
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- More control over how Models can be compared in SA...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-04-2015
2:34 PM
The ability to compare models (or data sets) using a component in a chain makes things simpler for the analysts. The first step was taken in a previous release where this was achieved by dropping a new component in a analysis chain which internally compared the Key Performance Indicators (KPIs) and a  highlighted the best node. Now, with this new release, more control is afforded to the analyst where one can select the KPIs they want the compare performance on and also specify an order to break a tie if such a condition occurred. The compare node also lets the user pick a partition set for the comparison thus requiring the partition component to be present before the algorithms in the chain.
highlighted the best node. Now, with this new release, more control is afforded to the analyst where one can select the KPIs they want the compare performance on and also specify an order to break a tie if such a condition occurred. The compare node also lets the user pick a partition set for the comparison thus requiring the partition component to be present before the algorithms in the chain.
Lets have a look at this process flow step by step where we'll build a chain using a data set on SAP HANA.
Step 1: Select a data set on SAP HANA to build the chain
We'll start the analysis by picking a view or table on SAP HANA and connect a Partition node so the data set is split into three sets. This will be used by the Model Statistics and Compare components following training. We'll then add three algorithms, classification from APL, Naive Bayes from PAL and a CNR tree in R.

Lets configure the partition node to split the data set into three slices of 80% for training, 10% for validation and 10% for testing the generated models.
We'll then configure the individual algorithms so they are ready to be trained on the train slice of the data set.
Note: the size of Validation and Test sets has to be greater than or equal to 10%.
Step 2: Add Model Statistics
Now with the algorithms configured, lets add the Model Statistics component to the algorithms so their performance statistics can be computed.
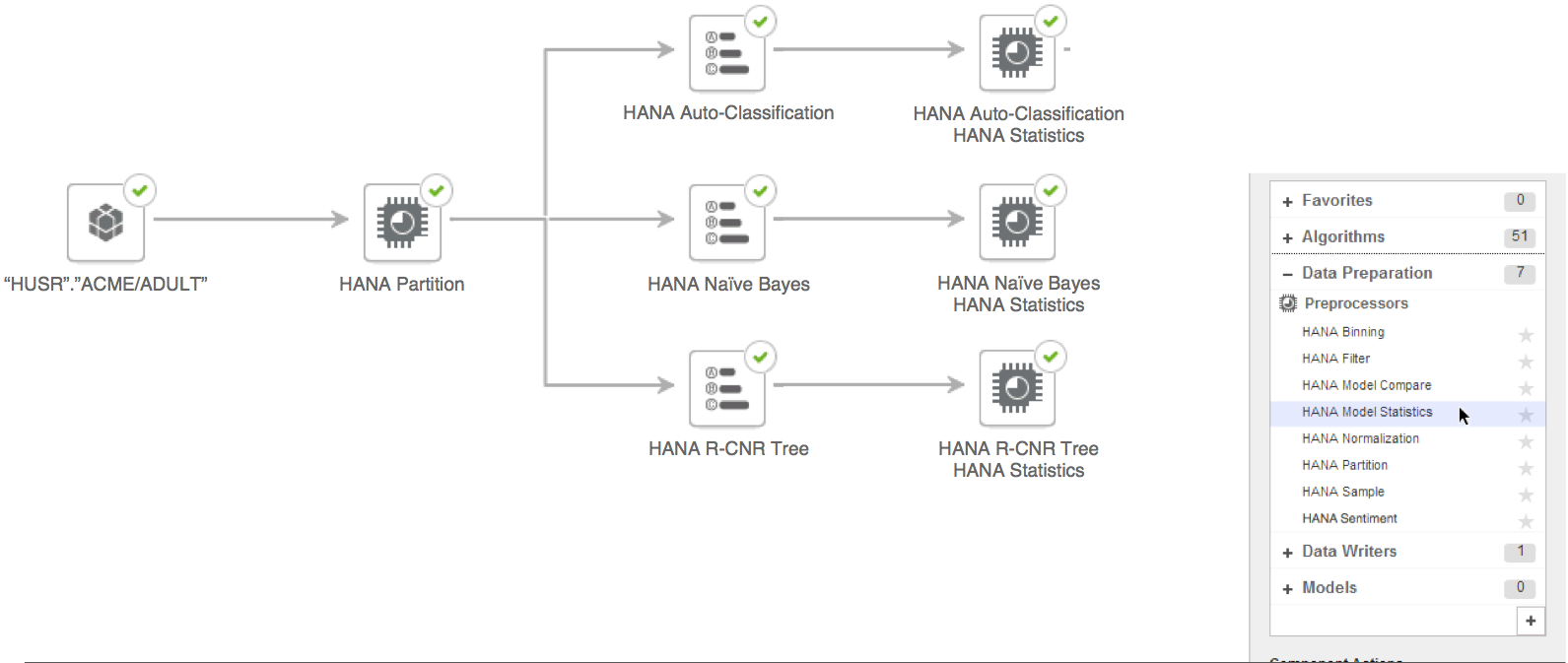
The three components automatically take the name of their parents and now these nodes can be configured though a very simple properties panel by double clicking on the components or through the context menu.

The Target Column is the column used as the target or dependent column in the supervised training of the parent component and the Predicted Column is the column that lists the predicted values generated by the trained algorithm/model. Availability of this independent component makes it possible for the analyst to compute performance statistics for not just the standard algorithms available in the solution but on custom components and data sets too.
Step 3: Add Model Compare component
With the Model Statistics node configured, lets add the Model Compare component from the right hand panel.

Now, the Compare component can be connected to the other Model Statistics components by dragging and dropping on them one by one.
Note: For simplicity, this example uses three parents but Model Compare node can be used to compare more than that at a time.

Once all parent components are connected, the Model Compare component can now be configured.

Step 4: Configure the Model Compare node to define how you would like it to compare models
The Model Compare component can be configured in four different ways..
- Comparing Classification models (two class)
- Comparing Regression models
- Comparing two Classification or Regression models.
- Comparing three or more Classification or Regression models.
A Model Statistics component is required to be the parent of Model Compare since it relies on the statistics calculated by it. It also get the algorithm type (classification or regression) from it and displays different KPIs based on it.
Configuring Model Compare for Classification
When comparing Classification algorithms, the properties panel lists the KPIs relevant to classification modeling as below:
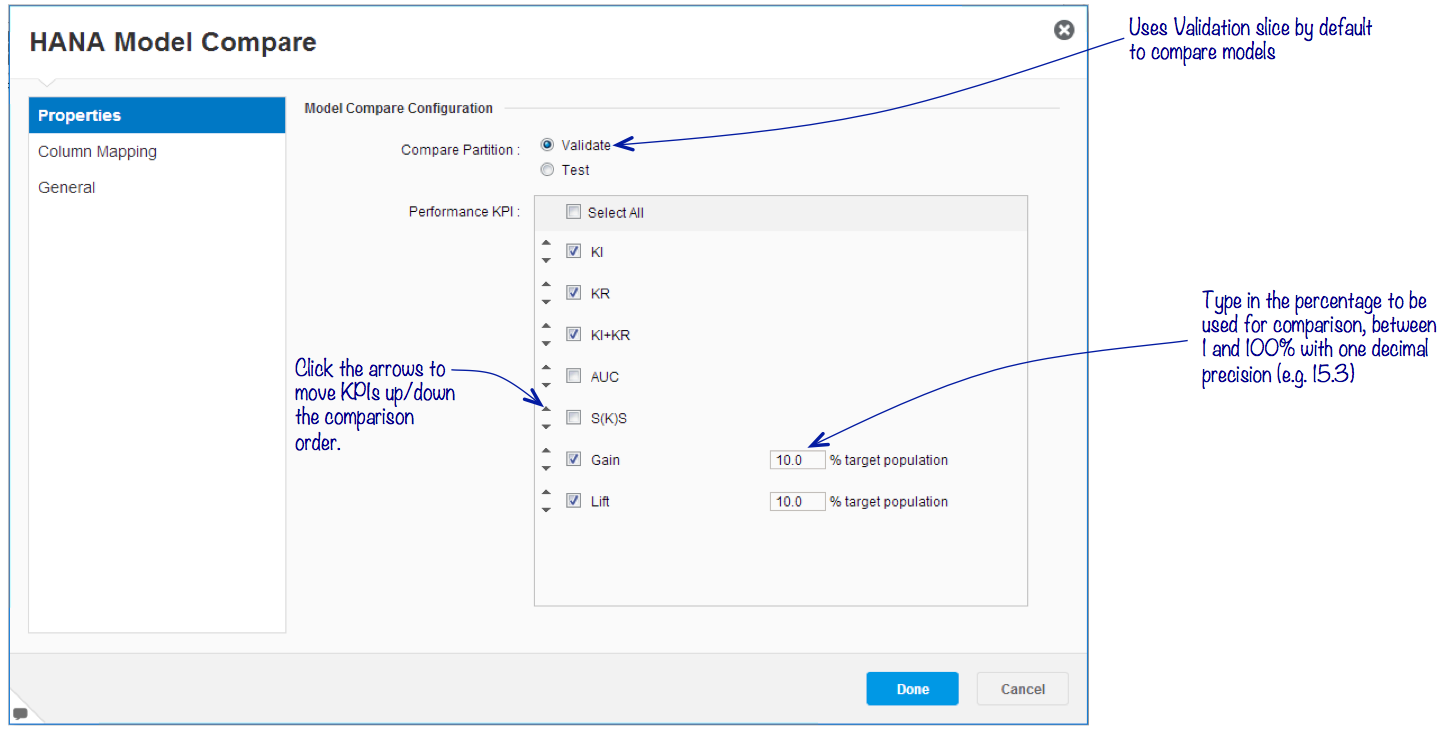
Here, the analyst can pick which slice of the partitioned data set should be used to compare the performance of the individual KPIs selected. The order of the KPIs will be used in situations where there is a tie in the KPI being compared.
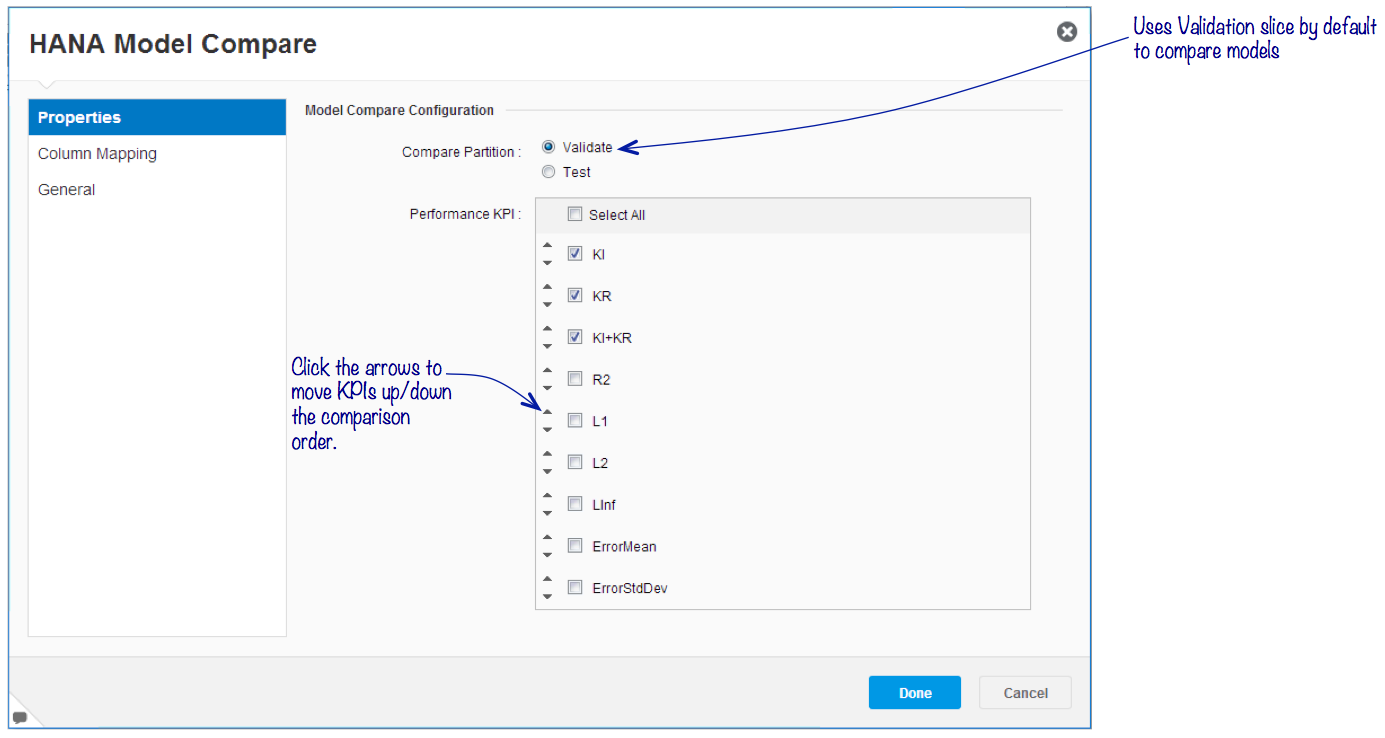
Configuring Model Compare for Regression
The properties panel lists KPIs relevant to regression modeling and the analyst can choose the partition slice to use for comparing the performance of training the models.
Step 5: Extend the analysis further when comparing two models
To enable extending the analysis chain with more components, its important for the Model Compare to have a results table at the end of its execution. When comparing models, there will ever be one winner and there needs to be a way to map it to the output of the compare node. Therefore, its possible to map the columns from two parent comparison into a single set that will form the output table of the Model Compare node. In all other cases, the Model Compare node will become the terminal or leaf node in an analysis chain..
When comparing two algorithms/models, the following mapping screen will be enabled to allow column mapping.

Icons: The icon on the Model Compare node will change indicating whether or not the analysis can be further extend.
![]() Indicates the Model Compare is working with two parents and can be extend.
Indicates the Model Compare is working with two parents and can be extend.
 Indicates the Model Compare is working with multiple parents and that its a terminal/leaf node in the analysis.
Indicates the Model Compare is working with multiple parents and that its a terminal/leaf node in the analysis.
Step 6: Run the analysis
Now that all the components in the analysis chain have been configured, clicking on the run button will execute the training of the chain. It can also be triggered from the context menu on the last component in the chain.
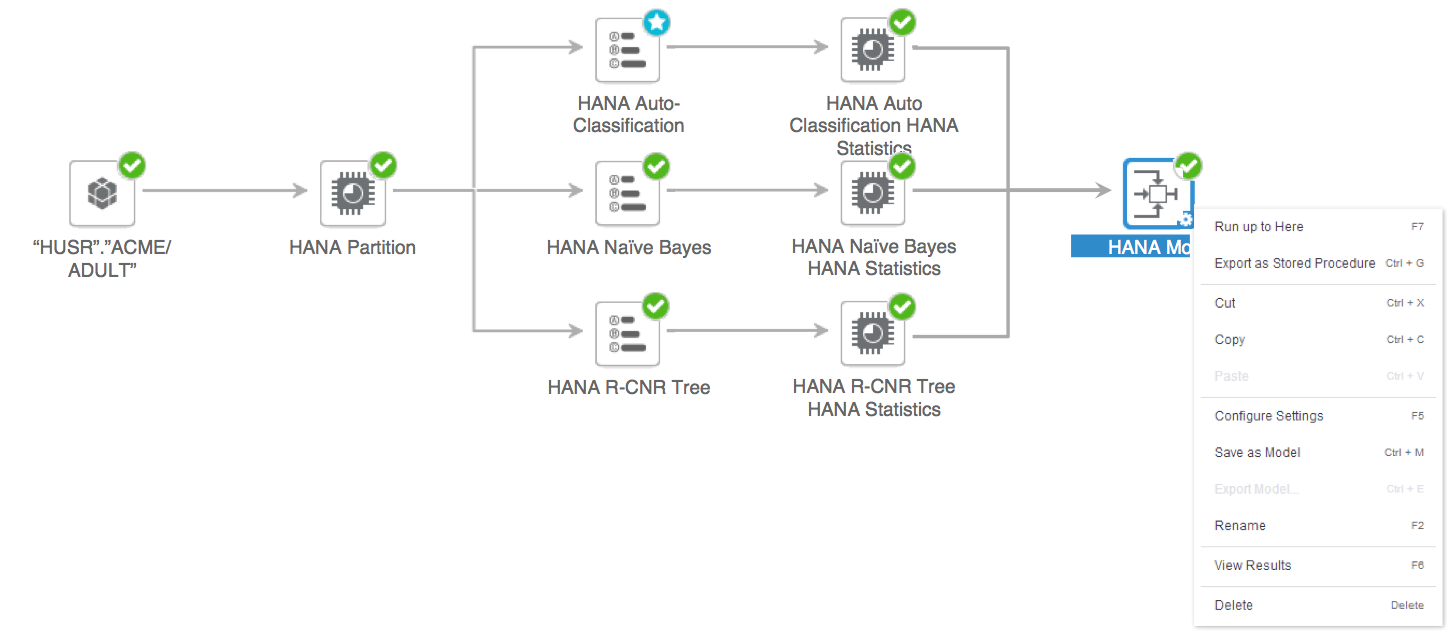
Results tab will show the results and performance of the training. Also, it is now possible to export the best algorithm as stored procedure directly from the Model Compare component.
