
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Increasing the SAP-NLS Performance
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
RolandKramer
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-17-2015
3:29 PM
last update: 2nd of October 2022
Increasing the SAP-NLS Performance

Blog Content
- SAP Corrections
- SAP IQ DB Settings
- SAP HANA DB Settings
- optimize NLS for SDA
- improve NLS load
- optimizing F4 access
- optimizing Query access
With the Introduction of smart data access (SDA) especially between SAP HANA and IQ, the data provisioning process can be optimized. Never the less, some additional Parameters have to be introduced on the ABAP and HANA Backend as well.
The Implementation of the SDA between SAP HANA and IQ is already discussed in the -
SAP First Guidance - SAP-NLS Solution with SAP IQ This would be a mandatory task first.
for General Information about the SAP-NLS Solution please visit - SAP-NLS Solution for SAP BW
Recommended SAP Corrections (SAP BW 7.40/7.50/BW/4)
| Version | SP-Level | Current SP (05/2022) | Support |
| SAP BW 7.40 | 26 | SAPKW74026 | until End of 2020 |
| SAP BW 7.50 | 24 | SAPK-75022INSAPBW | until End of 2027 |
| SAP BW/4 1.0 | 20 | SAPK-10020INDW4CORE | until End of 2021 |
| SAP BW/4 2.0 | 12 | SAPK-20010INDW4CORE | until End of 2024 |
| SAP BW/4 2021 | 02 | SAPK-30001INDW4CORE | commitment until 2040 |
| Components | Category | ||
| BW-WHM-DST-ARC | BW/4 only | BW4-DM-DTO | Program Error |
| BW-SYS-DB-IQ | optional | BW-WHM-DST-DTP | Search Term |
| BC-SYB-IQ | optional | BW-WHM-DBA-ADSO | archive, near-line, IQ |
You can use the SAP Launchpad - https://launchpad.support.sap.com/#/mynotes?tab=Search
to select the necessary SAP Notes for your SAP System and SP Level:

General Performance Optimizations in SAP NLS (BW ABAP)
As a general reference please consider the following knowledge base article on SAP NLS IQ performance:
Performance in writing Archives - see also NLS load parallelization
Note 2109015 - Continuation of Archiving Requests for Copy, Verification, and Deletion Phase in para...
Note 2371160 - FAQ: BW archiving to SAP IQ performance considerations
Note 2525213 - NLS archiving performance with SAPIQDB_DIAG.log showing batch insert entries

settings for SAP IQ for SAP-NLS
Check the SAP IQ database settings (based on SAP IQ 16.1 SP04 and higher)
Note 3017355 – SAP IQ 16.1 SP04 PLx – correct SAPIQDB.cfg settings
Note 3119008 – Configure SAP IQ and HANA for SDA/ODBC
Note 2767466 - Options to control client connection timeout in SAP IQ
- SQL Anywhere Server 17.0 - DB start options
- IQ PAGE SIZE Parameter Guidelines
- Catalog Page Size Option
- IQ Performance Options - on DB start
- additional settings for the SQL anywhere interface:
- -gss: This parameter sets the catalog (Sql Anywhere) stack size for catalog threads. For all 64-bit UNIX platforms: Default=Min = 1 MB. Max = 8MB. Considering some large or complex queries ,please set this value to 8MB
- -iqtss: Specifies the stack size, in KB, for server execution threads running either in the background or as part of a thread team assisting the main server connection thread. The default value is 512KB on 64-bit platforms. However, some very complex queries may return an error indicating that the depth of the stack exceeded this limit, so you may need increase this value to 2048.
- SAP IQ calculates the stack size of server threads using the formula: ( -gss + -iqtss)
- -iqmc: Specifies main buffer cache size in MB, you may set this value to 8192.
Finally, please consider the following SAP Note for introducing a new dbspace-oriented partitioning mode for SAP NLS IQ for optimized partition creation during archiving from BW
Note 2190504 - BW NLS IQ: New dbspace-oriented partitioning mode
If the SAP/Sybase IQ automated Installation routine is used, then these settings are automatically calculated, see - Q – the easy Installer for SAP Sybase IQ
Blog - Tuning SAP IQ NLS in SAP BW on HANA and BW/4HANA
settings for SAP HANA together with NLS
Currently the following SDA parameters should/could be changed on the SAP HANA server:
- remote_objects_tree_max_size
- remote_conn_idle_timeout
- semi_join_execution_strategies
- semi_join_virtual_table_threshold
- virtual_table_format
- join_relocation
- fda_enabled
- enable_remote_cache
- enable_remote_source_capability
- default_connections_pool_max_size

In Addition you can also set the remote connection timeout in the HANA Studio with the SQL interface:
Note 2578523 - SAP HANA Smart Data Access - exceeded simultaneous SESSIONS_PER_USER limit
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'system') set ('smart_data_access', 'remote_conn_idle_timeout') = '180' with reconfigure;Note 2184030 - SAP HANA Smart Data Access: How to Increase the Number of Objects Displayed
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'system') SET ('smart_data_access', 'remote_objects_tree_max_size') = '5000' WITH RECONFIGURE;With HANA (all Versions), you should also set the DML Mode to "readonly" in the remote DS:


Currently the following parameters should be changed on the SAP ABAP server:
- rsdb/supports_fda_prot = 0
- rsdb/max_blocking_factor = 50
- rsdb/max_in_blocking_factor = 100 (as of SAP Kernel 7.49, previously 1024)
- rsdb/prefer_join = 0
- rsdb/prefer_union_all = 0
- rsdb/prefer_in_itab_opt = 1
- rsdb/prefer_join_with_fda = 1 (as of SAP Kernel 7.43)
Note 1987132 - SAP HANA: Parameter setting for SELECT FOR ALL ENTRIES
optimize the SAP-NLS Solution for SDA with SAP HANA

Note 2130587 - SYB IQ: performance enhancement for LOAD statement (latest ASE/IQ LibDBSL)
Note 2352696 - SAP HANA smart data access 2.0 (latest ODBC drivers for SAP HANA)
Note 2445973 - SAP_IQNC 16.1 SP01 (Build 10531) Release Notes Information (latest ODBC drivers for SAP IQ)
With the Introduction of SAP HANA Smart Data Access (SDA), the data access to archived data can be generally optimized. For general information on how BW on HANA use HANA Smart Data Access please see the following Blog - SAP BW on HANA smart data access
Please note that especially selections on navigational attributes are considered with the automatic usage of semi-joins or joint relocation's for the execution of queries based on SDA together with HANA and IQ.
For more details see - SAP BW on HANA & HANA Smart Data Access - BEx Query Execution and
Note 2156717 - NLS: queries with navigation attributes/hierarchy node restrictions are slow
In addition, the following specific SAP Notes for Nearline Storage and Smart Data Access apply:
Note 2100962 - FAQ: BW Near-Line Storage with HANA Smart Data Access: Query Performance
Note 2165650 - FAQ: BW-Nearline-Storage with SAP HANA Smart Data Access
Note 2214892 - BW HANA SDA: Process Type for creating Statistics for Virtual Tables
Note 2202052 - BW Near-Line Storage with HANA Smart Data Access: Poor Query Performance with InfoCub...
Note 2283055 - External SAP HANA view: object specific enforce SQL engine execution
The Reports RSDDB_INDEX_CREATE_MASS / RSDDB_LOGINDEX_CREATE
Note 2194638 - Report RSDDB_INDEX_CREATE_MASS: regenerate indices if invalid, independent of 'skip_i...
Note 2379817 - DataStore Objects (advanced) with Near-Line Storage: Error during Extraction
Note 2607883 - Checking Column view and calculation scenario/ calculation model errors in BW Queries


The Report RSDA_DROP_TEMP_TABLES

Note 2708894 - Clean-up report for temporary lookup tables from IQ
Note 2198386 - BW HANA SDA: Performance Improvement for Creation of Database Statistics for Virtual ...
Note 2288710 - BW HANA SDA: Create Database Statistics for Virtual Tables of Open ODS Views
Note 2431673 - RSSDA_CREATE_TABLE_STAT shows error: statistics cannot be found
The Report RSSDA_CREATE_TABLE_STAT
can be used to create database statistics for HANA Virtual Tables.
Note 1990181 - BW HANA SDA: Create Database Statistics for Virtual Tables of Open ODS Views and Near...
HANA Virtual Tables are used in the context of HANA Smart Data Access. The execution time can be quite time consuming. As of HANA SP10, a new statistics type RECORD COUNT is available for virtual tables via a system view named SYS.DATA_STATISTICS.
This View offers for Example CREATE_TIME und LAST_REFRESH_TIME as columns.
- HANA - DATA_STATISTICS System View provides db statistics for virtual tables.
- HANA - M_JOIN_DATA_STATISTICS System View provides engine join db statistics.
- HANA - M_CS_TABLES System View provides runtime data for column tables.
- SAP Help - Statistical Analyses of the Data Warehouse Infrastructure


improve nearline storage (NLS) load
Note 2128579 - Data Load into SAP IQ during Copy Phase utilizes only one server-side Thread
Note 2364354 - SIQ: Support for aDSO and load striping
Note 2399003 - SIQ: Load fails with error: DBSQL_DUPLICATE_KEY_ERROR
Note 2420571 - SIQ: enhance performance of bulk updates and deletes
Note 2520897 - ODP package size and data load performance
Note 2902060 - Why the temp files created by DBSL to handle data loads from DTO into IQ are excessiv...
Note 2941940 - Troubleshooting SAP API performance issues (Data Packages, Work Processes, RFC Connec...
With SAP Note 2128579 two additional parameters were introduced to significantly increase the LOAD statement for writing data into SAP-NLS.
Parameter LOAD_STRIPE_SIZE setting this parameter to a value n > 1 parallelizes the load.
Parameter LOAD_STRIPE_WITH is the parallel degree multiplied with SYBASE_IQ_BUFFER_SIZE
Parameter SYBASE_IQ_LOAD_DIR could be changed at the database connection level (DBCO) and is by default the data directory of the SAP Instance. If you plan to load a large amount of data, please make sure that you have enough space left, or specify another directory/device.
Please make sure, that there is enough space on the underlying file system to hold all the data of at least 1 Data Package per concurrently running Data Archiving Process.
As a rule of thumb the reserved space should be 1.5 times the maximum number of concurrently running copy phases times the average size of a Data Package (the maximum Data Package size can be configured within the Data Archiving Process; its system default is 2000 MB)
The LOAD_STRIPE_WITH can be increased up to the amount of physical CPU’s are available on the IQ server depending on the other server resources like file system, RAM, etc.
If you plan to unload several large objects at the same time, the value should be calculated accordantly and must not be higher than the available physical CPU’s.
LOAD_STRIPE_SIZE=4; LOAD_STRIPE_WIDTH=4


Optimizing F4 Help access for SAP-NLS
It is suitable to change the settings for the affected Dimension tables to a more optimized setting. This can be done via the “Provider-Specific” settings for the Dimensions within the InfoCube. By default these options are empty, which means the default settings of the individual InfoObjects for query definition and execution are take place.
Furthermore any reorganization of the dimension tables e.g. via transaction RSRV should be avoided, due to no benefit at all for the application rather to corrupt the F4 access to the SAP-NLS solution and this will result in wrong F4 values and much less performance.
As an example see the following screens for an optimized setting. For further information, please consult the help.sap.com pages.

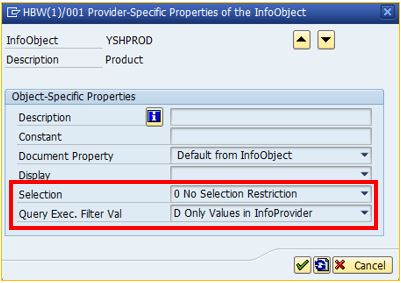
Optimizing Query access for SAP-NLS
Note 2001947 - Switch for operations in SAP HANA
Note 2099102 - SFAE implementation of LOOKUP has poor performance
Note 2129546 - Extended pruning on time characteristics for Near-line data
Note 2156717 - NLS: queries with navigation attributes/hierarchy node restrictions are slow
Wiki - Improving BW Query Performance by Pruning
Queries on InfoCubes show poor performance since filter conditions are pushed as "SID-based" filters to the HANA database instead of using the "key-values" for filtering. With "SID-based" filters, the SID-table needs to be joined to the Virtual Table in order to execute the filter. This join adds complexity to the SQL-Statement which makes it more difficult to optimize the query in a federated database environment.
Note 2231332 - Control of Query Optimization on Near-line Storage on InfoProvider Level
This note adds a checkbox to the "Near-line Storage" tab of the Data Archiving Process (DAP) maintenance to switch query optimization on (this is the default) or off. You must activate the DAP in order to make your setting effective. If optimization is switched on, but query optimization is not configured or not available for the Near-line Connection query access will use the non-optimized implementation via the Virtual Provider interface utilizing the Near-line Provider implementation via the standard Near-line Interface. In case Smart Data Access is configured for the Near-line Connection also the name of the HANA Virtual Table is shown.


Roland Kramer, SAP Platform Architect for Intelligent Data & Analytics
@RolandKramer
“I have no special talent, I am only passionately curious.”
- SAP Managed Tags:
- BW (SAP Business Warehouse),
- SAP BW/4HANA,
- SAP HANA,
- SAP IQ,
- BW SAP HANA Data Warehousing,
- NW ABAP Data Archiving
Labels:
14 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
297 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
343 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- SAP Analytics Cloud - Performance statistics and zero records in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- What are the use cases of SAP Datasphere over SAP BW4/HANA in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |