There are 2 types of dictionary customization on HANA according to different TA_RULEs -- LXP and Entity Extraction.
LXP refers to LINGANALYSIS_BASIC, LINGANYALYSIS_STEMS, LINGANALYSIS_FULL, while Entity Extraction refers to others.
About how to custom dictionary for Entity Extraction, you can refer to Wenjun's blog Greetings from SAP HANA in Chinese new year - customizing text analysis extraction.
Here we work on the dictionary customization for LXP of simplified-chinese简体中文 language on HANA SP09. For example, if your table content has the word '杀手锏', and you create the LINGANALYSIS_FULL fulltext index, you will find that this word is seperated into '杀手' and '锏'. So our purpose is to make HANA identify the new word '杀手锏'.
Step 1
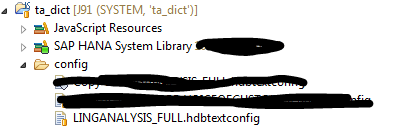
1.create .config file
Create a xs project and new folder "config", and create LINGANALYSIS_FULL.hdbtextconfig file in this folder
About the content of .hdbtextconfig file, please refer to chapter 3.3 Text Analysis Configuration File Syntax in guide http://help.sap.com/hana/SAP_HANA_Text_Analysis_Developer_Guide_en.pdf
The content below is somewhere you need to configure in this file:
<!-- Use custom linguistic dictionaries? (default is 'false') -->
<property name="EnableCustomDictionaries" type="boolean">
<boolean-value>true</boolean-value>
</property>
<!-- Determine whether stemming flavor is standard or expanded? (default is 'std') -->
<property name="VariantString" type="string">
<string-value>expanded</string-value>
</property>
After finish the content, activate this .hdbtextconfig file.
2.append your new words into custom dictionary
Find the custom dictionary under \usr\sap\XXX\SYS\global\hdb\custom\config\lexicon\lang\ on HANA server machine , filename is related to the value of VariantString in .hdbtextconfig file above. That is, if VariantString=expanded, filename is simplified-chinese-expanded.sample-cd; otherwise if the value is std, filename is simplified-chinese-std.sample-cd. These 2 files are the same except the filename.
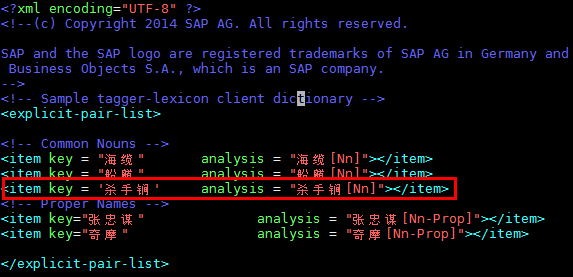
Remember after finish the custom dictionary, you must reactivate the .hdbtextconfig file again to bring this dictionary into effect.
3.create fulltext index
Here the path of my .hdbtextconfig is ta_dict.config in the repository. So in the SQL of create fulltext index, configuration is 'ta_dict.config::LINGANALYSIS_FULL'.
CREATE COLUMN TABLE "SEGMENTATION_TEST" (
"URL" VARCHAR(200),
"CONTENT" NCLOB,
"LANGU" VARCHAR(10),
PRIMARY KEY ("URL")
);
CREATE FULLTEXT INDEX ta.FT_INDEX
ON ta.SEGMENTATION_TEST(CONTENT) TEXT ANALYSIS
ON CONFIGURATION 'ta_dict.config::LINGANALYSIS_FULL'
LANGUAGE COLUMN "LANGU";
INSERT INTO ta."SEGMENTATION_TEST"(URL,CONTENT,LANGU)
VALUES('XXX.XXX.XXX','杀手锏','zh');
And then you check the content of the index table, you can find '杀手锏' is there.

Besides, only japanese, simplified-chinese, traditionaly-chinese and thai languages have the corresponding sample-cd file, so I guess other languages don't support this kind of dictionary customization. I try to do with english, and it doesn't work. But I doesn't work on other languages.
Any suggestion, please leave a message.
