
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- The future of the SAP EDW: Interview with Juergen ...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-14-2015
10:00 AM
This blog has previously been published on my company's website, and posted here to reach the SCN audience as well.
At the High Tech Campus Eindhoven, the Netherlands. Juergen Haupt, Product Manager SAP EDW (BW/HANA) gave a presentation for the Dutch User Group (VNSG). In the morning before the meeting, I was fortunate enough to get the chance to sit down with Mr. Haupt for an interview.
About SAP BW on HANA, LSA++, Native development, S/4HANA Analytics and everything in between.


Left: Juergen Haupt, SAP. Right: Sjoerd van Middelkoop, SOA People | Intenzz
Mr. Haupt, welcome to Eindhoven! Please introduce yourself to our readers.
Well, thank you, Sjoerd! Ok, my name is juergen.haupt and I am now with SAP for 18 years, working in the area of Data Warehousing. Before joining SAP, I worked at Software AG, where I had the first contact with Data Warehousing. Starting to work with the early releases of SAP BW it quickly became clear to me that BW was a fully new BI approach bringing business requirements into focus. Nevertheless the first versions were primarily focused on OLAP, not on data warehousing like for example defined by Bill Inmon. Knowing about the impacts of ‘stove pipes’ and encouraged by customers. I began pushing the idea of Inmon’s ‘single version of the truth’ and the ‘conformed dimensions’ of Kimball towards an architecture driven BW approach. Around 2005 more and more customers positioned BW as their Enterprise Data Warehouse and asked for more guidance on how to set up a BW EDW. As a consequence we defined the Layered Scalable Architecture (LSA) that has become the standard setting up a BW EDW on AnyDB today.
But there is never a standstill. So in the moment where we had reached a solid, generally accepted state of LSA on RDBMS - SAP HANA and little later BW on HANA entered the scene…. And this is the reason LSA++ for BW on HANA is the successor of the LSA for BW on anyDB.
Q: So, if we compare the ‘traditional’ BW to BW on HANA – what are the major differences?
Well first of all customers that moved to BW on HANA report tremendous performance gains with respect to data loads and querying. Then they notice the simplification through less InfoCubes. Further simplification we see in BW on HANA 740 SP8 thru the new Advanced DSO that replaces traditional DSOs and InfoCubes. In addition to simplification comes the flexibility thru new CompositeProvider that allows combining any BW InfoProviders (DSOs, the new Advanced DSOs or InfoCubes) and create new virtual solutions. Even combinations with HANA native models outside of BW are possible.
But there are benefits at the second glance that are may be not so well known: let’s call it ‘the new openness of BW on HANA’. We all have the experience on what integrating non-SAP raw data in BW meant in the past certain efforts. You had always to assign and define InfoObjects to the raw data fields. This is now no longer a prerequisite to integrate data into BW as BW on HANA 7.40 comes with the so called field-based modeling. Field-based modeling means that you now can integrate data into BW with considerably lower effort than before. Regardless whether you load data into BW or whether the data resides outside BW: you can now directly model and operate on field level data without the need of defining InfoObjects in advance and subsequently mapping the fields to the InfoObjects. This makes the integration of any data much easier. And how is this achieved? Well the new Advanced DSOs allows storing field-level data in BW. Advanced DSOs can have only fields, a mixture with InfoObjects or just InfoObjects, like the old DSOs. On top of the BW Advanced DSOs with fields or on any SQL/ HANA view outside BW you define the BW on HANA Open ODS Views to model reusable BW-semantics identifying facts, master data, and semantics of fields like currency fields or text fields. Furthermore in Open ODS Views you can define associations between Open ODS Views and InfoObjects what means you model virtual star schemas. Last but not least you can use Open ODS Views in a query or combined with other Providers in a CompositeProvider like any InfoProvider
So in short BW on HANA is capable to model and work on raw data regardless where they are located and we can integrate these raw data with the harmonized InfoObject-world by associating InfoObjects in Open ODS Views to fields.
The idea of working with raw data in BW and the early and easy integration of raw data results in the new ‘Open ODS Layer’, which brings BW and the sources closer together
Q: So what you are saying is that the functionality that has been developed for BW on HANA is actually created from an architectural point of view, and not from a technological point of view?
Exactly, this is an important driver. Knowing that HANA can work on data like it is, without transforming the data into specific analytic structures you should be able to work with virtual objects directly on any field level data. Bringing the source systems closer to BW means that we need to have something intermediate between the source and the fully fledged and top down modeled EDW described by InfoObjects. This is achieved by the Open ODS Layer.
Q: LSA++ is, as you stated, the successor of LSA for BW on HANA scenarios. What are the main differences between the LSA approach and LSA++?
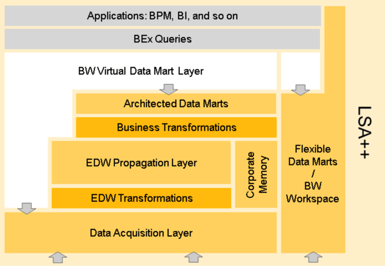 No architecture stays forever. Any architecture has to be reviewed continuously especially when the circumstances change. When HANA came along and a little later BW on HANA was released, colleagues asked me very early “Juergen, can you make an update of LSA for BW on HANA?” I hesitated, because it was clear that BW on HANA is more than just exchanging the relational database, more than the offering of the in-memory BW Accelerator. This is why just an ‘update of LSA’ was and is not adequate – I do not want to bore you with the discussions we had – we can see the results looking to BW on HANA 7.4 and the LSA++ as successor of LSA:
No architecture stays forever. Any architecture has to be reviewed continuously especially when the circumstances change. When HANA came along and a little later BW on HANA was released, colleagues asked me very early “Juergen, can you make an update of LSA for BW on HANA?” I hesitated, because it was clear that BW on HANA is more than just exchanging the relational database, more than the offering of the in-memory BW Accelerator. This is why just an ‘update of LSA’ was and is not adequate – I do not want to bore you with the discussions we had – we can see the results looking to BW on HANA 7.4 and the LSA++ as successor of LSA:
Bearing in mind what I said before about BW on HANA we can look at LSA++ from two different perspectives – the first I call LSA++ for simplified data warehousing.
This perspective deals with the traditional way of doing data warehousing, moving data to BW and organizing the data in a proper way. With LSA++ the architecture becomes far more streamlined and flexible. We can find here two major differences with respect to the traditional LSA: First- making persistent Data Marts – BW InfoCubes - obsolete using virtual composition of persistent data (CompositeProviders). The result is the LSA++ Virtual Data Mart Layer. Second bringing BW closer to the source data thru BW field-based modeling. The result is the Open ODS Layer.
The Open ODS Layer broadens our architecture options as it may serve as inbound layer not only for an EDW Layer that is described mainly by InfoObjects. We can also stage the data in a DWH layer that is mainly described by fields. We call this a raw or domain data warehouse. A Domain data warehouse is dominated by one leading source system and all other sources integrate in the domain DWH with respect to this leading source. For example an S/4HANA can be such a leading source system. All other sources would then integrate in the related BW domain data warehouse with respect to the S/4HANA semantics and values. Defining InfoObjects is always necessary if you have to harmonize multiple equivalent sources – this is the well-known EDW case.
But LSA++ is more than just simplified data warehousing. It is an open architecture, allowing an evolutionary DWH approach. I call this the LSA++ for logical data warehousing. It means a complimentary perspective to the traditional LSA++ simplified data warehousing perspective: sources of any nature (operational sources, data lakes like Hadoop or Open ODS as Data InHubs) play an equivalent role like the data warehouse: they are a basis for analytics. The logical data warehouse like described by Gartner provides analytics and reporting on the original data as long as you can keep the service level agreements and cover the business requirements. You move data to the data warehouse only if the service requirements are violated or the business requirements cannot be fulfilled.
The LSA++ supports the logical DWH approach via an agile virtual data mart layer. Agility comes in from two modeling options in BW on HANA. First it comes in through the CompositeProviders allowing you to combine any BW Provider with HANA models from outside BW, wherever they are located. Second it comes in through Open ODS views of type fact, master or text allowing defining dimensional models on any data outside of BW defined by tables, sql-views or HANA views. You have always the possibility to switch a virtual Open ODS View source to a persisted BW Advanced DSO, like suggested by the logical DWH approach. Switching from virtual to persisted means that BW on HANA generates the data flow from the remote source to an Advanced DSO and the Advanced DSO itself based on the definition of the Open ODS View.
If you look to the virtual models on the source systems, like offered by HANA Live or S/4HANA Analytics, BW can then be considered as an extension offering additional services like historic data, business consistent views et cetera that the source cannot offer. The transition from the source model to BW can then happen in a very dynamic way.
Q: On SAP HANA you can define normalized DWH models like Data Vault directly. Data Vault is quite popular with Dutch companies. Do you think Data Vault modeling is a valid alternative for SAP ERP data?
We call our team SAP EDW Product Management, so that implies that we cover both BW on HANA and HANA native data warehouse modeling as we call it. A native HANA data warehouse can be modeled using any known DWH model (e.g. dimensional, 3NF, data vaults).That means freedom but also threat. Threats especially for customers who decide about their future DWH architecture based on sentiments and a BW-perception that is driven by the past. We find all kind of BW perceptions in the market: people who love it and for whatever reason people who dislike it. I have a quite good idea why people may dislike BW but one thing is clear to me: sentiments are a bad advisor. Having a bad perception about the traditional BW in mind we saw already customers who tried to build a native HANA data warehouse for SAP Business Suite sources saying “we have an SAP source system, and other SAP tools like Powerdesigner and Data Services, so we are going to ‘Vault it’. Making a long story short: finally this ended up as a nightmare as you have to rebuild all the semantics, associations and annotations natively. And it offers no business value because with BW, you get all this for free: BW knows these semantics because of the tight dictionary integration between SAP sources and BW.
In addition Data Vault modeling assumes that you should always expect the worst from your sources. It assumes that at any time and frequently source-model changes can happen that enforces you to change your DWH models and links and so on. But that is not the reality with SAP source systems. The SAP source models are in general pretty stable making the dimensional BW model working very well. Vaulting in general for SAP sources brings in complexity that cannot be justified.
Q: This is the case with standard SAP content. There is however not a single customer I know without quite a bit of customization in their SAP system. And this inability to adapt to these changes is a strong part of criticism on BW.
Yes, you are right and these customizations could not be modeled flexible enough in the past. But this is no longer true with BW on HANA. With BW 740 SP8 we now can model kind of dimensional satellites of a BW entity using Advanced DSOs with Open ODS Views on top or directly in a CompositeProviders .Let me give you an example: you have all the standard SAP attributes in your 0COSTCENTER InfoObject. You have the requirement to model country-specific attributes let’s say for UK only. Today you store these attributes in an Advanced DSO and define an Open ODS View of type master on top of it. In any ODS View of type fact or in a CompositeProvider you can then associate/ join the different views of the entity cost center regardless whether they come from an InfoObject like 0COSTCENTER or an Open ODS views..
From my point of view, this will solve most modeling challenges customers had with such scenarios in the past: you load attributes with different ownership independently, you create new attributes without impacting the existing model, and you associate different attribute views and can even create dedicated authorizations.
Overall: I don’t believe that it makes sense to create data vaults for SAP ERP operational systems because it adds complexity, but no value. BW on HANA is pretty flexible to model volatility of SAP source models caused by customization. On the other hand if you have multiple, highly volatile non-SAP sources you are free to create a data vault DWH natively on SAP HANA The resulting architecture would then end up in a hybrid architecture between BW and a native HANA DWH.
This blog is the first half of the interview I conducted with Juergen Haupt. The second half will be posted shortly!
- SAP Managed Tags:
- BW (SAP Business Warehouse),
- SAP HANA
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
3 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
Cyber Security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 7 in Technology Blogs by SAP
- Partner-2-Partner Collaboration in Manufacturing in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 3 Interview in Technology Blogs by SAP
- Deliver Real-World Results with SAP Business AI: Q4 2023 & Q1 2024 Release Highlights in Technology Blogs by SAP
- Partner-2-partner collaboration in Higher Education Sector in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 9 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |