
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- Binary search on SAP DB sorted tables
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-23-2015
8:00 PM
Use index table key in your Select statement ! - this is very clear and correct advise ...unfortunately not always easy to achieve it !
Most often WM / SD / FI are the departaments which are in the top of transactions recorders . Their Docu Header Tables ( those which are ending in K – from german Kopf) is having the binom Docu Number – Date of creation available , and , in all cases Docu Number is index key ! Most of our sql queries will rely on a lot of different secondary key and for sure there will be a ‘Where date in [] ‘ .
My aim is to build a FM which must have as import parameters a table name , key field and date name field and export a min and max key field which can be used in a further selection . First I will test the logic on a single table using 2 routines . With help of your comments & advises I should be able to build the final version.
In example below I am trying to determine a minimum and a maximum document number range , based on a date range , which can be used in a Sql select directive in order to increase the performances .
In my scarce resources sandbox system , LTAK counts almost 2 mil records while LTAP around 10 mil .
Selecting from LTAK only based on LGNUM and BDATU is like watching a 3 legs dog walking ! Of course , LTAP is doing even worse (assuming that you won't use a inner join with LTAK or FAE )!
Trivial condition for binary search is to have an ascending sorted table , it means that document number must be generated by NUMBER_GET_NEXT which implies an entry in NRIV table for this specific number range.
LTAK is matching the case .
Binary search approach :
According to picture bellow we have to find all TANUM which are laying in a given date range ( s_datum ) in Selection-Screen and for a known LGORT .
My approach is to find a TANUM at left of s_datum-low and one at right of s_datum-high . Of course , first TANUM and last TANUM in LTAK table would fulfill it , but won't increase select performances , therefore , we have defined a delta (type i) and build 2 ranges based on it. Intersection between any of delta_date range and s_datum range should be the null set . The length (delta) of delta_date range must be defined in such a way to avoid a large number of iterations in order to find an entry inside of it . It is easy observable that the length and number of iterations are inversely proportional . A small delta would find a TANUM closer to one of the s_datum 's edges but the number of hits would increase , viceversa , a big delta would return in less iterations a TANUM which may not be too close to s_datum's edges .

Coding :
1 . Defining variabiles and selection-screen :
in structures gs_min_ltak and gs_max_ltak we are recording first and last entry in LTAK table ;
min_tanum and max_tanum structures will hold the found values for which we are looking for ;
delta_date is the range in which we will search for min_tanum and max_tanum ;
delta (type INT1/{0} ) is the legth of delta_date interval .
2 . Routine find_min_max_tanum_in_ltak is responsabile for binary search recursivity .
1st step would be to read extremities of table ( min and max tanum )
SELECT SINGLE * FROM ltak INTO gs_min_ltak WHERE lgnum = p_lgnum.
SELECT * FROM ltak UP TO 1 ROWS INTO gs_max_ltak WHERE lgnum = p_lgnum ORDER BY tanum DESCENDING.
ENDSELECT.
2nd , based on length of interval , we would determine a maximum number of failed iterations . ( generously i choose a max of 2 x (log base 2 of N ) where N is number of rec in LTAK ) .
max_iterations = 2 * log( gs_max_ltak-tanum - gs_min_ltak-tanum ) / log( 2 ) .
If number of failed iterations would be greater than an expected number of iterations , then we might consider the existence of noise in data distribution ( mass documents deletion , long period of time without records ..) or our delta value was setted up in such a way to find posted records during the weekend ( which may have a low value of probability density function for this interval).
3rd set_delta_date_range routine is responsabile for setting the boundaries of left and right intervals,where we have to find our records .
4th find_tanum routine is the recursive binary search routine .
Exemple of SAT measurement
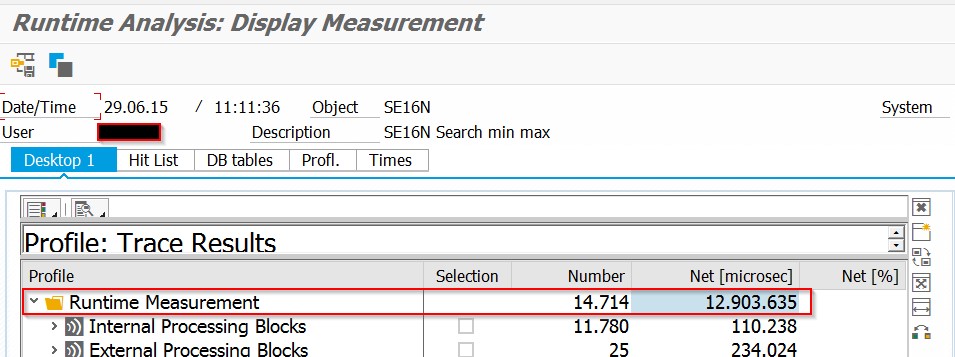
I have measured runtime of finding 1 record in LTAK table in a given period . It took almost 12 secondes .
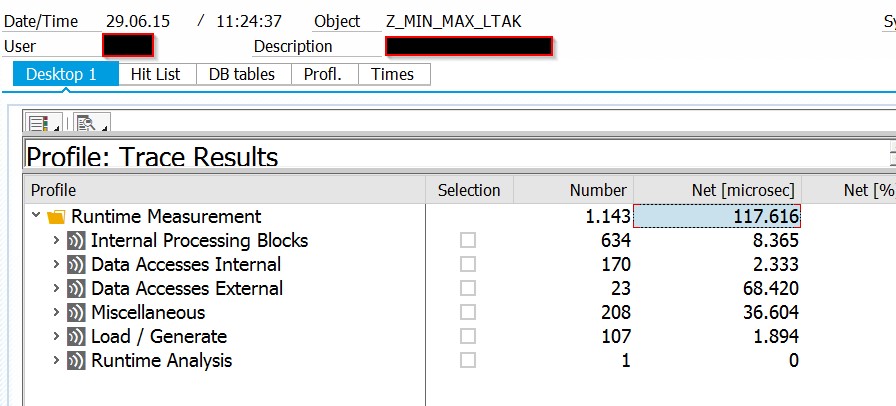
Same interogation was done in binary search in my Z report . It took 0,1 seconds to find 2 TANUMs (left and right of interval ) . Please see bellow results .
SAT - SE16N / LTAK Table

SAT - SE16N Measurement
SAT - Z_MIN_MAX_LTAK

SAT - Z_MIN_MAX_LTAK measurement
Z_MIN_MAX_LTAK output

*&---------------------------------------------------------------------*
*& Report Z_MIN_MAX_LTAK
*&
*&---------------------------------------------------------------------*
*&
*&
*&---------------------------------------------------------------------*
report z_min_max_ltak.
data : gs_min_ltak type ltak ,
gs_max_ltak type ltak.
data : min_tanum type ltak ,
max_tanum type ltak .
data : number_iterations type i,
target type string ,
lv_error type xflag.
data : delta_date type range of sy-datum with header line .
data max_iterations type i.
select-options : s_datum for sy-datum obligatory.
parameters : p_lgnum type lgnum default 'SVT' obligatory,
p_delta type int1 default 8 obligatory. " In my case 8 days are the maximum which can exists without records .
at selection-screen .
if s_datum-high is initial.
message e031(/iwbep/epm_product) with 'Date to '.
* &1 is mandatory
endif.
if p_delta = 0.
message e094(axt_model) with 'Delta'.
* Field &1: Enter a length greater than 0
endif.
start-of-selection .
perform find_min_max_tanum_in_ltak .
perform write.
*&---------------------------------------------------------------------*
*& Form FIND_MIN_MAX_TANUM_IN_LTAK
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
* --> p1 text
* <-- p2 text
*----------------------------------------------------------------------*
form find_min_max_tanum_in_ltak .
select single * from ltak into gs_min_ltak where lgnum = p_lgnum.
select * from ltak up to 1 rows into gs_max_ltak where lgnum = p_lgnum order by tanum descending.
endselect.
max_iterations = 2 * log( gs_max_ltak-tanum - gs_min_ltak-tanum ) / log( 2 ) .
if s_datum-low < gs_min_ltak-bdatu and s_datum-high < gs_min_ltak-bdatu.
message e048(ei).
* No data selected for this time period
elseif s_datum-low > gs_max_ltak-bdatu and s_datum-high > gs_max_ltak-bdatu .
message e048(ei).
* No data selected for this time period
endif.
if s_datum-low <= gs_min_ltak-bdatu .
min_tanum = gs_min_ltak.
else.
target = 'MIN' .
perform set_delta_date_range using target.
perform find_tanum using gs_min_ltak-tanum gs_max_ltak-tanum target.
endif.
if s_datum-high >= gs_max_ltak-bdatu.
max_tanum = gs_max_ltak.
else.
target = 'MAX'.
perform set_delta_date_range using target.
perform find_tanum using min_tanum-tanum gs_max_ltak-tanum target.
endif.
if lv_error is not initial.
message ' Too many iterations .Increase delta !' type 'E' display like 'E' .
endif.
endform. " FIND_MIN_MAX_TANUM_IN_LTAK
*&---------------------------------------------------------------------*
*& Form FIND_TANUM
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
* -->P_MIN text
* -->P_MAX text
* -->P_TARGET text
*----------------------------------------------------------------------*
form find_tanum using p_min type tanum
p_max type tanum
p_target type string.
data :temp_tanum type tanum ,
temp_ltak type ltak.
number_iterations = number_iterations + 1 .
temp_tanum = ( p_max - p_min ) / 2 + p_min .
select single * from ltak into temp_ltak where lgnum = p_lgnum and tanum = temp_tanum .
if sy-subrc <> 0.
select single * from ltak into temp_ltak where lgnum = p_lgnum and tanum > temp_tanum .
case p_target.
when 'MIN'.
perform find_tanum using temp_ltak-tanum p_max p_target.
when 'MAX'.
perform find_tanum using p_min temp_ltak-tanum p_target.
when others.
endcase.
else.
***********delta too small or too many gaps ( records are not uniform distributed)
if number_iterations > max_iterations . " Empty interval
case target.
when 'MIN'.
min_tanum-tanum = p_min.
lv_error = 'X'.
exit.
when 'MAX'.
max_tanum-tanum = p_max .
lv_error = 'X'.
exit.
when others.
endcase.
endif.
**********************************
if temp_ltak-bdatu in delta_date.
case target.
when 'MIN'.
min_tanum = temp_ltak.
exit.
when 'MAX'.
max_tanum = temp_ltak.
exit.
when others.
endcase.
elseif temp_ltak-bdatu < delta_date-low.
perform find_tanum using temp_ltak-tanum p_max target.
elseif temp_ltak-bdatu > delta_date-high .
perform find_tanum using p_min temp_ltak-tanum target.
endif.
endif.
endform. " FIND_TANUM
*&---------------------------------------------------------------------*
*& Form SET_DELTA_DATE_RANGE
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
* -->P_TARGET text
*----------------------------------------------------------------------*
form set_delta_date_range using p_target type string.
free delta_date.
case p_target.
when 'MIN'.
delta_date-low = s_datum-low - p_delta .
delta_date-high = s_datum-low - 1.
delta_date-sign = 'I'.
delta_date-option = 'BT'.
append delta_date.
when 'MAX'.
delta_date-low = s_datum-high + 1.
delta_date-high = s_datum-high + p_delta .
delta_date-sign = 'I'.
delta_date-option = 'BT'.
append delta_date.
when others.
endcase.
endform. " SET_DELTA_DATE_RANGE
*&---------------------------------------------------------------------*
*& Form WRITE
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
* --> p1 text
* <-- p2 text
*----------------------------------------------------------------------*
form write .
write :/ 'Our goal was to find a min TANUM and a max TANUM in LTAK table ,'.
write :/ 'positioned to the left of s_datum-low = ' ,s_datum-low , ' and to the right side of s_datum-high = ' ,s_datum-high , ' within a range (delta) of max ', p_delta centered, 'days.' .
skip.
write :/ 'Goal was achieved in a # of iterations = ' ,number_iterations no-zero left-justified , 'Number of max allowed iterations = ' , max_iterations.
write :/ 'Min TANUM= ' , min_tanum-tanum no-zero left-justified .
write :/ 'Min TANUM date = ' , min_tanum-bdatu left-justified.
write :/ 'Max TANUM= ' , max_tanum-tanum no-zero left-justified.
write :/ 'Max TANUM date ' , max_tanum-bdatu left-justified.
endform. " WRITE
- SAP Managed Tags:
- ABAP Development
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
2 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
6 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
IBM watsonx
1 -
Integration & Connectivity
9 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
12 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
14 -
User Experience
4
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 4 | |
| 3 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |