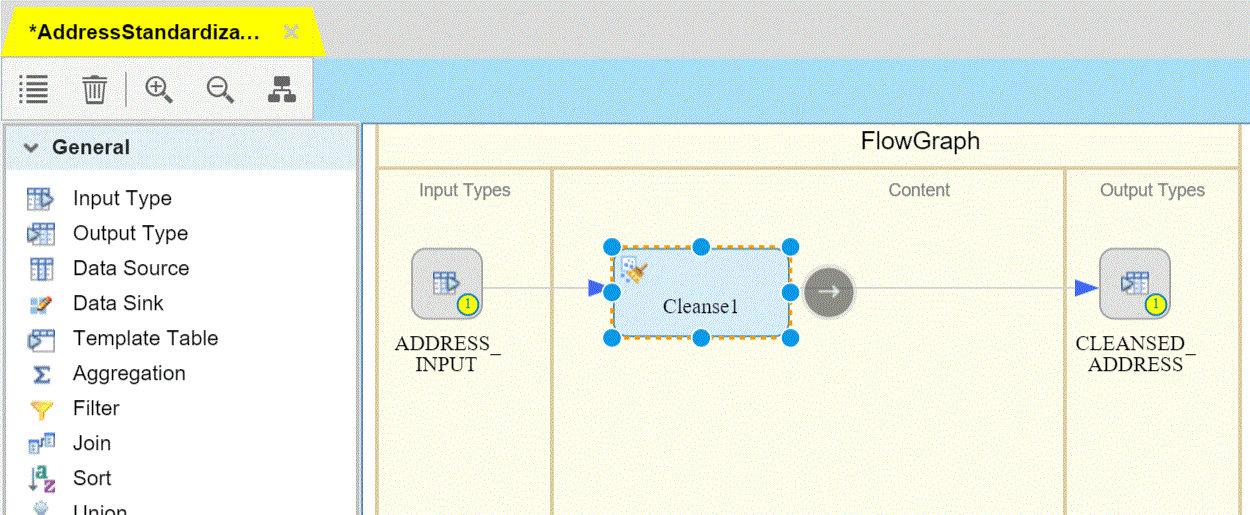
A step by step guide for this example can be found in SCN.
Plus more
By mixing and matching these 3 x 2 x 3 components the user gets much more than a few supported use cases. All use cases are supported and the best of it, the user does not have to decide upfront. For some cases the virtual table method is the perfect solution, for others the realtime data movement. In some cases the transformation has to be flexible, in others it is better to convert the data model of the source into something that is better suited for querying. The end user does not care, he does not even see the difference - all he does is "select * from cnn_headlines".
This Use-Case driven approach is way too limited. Just because the target is in the cloud, does that mean less sources, less transformation options are required? Certainly not. And the same can be said about any other combination.
The reason for the situation is partly historical and partly because no vendor has all the building blocks to provide a one stop solution for all - except SAP with Hana.
Playing Lego with Hana
Actually, thinking about it, all of the above use cases can be broken down into three types of components: Data Access - Data Transformation - Data Output. Each of the three types come in different flavors...
- Data Access
- Pull data on request: When an batch job starts or the user executes a query, pull the data.
- Push changed data: Whenever there is a change in the source, push the change.
- Pass the data: Provide the data as input parameter.

- Pull data on request: When an batch job starts or the user executes a query, pull the data.
- Transformations
- Transform the read data
- Transform the incoming change-data

- Transform the read data
- Data Output
- Load the target
- Show the data
- Return the data as output parameter
- Load the target
All use cases are now just combinations of these building blocks. With the main advantages that only one product - Hana - is to be used, only one connectivity is to be set up to each source, one central place for monitoring and administration, one UI to design the transformations. And as a consequence, the ability to move from one method to the other with a flip of a switch.
In order to provide better insight, imagine a user does make the following journey with Hana...
Setting up the connectivity to the source
For fun the remote system should be something different for a change, it shall be the CNN.com headlines provided via the RSS Adapter.
In the Adapter layer the user created a remote source using the RSS Adapter and pointing to the URL http://rss.cnn.com/rss/cnn_latest.rss.
This RSS Adapter provides a single remote table only, the RSSFEED table, with all recent headlines. In order to select data, this remote table was imported into the Hana catalog as virtual table, it was called V_RSSFEED.
Now Hana has all the required information to allow using CNN.com as data source and above Lego bricks can be combined.
Virtual table access (Smart Data Access)
This functionality by itself is unique in the database market already. Other database vendors allow Data Federation for database sources only and certainly do not allow adding adapters created by somebody else.
According to marketing this Smart Data Access functionality is the preferred method for Hana, as the remote data is realtime by definition - the data is retrieved whenever the query is executed - and no data duplication. Fine.
But a few problems with Data Federation become obvious here already.
- The query speed is the speed of the source system. Might be sufficient, might not be.
- The source system does delete old data. Granted, via the RSS internet protocol the 100 most recent headlines are provided only. That's kind of an extreme case of not providing much history but it is the same with operational systems as well often.
- The source system gets pounded by queries constantly.
If one of above reasons suggest it would be better to copy the data into Hana instead, it calls for a batch data movement use case.
Batch data movement
Here the task is quite simple, pull the data from the source, transform it into the target table schema and load all rows into the target table. Using the FlowGraph UI it is a matter of seconds dragging in the virtual table as source and connecting it to a new Hana column table as target table.
For the user nothing changed. He still does execute the same query "select * from cnn_headlines" as before but now this database view points to the loaded T_CNN_HEADLINES table in Hana. Hence the query is executed with Hana performance, has all the history and the source system is relieved from the additional resource consumption. Except that this dataflow has to be executed tomorrow again to get the changes.
In today's world that would need to be executed more frequently. Every hour? Every 10 minutes? Every second? The desire is to bring the latency down to a sub second level, meaning executing the dataflow that often. At some frequency it does not make sense anymore since one reason for copying the data was to reduce the load on the source system by redirecting the user queries into a Hana table. Yet the source system is queried for changes more frequently than users would have? Does most definitely make no sense.
The key problem is the pull-mechanism. The batch job has to run just because there might(!) be new data. Would be much better if the source does send the changed data by itself - a push mode.
Realtime Data Movement

In the push mode the adapter does whatever is required to be informed about changes in the source. For database adapters that is done by following the transaction log. Internet sources often provide a streaming protocol. ...whatever make sense. The RSS protocol is too trivial, it provides neither of these options but at least the http protocol header can be used to figure out quickly if there was a change or not.
The other consequence of the push method is that the source can tell the type of change for each row, e.g. in case a row has been deleted in the source. Therefore the dataflow has to deal with those deleted records somehow. Again, implementing that as a batch pull logic, this can get very difficult as each source is different. The user has to design a flow that handles deleted rows. Likely in addition to the one dealing with insert/updates. Another one if the second source table got changed. Another..... It gets ugly quickly. In Hana all the differences are handled by the adapter and hence the FlowGraph editor got the logic to turn (almost) every dataflow into a realtime push transformation.
As a result, turning the above batch dataflow into a realtime push version is as simple as opening the properties of the source table and selecting "realtime".
Internally such realtime enable FlowGraph is turned into two runtime objects actually. First an batch dataflow performing the initial load of the target table. And a second dataflow with a parameter of datatype TableType as input, which is called with all changed rows.
CalcView like transformations
The idea of the CalcView in Hana is to read the data, transform it and show the results whenever the user queries such view. Isn't that just another combination? Pulling the data, performing the transformations and presenting the data to the end user. With the main difference, in this editor all Hana Transformations can be used: Data Quality, Predictive, Statistic,....
Service call
As a FlowGraph supports passing parameters, this can be used to design data transformation services. Something that looks and feels like a procedure with input and out parameters and does complex transformations inbetween. With that it is possible to utilize all the transformations Hana provides in other applications. Thanks to the simple to use FlowGraph editor even end users can make modifications to these dataflows.
A step by step guide for this example can be found in SCN.
Plus more
By mixing and matching these 3 x 2 x 3 components the user gets much more than a few supported use cases. All use cases are supported and the best of it, the user does not have to decide upfront. For some cases the virtual table method is the perfect solution, for others the realtime data movement. In some cases the transformation has to be flexible, in others it is better to convert the data model of the source into something that is better suited for querying. The end user does not care, he does not even see the difference - all he does is "select * from cnn_headlines".
- SAP Managed Tags:
- SAP Datasphere,
- SAP HANA,
- SAP HANA smart data integration
Labels:
10 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- SAP Partners unleash Business AI potential at global Hack2Build in Technology Blogs by SAP
- Convert multiple xml's into single Xlsx(MS Excel) using groovy script in Technology Blogs by Members
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |