
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Creating a Rugby World Cup Sentiment Tracker
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-23-2015
4:35 PM
With the Rugby World Cup now on, I decided to put some of the SAP kit bag to the test.
25-Sept-2015, We have updated Lumira Cloud visualisations and added a few more screenshots below
The latest output of this *should* be automatically republished daily at 22:00 BST to Lumira Cloud, allowing you to interact with it.

During the first 7 days of the tournament I have already captured over 1.4 million tweets from the #RWC2015 Twitter Feed. I hope to keep the data capture running throughout the tournament
In this example I have used
1. Smart Data Integration (SDI) within SAP HANA to acquire the tweets from Twitter in real time from the #RWC2015 feed
2. SAP HANA to store, process and the data
3. Text Analysis to turn Tweets into a structured form
4. Text Mining to identify Relevant Terms
5. SAP HANA Studio to model
6. SAP Lumira Desktop to create some analytics
7. SAP Lumira Cloud to expose the output
1. Data Acquisition through the SDI Data Provisioning Agent
From HANA SPS 09 Smart Data Integration has been added directly in HANA. One of the data provisioning (DP) sources available is a Twitter. I won't repeat the steps to setup the DP agent here, as Bob has created a great series of SAP HANA Academy videos of this setup here.
SAP HANA Academy - Smart Data Integration/Quality : Twitter Replication Pt 1 of 3 [SPS09] - YouTube
With the virtual table now available in HANA you can make this real-time by issuing the following SQL.
SET SCHEMA HANA_EIM;
--Create SDA Virtual Table
CREATE VIRTUAL TABLE "HANA_EIM"."RWC_R_STATUS" at
"TWITTER"."<NULL>"."<NULL>"."status";
--Create a target table
create COLUMN table "HANA_EIM"."RWC_T_STATUS" like "HANA_EIM"."RWC_R_STATUS";
--Create Subscriptions
create remote subscription "HANA_EIM"."rt_trig1"
as (select * from "HANA_EIM"."RWC_R_STATUS" where "Tweet" like '%#RWC2015%')
target table "HANA_EIM"."RWC_T_STATUS";
--SELECT * FROM "HANA_EIM"."RWC_T_STATUS";
--truncate table "HANA_EIM"."RWC_T_STATUS";
--Queue the subscription and start streaming.
alter remote subscription "HANA_EIM"."rt_trig1" queue;
alter remote subscription "HANA_EIM"."rt_trig1" distribute;
select count(*) from "HANA_EIM"."RWC_T_STATUS";
--Stop Subscription
--ALTER REMOTE SUBSCRIPTION "rt_trig1" RESET;
This table holds the raw Tweets coming in from twitter

Twitter provide a number of columns, the Tweet itself is the most useful of these for this analysis.

With the data now being acquired "automatically" it's possible to monitor the acquisition via the XS Monitoring URL http://ukhana.mo.sap.corp:8000/sap/hana/im/dp/monitor/?view=DPSubscriptionMonitor

3. Text Analysis
As I previously described Using Custom Dictionaries with Text Analysis in HANA SPS9, for Formula One Twitter Analysis creating custom dictionaries for your subject area is very easy.
I've added one to include the Rugby teams, Twitter handle and short name. This new dictionary was included in a new configuration.

To turn on Text Analysis on the acquired twitter data, use the following syntax
CREATE FULLTEXT INDEX "RWC-TWEETS" ON "HANA_EIM"."RWC_T_STATUS"("Tweet")
CONFIGURATION 'RWC::RUGBY_SOCIAL_CONFIG'
FAST PREPROCESS OFF
LANGUAGE COLUMN "isoLanguageCode"
LANGUAGE DETECTION ('EN','FR','DE','ES','ZH','IT')
TEXT ANALYSIS ON
TEXT MINING ON
FUZZY SEARCH INDEX ON
Text Analysis is really clever and identifies some useful elements, beyond the basics. Who, Where, When, etc. The more advanced output is often known as fact extraction, of these "facts" Sentiment, Emotion and Requests are three of these that could potentially be useful in the Rugby Tweet data.
4. Text Mining the Tweets
Now I wanted to try something more than just sentiment, mentions and emotion. For this I decided to use Text Mining which is also built into HANA, and has been further enhanced is SPS10 with SQL access to Text Mining functions. Activating Text Mining is very easy, it's done when when specifying the FULL TEXT index by using the syntax as above TEXT MINING ON.
Text Mining has multiple capabilities which are applicable at a document level, for this I treated each Tweet as a document which served a purpose. As tweets by nature are very short you don't gain that much additional insight from the document level analysis.
SELECT *
FROM TM_GET_RELEVANT_TERMS (
DOCUMENT IN FULLTEXT INDEX WHERE "Tweet" like '%England%'
SEARCH "Tweet" FROM "HANA_EIM"."RWC_T_STATUS"
RETURN
TOP 16
) AS T
After investigating the Text Mining functions TM_GET_RELEVANT_TERMS and TM_GET_RELATED_TERMS with Twitter data I found the core Text Analysis functions to be more than capable for my analysis purposes. If however I was analyzing news reports, blogs or documents then Text Mining would be much more appropriate

5. HANA Modelling
This piece took the longest and was fairly challenging as you need to model the Tweets with final output in mind. This turns the structured $TA table into a format suitable for analysis in Lumira (or other BI tool) by identifying the entities and the relationships, Countries, Tweets, Sentiment.
I created 2 Calculation Views in HANA Studio, they are still a work in progress, but are sufficient to give some useful output.
I felt it easier to create 2 as they are at different levels of granularity. One is at the Country level, the other at Country, Key Word

Base Data in the $TA_RWC-TWEETS table

Selected output from the Projection_3 above

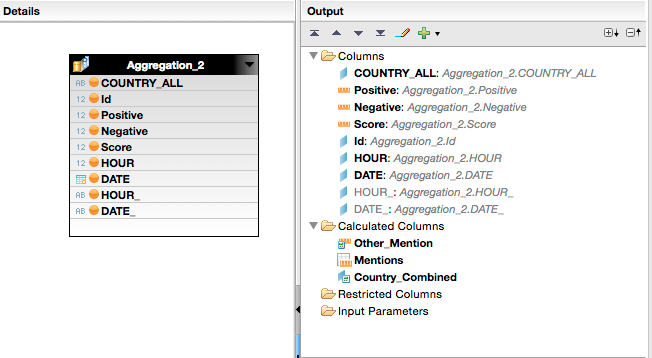
Aggregation_2 from the Calc View above, showing fields being used.

6. SAP Lumira Desktop to create some visualisations
With the modelling and manipulation taken care of in HANA, using Lumira is then easy (although you can spend some time perfecting your final output). Here we can build some visualisations as below and then encapsulate them into a story board.

My original visualisations have now been greatly enhanced by danieldavis into a great Lumira Story.
Daniel has also created a England Rugby Wall chart available for download from here http://www.thedavisgang.com/

7. SAP Lumira Cloud
To share the output in an interactive way we can publish the visualisaitons, stories and dataset to SAP Lumira Cloud. There's one crucial story option "Refresh page on open" that is required to update the visualisations within the story which by default is OFF. Set this to ON and the story also gets updated.
Lumira Desktop has a scheduling agent built in, once enabled it can automatically refresh and republish to Lumira Cloud.
I have set this to refresh the Rugby Tweet Analysis every day at 22:00
Within Lumira Cloud we now need to make the story public, this is set under the Story options


We now have the URL which can be shared with others, for ease of consumption I created a Short URL pointing to this long URL with http://tiny.cc/
To View the full interactive Lumira Story Board please use the link below

- SAP Managed Tags:
- SAP HANA,
- SAP Text Analysis
16 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
298 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
343 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Deliver Real-World Results with SAP Business AI: Q4 2023 & Q1 2024 Release Highlights in Technology Blogs by SAP
- Augmenting SAP BTP Use Cases with AI Foundation: A Deep Dive into the Generative AI Hub in Technology Blogs by SAP
- Generative AI: Some thoughts on using Embeddings in Technology Blogs by SAP
- Product Reviews Analysis using Generative AI and No Code Tools in Technology Blogs by SAP
- Post M&A considerations, including shared services (Enterprise Business Services). in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |