
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Writing Log Entries of a Java Application to an Ex...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
vadimklimov
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-21-2015
11:06 PM
Intro
In heterogeneous environments, it is commonly required to analyse huge amount of logs generated by various systems – and it is convenient to manage these logs centrally in order to avoid overhead caused by accessing local log viewing tools of each affected system. Generally speaking, there are several approaches in populating centralized log management systems with logs produced by backend systems:
- Poll logs: the backend system generates and persists logs locally and centralized log management system collects (polls) and processes generated logs periodically or ad hoc (real time on user demand);
- Push logs: the backend system generates logs and sends (pushes) them to the centralized log management system.
In this blog, I would like to focus on the second approach and describe one of its possible implementations suitable for SAP AS Java systems (for example, SAP Process Orchestration or Enterprise Portal) using standard APIs shipped with AS Java – namely, functionality of SAP Logging API. In sake of concretization of the example, let us consider the scenario where some application of the SAP PO system (in real world, it can be mapping, adapter or adapter module, some other application deployed on AS Java) generates logs and our intention is to propagate these logs to some JMS broker (for example, to the specific JMS queue hosted on that broker), which is used by centralized log management system to parse and process log records later on. The one may think of other communication techniques different from JMS – using the approach discussed in this blog, the solution can be adapted to particular needs and communication techniques, JMS has been chosen for demonstration purposes as a commonly used technique for building distributed solutions.
Some 3rd party logging frameworks implement approach of decoupling log producer (the application which utilizes logger and creates a log record) from log consumer (the application which processes logs) and have capabilities of propagating generated log records to destinations other than local console or file. For example, one of commonly used logging APIs – Apache Log4j – introduces a concept of appenders, which are components delivering the generated log record to the specific destination. Destination may be console, file, JMS queue/topic, database, mail recipient, syslog, some arbitrary output stream, etc. It is possible to deploy such 3rd party logging library to AS Java system and utilize its functionality, but as stated above, the goal of this blog is to describe the solution where SAP standard functionality is employed, so usage of 3rd party logging frameworks is out of scope of this blog.
Overview of log destinations in SAP Logging API
Architecture and main components of SAP Logging API are well described in SAP Help: SAP Logging API - Using Central Development Services - SAP Library. The aspect which is important for us in scope of this blog, is the way how logging framework sends log records out. The component responsible for management of this process is Log Controller. For each log location, it is possible to assign one or several logs, where Log is a representation of the destination to which the assigned Log Controller will distribute generated log records for the specific location. In SAP Logging API, there are several classes that implement logs and that may be of interest for us:
- ConsoleLog – used to write log record to System.err;
- FileLog – used to write log record to the specified file;
- StreamLog – used to write log record to an arbitrary output stream.
Log destinations can be configured in various ways:
- Programmatically from application source code (refer to Sample Java Code with Logging - Using Central Development Services - SAP Library);
- Using SAP Logging API Configuration Tool and preparing properties file that contains information regarding logging configuration, which is loaded further from the application level. Together with periodic reloading feature, this approach makes logging configuration very flexible since parameterization is done in the file and doesn’t require changes to source code of the respective application in case logging configuration should be modified. Refer to Configuration Tool - Using Central Development Services - SAP Library;
- Using AS Java ConfigTool and configuring the respective log destination. This approach can be used to configure additional destinations for FileLog and ConsoleLog. Rrefer to Adding, Editing and Removing Log Destinations - Monitoring - SAP Library.
There is a brief description of these log destinations in SAP Help: Log (Destination) - Using Central Development Services - SAP Library.
ConsoleLog is the simplest from them and is the least applicable when thinking of centralized log management system.
FileLog can be of use when we need to output log records not to default log files of AS Java, but to some specific file or a set of rotating files (potentially, to the location which is scanned by collectors of centralized log management system). This may be helpful, for example, if we need to persist log records generated by some application, in a specific dedicated file and not in a common shared application log files. FileLog is described in several materials published on SCN, such as:
- Karsten Geiseler’s blog Netweaver Portal Log Configuration & Viewing (Part 3);
- YiNing Mao’s blog Handle Standard JAVA Output Using Log File;
- Jacek Wozniczak’s blog Logging in Web Dynpro (Java) - a guide and tutorial for beginners [Part 1];
- Iwan Zarembo’s Wiki page How to create own log files on a SAP NetWeaver AS Java 7.0 - CRM - SCN Wiki.
You may also find relevant information regarding usage and configuration of FileLog in SAP Help: Output File - Using Central Development Services - SAP Library.
In this blog, my focus will be on the log destination StreamLog, which will be helpful in fulfilment of our requirement formulated at the beginning.
Demo
In sake of simplified demonstration, logging configuration will be implemented from the source code of the application.
In the demo scenario, Apache ActiveMQ is used as a JMS broker. The JMS queue named Logs has been registered there and is intended to be used as a destination for generated logs so that log records are accumulated and persisted in that queue:
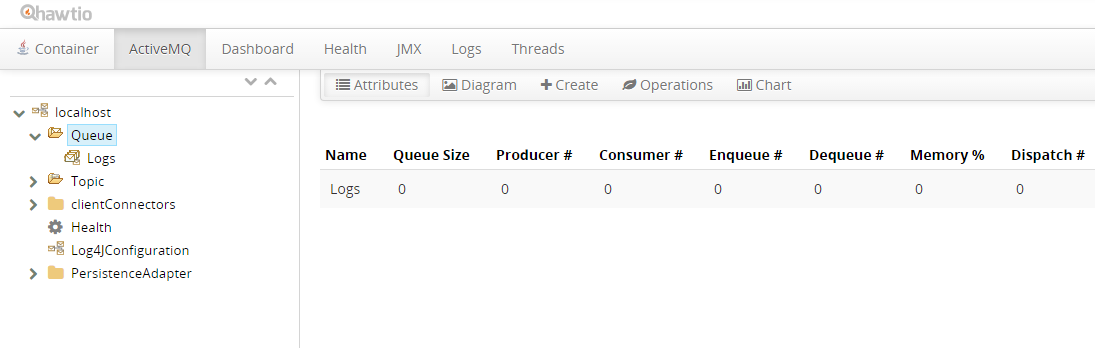
The entire utilized set of operations with the logging system can be logically split into three lifecycle phases:
- Initialization of the log destination and corresponding output stream, followed by initialization of a logger which writes to it;
- Generation of log records and writing them to the log destination;
- Termination and closure of used resources.
As a part of initialization, it is firstly necessary to establish connection to the log destination and open the output stream to it:
ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory(jmsBrokerUrl);
Connection jmsConnection = connectionFactory.createConnection();
jmsConnection.start();
Session jmsSession = jmsConnection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination jmsQueue = jmsSession.createQueue(jmsQueueName);
OutputStream os = ((ActiveMQConnection) jmsConnection).createOutputStream(jmsQueue);
Here, jmsBrokerUrl is a String holding JMS broker URL (tcp://<host>:<port> for ActiveMQ – for example, tcp://activemqhost:61616) and jmsQueueName is a String holding JMS queue name (in this example, Logs).
The next step is to initialize the logger:
Location logger = Location.getLocation(logLocationName);
logger.setEffectiveSeverity(Severity.ALL);
Formatter formatTrace = new TraceFormatter();
Log logJms = new StreamLog(os, formatTrace);
logger.addLog(logJms);
Here, logLocationName is a String holding log location name (can be arbitrary meaningful name which would, for example, identify the log location in the application hierarchy).
Note that in this example, we used a simple trace formatter – based on requirements, it is possible to utilize variety of other formatters in order to apply required layout to the generated log record. In sake of demonstration, severity was explicitly set to all – depending on logging needs, this can also be adjusted accordingly.
The important part of this block is creation of the Log object (that represents the JMS queue to which log records will be written) and adding this Log to the initialized logger. In this way, the logger gets instructed regarding destination or several destinations (if several Log objects are created and added to the logger), to which generated and filtered log record should be written to.
After two initialization blocks are executed successfully, we can now create log records - in the simplest way, by calling method <severity>T() of the Location object, which is corresponding to the desired log record severity:
logger.infoT(logRecordText);As a result, the created log record will be sent to the queue hosted on ActiveMQ server and can be observed there:


Attention should be paid to termination logic in case the application doesn’t need this log destination anymore – this is important in order to ensure there is no resource leak (unclosed streams, sessions, connections, etc.). To be more precise, it is important to take care of closing the used output stream, JMS session and JMS connection:
os.close();
jmsSession.close();
jmsConnection.close();
Respective exception handling and proper output stream closure and JMS resources release should be implemented accordingly.
After the log record has been written to the JMS queue and persisted there, the centralized log management system may process it further - for example, aggregate with other log records based on some rules, retrieve required information and visualize it in a user-friendly way, generate alerts, etc. That part of log management is out of scope of this blog - our current goal was to make log records of the application running on AS Java delivered to the central destination and storage.
Outro
This described solution has several drawbacks which should be taken into account:
- Performance. A log record is created and written to a log destination synchronously. This means, logging operation is a blocking operation for the application which triggered log record creation and the application has to wait until log record creation operation is completed, before it can continue execution of application logic. As a result, the more time is spent for logging logic, the more performance overhead logging will bring to the application and bring negative impact to overall processing time of the application. Writing log entries to the remote log destination (such as remote JMS destination, remote database, etc.) is more “expensive” operation than writing them to a local file system, that’s why should be implemented carefully. Compromise can be found in locating the log destination (for example, JMS broker instance) as close as possible to SAP AS Java.
- Lifecycle of operations with the output stream prescribe necessity of prior creation of the output stream with attachment to the specific data destination and finalization of writing to the output stream by closing the stream and respective connections. These operations should normally be executed at initialization and termination phases, correspondingly, and not for every written log record, in order to avoid additional overhead related to output stream management.
- Possible necessity of 3rd party libraries deployment. In order to utilize log destinations which are components other than SAP AS Java, it may be needed to deploy 3rd party libraries which will provide necessary APIs for SAP Logging API to be capable of writing to those destinations. In its turn, this brings necessity of maintenance overhead of such a solution and ensuring compatibility of deployed libraries during upgrades.
Summarizing all described above, StreamLog is a powerful and flexible feature of SAP Logging API in building centralized log management systems and facilitating logs processing and analysis routines, but it should be estimated and used thoughtfully.
- SAP Managed Tags:
- SAP NetWeaver Application Server for Java
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- When to Use Multi-Off in 3SL in Technology Blogs by SAP
- Clearance by virtual account of summary invoices in Technology Q&A
- Corporate Git Setup on SAP BTP versus connecting to Corporate Git directly from SAP BAS in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |