
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- Let's talk about the 'Elephant' in the room - The ...
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-16-2015
10:53 AM
 In this digital day and age it is very clear that the sources of data, and hence data itself are growing at a breath-taking pace.
In this digital day and age it is very clear that the sources of data, and hence data itself are growing at a breath-taking pace.
From historic business transaction data, to human-generated data like mails, documents and social media, to machine-generated data like sensor data, audio, video recordings, there is an exponential outburst of data.
But why would anyone be interested in all this “Big Data”?
Data, on its own is like a TV remote without batteries. Although it has all the relevant buttons, it doesn’t really get you anywhere.You would still have to get up and manually operate the television. That can be frustrating!


Just ‘Data’ of any type, no matter how large, is useless; unless you can glean 'value' out of it.
Gathering business insights out of Big Data should be the primary focus of all enterprises to ensure a bright future.
Before we start processing data to discover value, we need a mechanism to store the huge amount of data coming in, from the numerous big data sources.
Does the "Elephant" have any solution for such a storage mechanism?
In comes HDFS!
The Hadoop Distributed File System (HDFS) takes up the crucial role of storage in the Hadoop ecosystem. It is a sub-project of the Apache Hadoop project. It was originally built, as the 'Nutch Distributed File System' (NDFS), designated to be the groundwork for the Apache Nutch web crawler project.
So what ‘IS’ Hadoop Distributed File System?
HDFS Demystified
“HDFS is a distributed file system designed to run on commodity hardware.”

Let us dissect this statement for better understanding.
What is a ‘distributed file system’?
It is a method of storing and accessing files where one or more servers store files, that can be accessed by any number of remote clients in the network.
What is ‘commodity hardware’?
It is hardware that is affordable and easy to obtain. It is a low performance system without any special hardware requirements.
To summarize, HDFS is a distributed file system which can run on commonly available hardware, available from multiple vendors. It is designed to provide streaming access to the large data sets stored within. HDFS is also easily portable across different hardware and software platforms.
The moment you decide to use cheap, commodity hardware, you need to be ready for hardware failures. This in turn means, the file system needs to be fault-tolerant and reliable. HDFS ensures fault-tolerance, by following a concept called as 'Data Replication'. More on this later.
HDFS Blocks
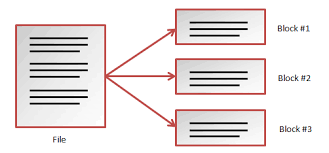
Every file which is written into HDFS is broken down into blocks and stored. A block is the smallest unit of operation (read/write) in HDFS. HDFS blocks can have sizes from 64MB to 128 MB currently. It is also possible to configure the block size for your cluster by maintaining a property value during setup.
HDFS Architecture
HDFS is designed on a 'Master/Slave' like architecture.
Major components of the system include Namenode (master), Datanodes (slaves) and HDFS Clients for Read/Writes.
A typical HDFS cluster consists of a Namenode, a secondary Namenode, connected to two or more Datanodes and clients to perform read/write operations.
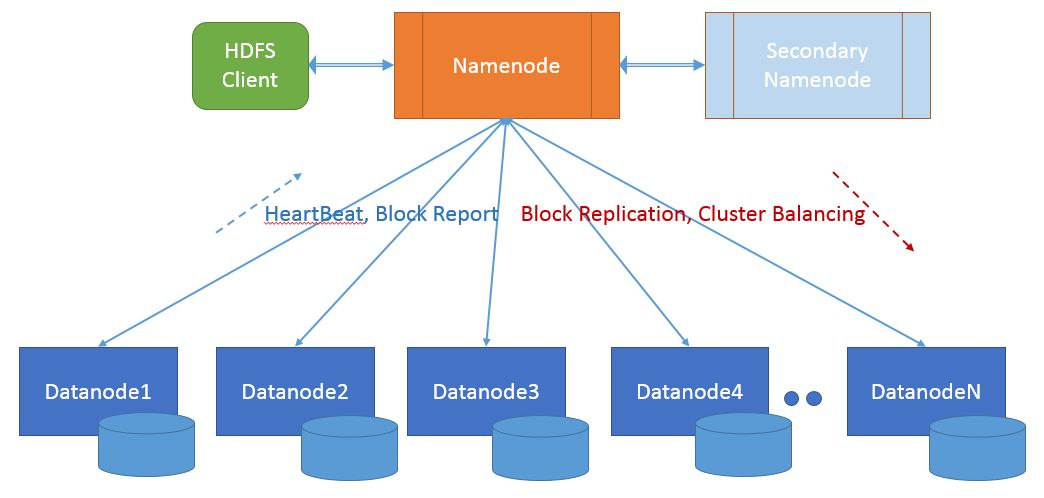
Let us look at each of these in fair detail:
Namenode:
The Namenode is the master component of HDFS which manages the file system namespace. It does not actually store any data/files. It is mainly responsible for maintaining the file system hierarchy (tree) and metadata like the block list of each file, file permissions, last access time, etc.
The Namenode has a webserver/site (Namenode UI) which shows the statistics related to the operations of the file system.
The metadata of the file system persists on the local disk of the Namenode in the form of two files:
- The namespace image (FsImage) and
- The transaction log (EditLog).

In the first generation of Hadoop, the Namenode was a single point of availability in the cluster. Failure of the namenode would make the cluster unusable. Although a secondary namenode did exist, it was used mostly for housekeeping and checkpointing operations.
Currently in Hadoop 2.x, there is the possibility of using the Namenode in High Availability mode.Automatic failover to a new Namenode can be configured.
Although, HDFS boasts of working with commodity hardware, it is generally suggested to use high end hardware for your Namenode, due to the importance of this component in a productive cluster.
Datanode:
Datanodes are slave components which actually store the data/files.
The datanodes communicate with the master Namenode through a Heartbeat signal sent periodically, indicating that the Datanode is alive and open for business! If the Namenode does not receive heartbeat signals from the Datanode for a specified period of time, it is marked dead and will no longer be used in the cluster for storage.
Datanodes are generally built on commodity hardware.
Data replication

To ensure fault-tolerance and reliable storage, HDFS replicates each block of data for a specified number of times (replication factor; default is 3), in the file system. The replication factor can be set at the cluster or at the individual file level.
Although it might seem redundant and a waste of resources, replication becomes quite necessary with the use of commodity hardware in the Datanode; thus acting as a protection against hardware failures.
If at any point, the number of replicas for a block goes down from the replication factor, the Namenode makes sure that the necessary replicas are recreated to maintain the replication factor consistent.
HDFS Clients:
HDFS clients are used to read and write files into the file system.
HDFS Write

Consider a scenario when a client wants to write a file “F” into HDFS. Based on the file size, "F" is divided into 3 blocks, say A, B and C.
Now the client contacts the Namenode to write block A into HDFS. The Namenode sends a list of Datanodes on which the block can be written and replicated, based on the replication factor.
Once the Datanode addresses are received, there is no further communication of the client with the Namenode. The client then contacts the Datanodes directly and writes the block into them via TCP.
Once done, the Datanodes inform the Namenode and the client of the write success.
HDFS follows a ‘write-once-read-many’ model, which means that a file once written does not need to be changed (in most cases). But there is indeed a possibility of appending writes to existing files.
Block placement
During a block write, HDFS choses the Datanode closest to the client to place the first block. This is done to reduce the read time and fasten the read process. The subsequent replicas are placed on any other Datanode, preferably on the same rack to reduce rack-to-rack traffic.
HDFS Read

Consider a scenario when a HDFS client wants to read file “F” from HDFS. The client will contact the Namenode to find which of the Datanodes contain the blocks of the file F. The Namenode sends out this information from its metadata. From now, the client directly contacts the Datanodes to read the different blocks of the file F and reconstructs it.
From the above point, it becomes quite clear that the Namenode should be aware of the different blocks of a file and which Datanodes contain these blocks. To facilitate this, the Datanode also sends out a BlockReport along with the Heartbeat to the Namenode, so that the metadata at the Namenode remains consistent.
File Delete
When a file is deleted, HDFS does not remove it immediately from the filesystem. It is just moved to the Trash directory.
Restoring a file from Trash is possible, until the trash directory is emptied, which is done periodically (default is 6 hours).
Scalability and High availability
HDFS Federation
It is possible to scale a HDFS cluster by adding additional Namenodes, each of which can manage a portion of the file system namespace.
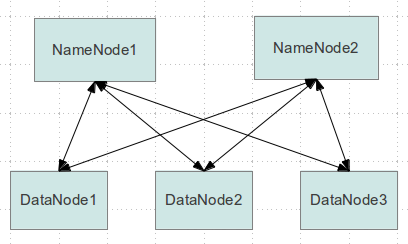
High Availability
Namenode:
A pair of Namenodes can be setup in an Active - Standby configuration, which can take over on failure.
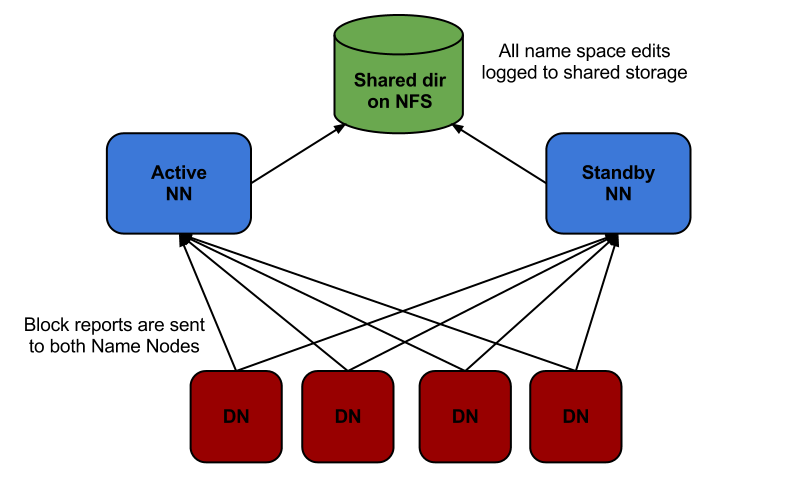
For this to work,
- the Namenodes should have a shared storage of the FsImage and EditLog,
- the Datanodes should send the block reports to both the Namenodes and
- the clients must know which is the Active Namenode to be contacted for Read/Writes.
The transition from the active Namenode to the standby is managed by a new entity in the system called the failover controller which is a pluggable component implemented using Apache ZooKeeper.
Client:
The Client failover is handled transparently by the client library.
Access to HDFS
HDFS can be accessed from application in many ways like Java APIs, C-wrapper for the Java APIs, HTTP Browser access, command line interface FsShell, etc.
Hope this blog has helped you get a fair idea on the basics of HDFS, the storage layer of the Hadoop ecosystem.
In the next part, we will look at distributed processing of data using MapReduce.
Links to the previous parts in the series:
Part1 : Let's talk about the 'Elephant' in the room - The prequel
Part2 : Let's talk about the 'Elephant' in the room - The Origins
2 Comments
Related Content
- Deployment of Seamless M4T v2 models on SAP AI Core in Technology Blogs by SAP
- SAP Datasphere's updated Pricing & Packaging: Lower Costs & More Flexibility in Technology Blogs by Members
- Implementing Automated Storage of TM Attachments in the SAP Document Management System in Supply Chain Management Blogs by SAP
- Advanced Returns Management for Supplier Returns in Spend Management Blogs by SAP
- SAP Master Tables in Technology Blogs by Members