Step 7: Results of training
More detailed summary
The Results tab will have the summary of individual components. The Model Statistics and Compare summary will now show more details on per partition. Here is a sample summary from the Model Compare component comparing with three Classification algorithms/models:

It indicates the best model based on the KIPs selected and the partition used for comparison. Regression comparison results will list the regression KPIs. The KPIs in bold highlight the ones selected in the Model Compare properties panel and algorithms/models in bold indicate the best performer in a partition. The best node chosen based on Model Compare configuration is indicated in blue with the star icon.
More charts
Charts in Model Statistics component will display performance details from individual partitions and Model Compare components overlays the outputs from different algorithms/models being compared and groups them for the individual partitions used in the process:

KPI Definition
Following table lists all the Classification KPIs with descriptions:
| KPI | Definition |
|---|---|
| Ki | Predictive power. A quality indicator that corresponds to the proportion of information contained in the target variable that the explanatory variables are able to explain. |
| Kr | Model reliability, or the ability to produce similar on new data. A robustness indicator of the models generated. It indicates the capacity of the model to achieve the same performance when it is applied to a new data set exhibiting the same characteristics as the training data set. |
| Ki & Kr | Predictive power and model reliability. Gives equal importance to the robustness and generalizing capabilities of the model. For more information, see the definitions above. |
| AUC | Area Under The Curve. Rank-based measure of the model performance or the predictive power calculated as the area under the Receiver Operating Characteristic curve (ROC). |
| S(KS) | The distance between the distribution functions of the two classes in binary classification (for example, Class 1 and Class 0). The score that generates the greatest separability between the functions is considered the threshold value for accepting or rejecting the target. The measure of seperability defines how well the model is able to distinguish between the records of two classes. If there are minor deviations in the input data, the model should still be able to identify these patterns and diiferentiate between the two. In this way, seperability is a metric of how good the model is; the greater the seperability, the greater the model. Note that the predictive model producing the greatest amount of separability between the two distributions is considered the superior model. |
| Gain % (Profit %) | The gain or profit that is realized by the model based on a percentage of the target population selection. |
| Lift % | The amount of lift that the trained model gives in comparison to a random model. It enables you to examine of the difference between a perfect model, a random model and the model created. |
Following table lists all the Regression KPIs with descriptions:
| KPI | Definition |
|---|---|
| Ki | Predictive power. A quality indicator that corresponds to the proportion of information contained in the target variable that the explanatory variables are able to explain. |
| Kr | Model reliability, or the ability to produce similar on new data. A robustness indicator of the models generated. It indicates the capacity of the model to achieve the same performance when it is applied to a new data set exhibiting the same characteristics as the training data set. |
| Ki & Kr | Predictive power and model reliability. Gives equal importance to the robustness and generalizing capabilities of the model. For more information, see the definitions above. |
| R2 | The determination coefficient R2 is the proportion of variability in a dataset that is accounted for by a statistical model; the ratio between the variability (sum of squares) of the prediction and the variability (sum of squares) of the data. |
| L1 | The mean absolute error L1 is the mean of the absolute values of the differences between predictions and actual results (for example, city block distance or Manhattan distance) |
| L2 | The mean square error L2 is the square root of the mean of the quadratics errors (that is, Euclidian Distance or root mean squared error – RMSE). |
| Linf | The maximum error Linf is the maximum absolute difference between the predicted and actual values (upper bound); also know as the Chebyshev Distance. |
| ErrorMean | The mean of the difference between predictions and actual values. |
| ErrorStdDev | The dispersion of errors around the actual result. |
- SAP Managed Tags:
- SAP Predictive Analytics
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- SAP Analytics Cloud for planning - Comparator Issue in Advanced Formulas in Technology Q&A
- ML- Linear Regression definition , implementation scenarios in HANA in Technology Blogs by Members
- Planning Professional vs Planning standard Capabilities in Technology Q&A
- Horizon Theme and Templates for Stories in SAP Analytics Cloud in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.07 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |