
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- SAP Predictive Analytics - MBA (Automated, Expert ...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-14-2015
12:58 PM

Market Basket Analysis
Using SAP PA – Automated Analytics and R
Sudeepti Bandi
Kranthi Kumar Thirumalagiri

Author1: Sudeepti Bandi
Company: NTT DATA Global Delivery Services Limited
Author Bio
Sudeepti is a Principal Consultant at NTT DATA from the SAP Analytics Practice
Author2: Kranthi Kumar Thirumalagiri
Company: NTT DATA Global Delivery Services Limited
Author Bio
Kranthi Kumar is a Senior Principal Consultant at NTT DATA from the SAP Analytics Practice
Introduction
Advanced analytics and data science are fast evolving techniques that play a significant role in the present-day strategy and decision making for Businesses. Many organizations are starting to adopt practices that would help them in understanding their business data better and in building powerful insights into overall-functioning.Analytics has a vast scope in terms of usage. There are different tools available in the market to build data models that support business analysis and prediction/forecasting.
Market Basket Analysis is a popular methodology to find the associations between the products/items based on the transactions/shopping carts/market baskets of different customers. This type of analysis helps in identifying associations between items that can be sold together and can also help in cross-selling and up-selling.For example- the conclusion of this analysis looks like - Customers who buy product A are more likely to buy product B.
In this paper we would analyze a Retail dataset by leveraging the algorithms within SAP PA (Automated Analytics) and R to perform Market basket Analysis. We also explore the integration of R language with SAP Predictive Analytics.
Objective
Predictive analytics encompasses a variety of statistical techniques from modeling, machine learning, and data mining that analyze current and historical facts to make predictions about future, or otherwise unknown, events. There are several tools and technologies in the market that can be adopted to predict patterns in the given data set.
SAP Predictive Analytics is a statistical analysis and data mining solution that enables you to build predictive models in order to discover hidden insights and relationships in your data. This will enable to make predictions about future events. The tool has two products Automated Analytics and Expert Analytics. Automated Analytics helps in automating data analysis and addresses business problems without any manual intervention in data modeling or algorithm improvisation. This is used for less complicated use cases by data analysts. Expert Analytics is used to analyze data using in-built algorithms and also those from R (open-source programming language for statistical analytics). This is can be used for complicated use cases where manual intervention/control is necessary at different steps of the data modeling.
In this paper we would explore how we can perform MBA through Association rules in Automated Analytics in SAP’s Predictive Analytics using a Retail dataset. We would also perform the same using R (an Open Source programming language that is used for statistical analytics). We then compare the different options, features, output and effort in performing this analysis using SAP’s Predictive Analytics versus R. We would also explore the integration of R with SAP PA by calling the R algorithms through the Expert Analytics.
This kind of analytics is used in Retail industry, Recommender engines in E-commerce, Restaurants and tools to identify Plagiarism. There are several algorithms that could be used for Market Basket Analysis like the popular Apriori algorithm.
How does an Algorithm work
The primary input for the algorithm would be a data set of transactions from past within a business. Then the algorithm will automatically identify the patterns with in the data set. When we say patterns, it is such as the most frequently bought items together with in a given volume of transactions.
Algorithm then stores the pattern recognition logic and applies it to the new data set. This is called Training the Algorithm.
Algorithm for MBA - Apriori
Apriori is a popular algorithm used for Market Basket Analysis. The significant parameters of this algorithm are listed below-
- Association Rule
- Support
- Confidence
- Lift
Association Rule
A rule is denoted as below -
A -> B
A –Antecedent/LHS
B – Consequent/RHS
ü Where A and B are items from the data set of transactions.
ü They should occur together in different transactions to qualify for a strong association rule.
Support
This is calculated as a ratio of “Number of transactions where items occur together” to that of “Total Number of Transactions”. If A and B are bought together in 5 transactions out of a total of 20 transactions, then the support is calculated as 5/20 which is 0.25.
Confidence
Confidence is calculated as the ratio of “Number of transactions in which A and B occur together” to the number of transactions in which “A occurs”. If A occurs in a total of 10 transactions, out of which, B also occurs in 5 transactions along with A,
Then Confidence of (A -> B) is 5/10.
Which means, the chances of purchasing item B when item A is bought is 50%. The intensity of predicting the sale of item B is termed as confidence.
It is apparent that
ü For strong association, Support and Confidence have to be high.
ü Rules with low Support and Confidence could be eliminated
Limitation of Support and Confidence
ü Many important findings of associations will be eliminated if they have low Support, however a low Support could be because the item is expensive and is not occurring frequently. Low support not necessarily mean can be ignored. It depends on the discretion of the analyst.
ü High confidence is misleading at times, The Confidence of A and B might be 5/10 but overall occurrence of B could also only in these 5 transactions and hence not dependent on A.
Lift
It is the measure where we assume that the Antecedent and Consequent are independent. Calculated as, ratio of Confidence of (A -> B) to the Support of B.
Apriori Principle-
If an item set is frequent then all of its subsets must also be frequent.
If the item set: {A, B, C, D} is frequently occurring, then the subsets listed below are also frequent.
3 items sets - {A,B,C} {A,B,D} {B,C,D} {C,D,A}
2 items sets- {A, B}, {A, C}, {A, D}, {B, C}, {B, D}, {C, D}
1 item sets - {A} {B} {C} {D}
Let us first consider a very simple example –
- A dataset listing purchases from a Stationery Store.
- There are 11 transactions
- We aim to manually identify the associations between the items in this dataset in a way the actual Apriori works.
- We use similar method as Apriori – associations calculated through different iterations based on the support value we choose.
The table below has the 11 transactions -
1 | Pencils | Eraser | Sharpener | |
2 | Covers | Labels | Notebook | Stapler |
3 | Colour pencils | |||
4 | Pencils | Eraser | ||
5 | Notebook | |||
6 | Notebook | Pencils | Eraser | |
7 | Covers | Labels | ||
8 | Crayons | |||
9 | Glue | Covers | Labels | Notebook |
10 | Pencils | Eraser | ||
11 | Notebook |
Now this is how the algorithm works:
Step 1- We can consider a minimum Support of 2.
The first iterations will be for all single items. All items that appear for 2 times or more are considered. We count the number of times each item appears in the transactions.
Pencils | Eraser | Sharpener | |
Covers | Labels | Notebook | Stapler |
Colour pencils | |||
Pencils | Eraser | ||
Notebook | |||
Notebook | Pencils | Eraser | |
Covers | Labels | ||
Crayons | |||
Glue | Covers | Labels | Notebook |
Pencils | Eraser | ||
Notebook |
Single occurrences are as below -
Notebook- 5
Pencils - 4
Eraser- 4
Labels - 3
Covers - 3
Step 2-
We now take occurrence of the items above in couples i.e. in combinations (only the singles with support greater than 2 that are listed above will be considered for this iteration). We also eliminate single item transactions with Support lesser than 2.
Pencils | Eraser | Sharpener | |
Covers | Labels | Notebook | Stapler |
Pencils | Eraser | ||
Notebook | Pencils | Eraser | |
Covers | Labels | ||
Glue | Covers | Labels | Notebook |
Pencils | Eraser |
Count the number of times each of the combinations below appear in the table above,
{Notebooks, Labels}- 2
{Notebooks, Covers}- 2
{Pencils, Eraser}- 4
{Labels, Covers}- 3
Step 3-
We can consider item sets of size 3 with support greater than or equal to 2. There is only one item set that is occurring twice i.e. the one mentioned below.
{Notebooks, Covers, Labels}- 2
Discovery/Inference-
- Customers buying Pencils also buy Erasers
- Customers buying Notebooks and Covers also buy Labels
- Customers buying Covers also buy Labels
Based on the outcome, we can take decision on availability of stock, positioning of items in the store, promotions etc.
We can start with minimum values for Support and Confidence and depending on the Use case, set them at an optimum level after several iterations.
Working in SAP Predictive Analytics
Automated Analytics
Dataset:
There are two datasets. One dataset has all the unique transaction IDs – reference data source. The other dataset has different transactions and the corresponding items – events data source; has two columns. The datasets have 200 transactions.
Reference data source is as below, it has one column:

Events data source is as below, it has two columns.
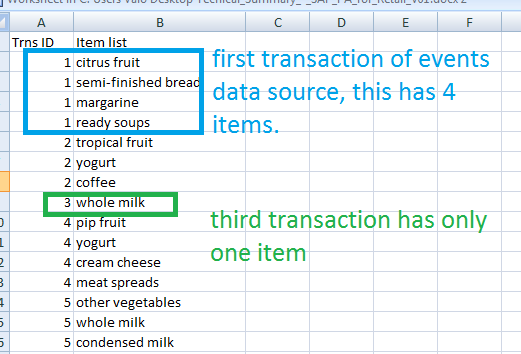
Step 1: Load and describe/analyze Reference data source


We can either load a file that has descriptions of the reference data source or ask the tool to analyze the column and then change column types if needed. Here the Column C1 contains the transaction IDs and to be defined as ‘nominal’ or ‘ordinal’.
Step 2: Load Reference data source
Repeat the same steps for Events data source.

Step 3: Set parameters for the algorithm

Step 4: generate the model

Now we see that the tool has identified the number of transactions. This report can also be saved and distributed for future reference (PDF format available).
We can also view, save and distribute the statistical information about the rules, item sets. Example -frequency distribution for the items in the transactions. For the dataset we have taken, we can see that ‘whole milk’ is the most frequent item.

For this example, with minimum support of 2% and minimum confidence of 50% the tool generated 24 rules.
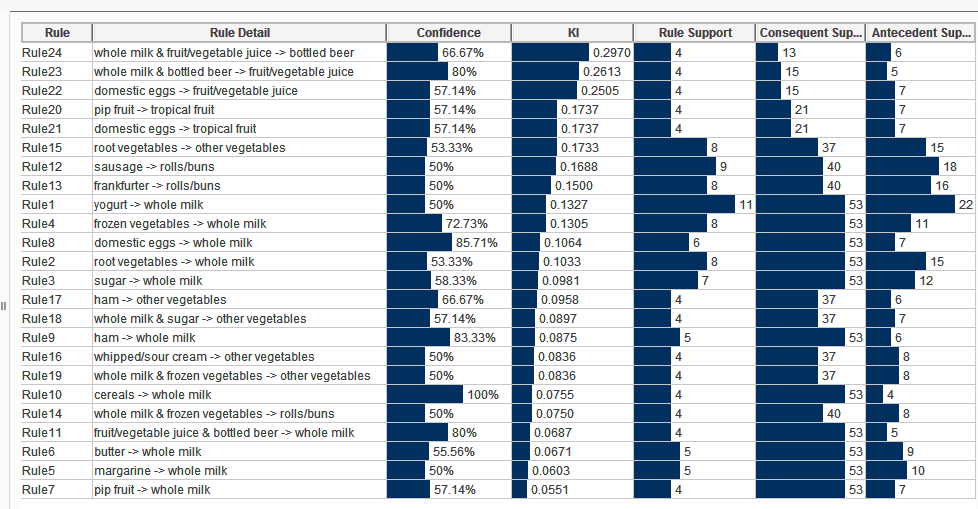

We can focus on a particular item as antecedent or consequent based on the business requirement/question.
We can also filter on the range of numeric parameters of the model, for example we can search for rules with support >= 0.03 or rules with confidence >= 60%.

If we give a rule size to be greater than 2 all the rules generated are covered. The graphical representation of the filtered rules, is as below-

Let us focus on whole milk as consequent as this is the most frequent item. We have an option to fix the consequent. We get 7 rules for whole milk as consequent.



We can see a strong association between ‘yogurt’ and ‘whole milk’.
Discovery/Inference:
- Customers buying yogurt are more likely to buy whole milk.
- Customers buying sausage are more likely to buy rolls/buns
- Customers buying root vegetables are more likely to buy other vegetables.
This way we can derive many rules and take business decisions for cross selling, up-selling, promotional offers and store layout using Market Basket Analysis.
Working in R
In R, any functionality beyond the basic version is available in the form of packages. The algorithm we are going to use in R for Market Basket Analysis is Apriori.
Step1: Download and install arules and arulesViz packages. These are relevant to Apriori and the corresponding graphs.
Step2: Call the Groceries dataset from arules package/ load any retail data set into R.
Code:

Step 3: Plot the frequency distribution of the Items.
Frequency distribution for the graph is as below.

Step 4: Apply Apriori algorithm.

For similar parameters, R’s Apriori has generated 32 rules, however the significant rules and their parameters are similar but not exactly the same.

Step 5: Plot the rules/associations identified.
There are several plots in R to represent the rules and the parameters of Apriori. Few of them are grouped, matrix and graph.
The “graph” looks as below for the 32 rules –

If we confine the consequent (LHS) to “whole milk” then the grouped plot and the graph look like below:


Working in Expert Analytics
We will now explore how this can be done using the Expert Analytics. The Apriori algorithm is called from R. Aim of this section is to demonstrate how well SAP has brought in the integration with R and its functionality; and the visuals and ease of use are the advantages of this tool.
Step 1: Load the dataset

Step 2: Apply R-Apriori, in Expert Analytics.

The settings for the algorithm can be given as below -

We then run the model. The rules generated are displayed.

The Association chart in Expert Analytics graphically represents the associations as below.

The output is same as in R. A display of summary gives the output as in R.
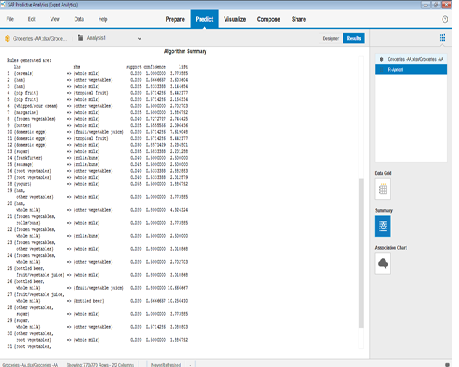
Note that the data format for datasets used in all the three tools is similar. Only for Automated Analytics we have an additional dataset to load the Transaction IDs.
Conclusion
- Visualization is better in SAP Predictive Analytics.
- SAP PA has a better UI.
- R is an open source however the R studio server installation has to be purchased.
- There are more options in R to perform Market Basket Analysis. However, SAP Predictive Analytics has an option to integrate the functionality of R through Expert Analytics.
- SAP Predictive analytics enables 2 different types of models for a use case, through Automated and Expert Analytics. Hence as per business requirement and suitability we can use either of them.
- SAP PA Automated Analytics -The output and statistical reports during the preparation of the model can be downloaded and distributed easily in PDF format
References:
Image courtesy: https://pixabay.com/en/shopping-cart-chart-store-shopper-650046/
http://scn.sap.com/community/predictive-analytics/blog/2015/06/28/predictive-smackdown-automated-alg...
- SAP Managed Tags:
- SAP Predictive Analytics
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- Forecast Local Explanation with Automated Predictive (APL) in Technology Blogs by SAP
- Predictive Forecast Disaggregation in Technology Blogs by SAP
- Efficiency and Insights with Calculation Runs in SAP SuccessFactors Incentive Management in Technology Blogs by SAP
- SAP Cloud ALM Implementation and Operations Configuration Webinar Series in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |