
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hana Smart Data Integration - Realtime Sources wit...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-08-2015
3:16 PM
This post is part of an entire series
Hana Smart Data Integration - Overview
- Hana Smart Data Integration - Adapters
- Hana Smart Data Integration - Batch Dataflows
- Hana Smart Data Integration - Realtime Table Replication
- Hana Smart Data Integration - Realtime Sources with Transformations
- Hana Smart Data Integration - Realtime Sources with History Preserving
- Hana Smart Data Integration - Architecture
- Hana Smart Data Integration - Fun with Transformation Services
Another rather common scenario is to retain the history of the data throughout the loads. In short, build a slow changing dimension table of type 2. The idea is simple: We get changed rows from the source and whenever something interesting changed, we do not want to overwrite the old record but create a new version. As a result you can see the entire history of the record, how it was created initially, all the subsequent changes and maybe that it got deleted at the end.
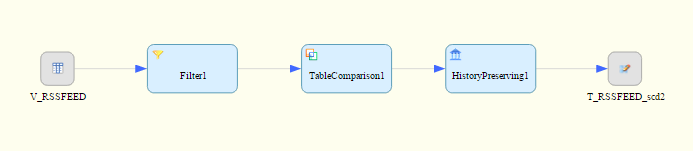
The dataflow
I want to use the RSS feed as realtime source again, but instead of simply updating each post, I want to see if corrections are made in the title. Granted, other source make more sense. More common would be to keep the history of the customer to correctly assign a sales order for this customer to the country the customer was living in at the time the sales order got created.
But since the principle is the same....
The flow is similar to the previous one, all source rows are compared with the target table, but then the result of the comparison is sent to the History Preserving transform and then loaded. (This time I am using the WebIDE, hence the screenshot looks different. But you can open and edit a .hdbflowgraph file with either one, even switch.)
In such a Slow Changing Dimension there are many options you can chose from, for example
- For a new record, what should its valid-from date be? You could argue that now() is the proper value, but maybe the source has a create timestamp of the record and this should be used?
- Does the source have a field we do not want to compare? Imagine for example we get the very same record a second time and all that changed in the publish date because the news article was re-published a second time. If that column was the only one that got changed, we do not even want to update the target row.
- Should the target table have a valid-from & valid-to date and/or a current-indicator? With the first we can see that version 1 of an entry was valid from create date to 11:05, a second version from 11:05 to 14:00. And with the current indicator we have a quick way to find the latest version of each record set.
- When do you want to create a new version, when just update the latest version? For example if the news title got changed we want to create history for, when the last_change_date is the only change, simply update the last version - no need for creating a new version just because of that.
- And then there are technical fields we need to tell, what is the primary key of the source, what the generated key and things like that.
Putting all of this into a single transform would make it very hard to understand. Instead the transforms work together in unison.
Preparing the data - Filter Transform
(1) In the Filter transform the source data is prepared and aligned to match the target table. In this case the source and target tables have the same columns, in name and datatype, only the target table has four additional fields: The surrogate key as the target will have multiple rows for one source record over the time; the valid from/to date and the current indicator column.
None of these columns are needed in the Filter transform as they will be dealt with in the Table Comparison and History Preserving transform. The sole exception is the VALID_FROM column, the transforms need to know the valid from value and that is set in this Filter transform. Hence I have added one more column and mapped it to "now()".

Comparing the data - Table Comparison Transform
(2) In the Table Comparison transform we deal with the question of what we want to compare. In this case we have columns like the URI - the primary key of the RSSFEED table, a title, a description and more.
The output of the Table Comparison transform is the structure of the selected compare(!) table, not the input structure. How would we know for example the SURROGATE_KEY of the row to update, else?

The first and most important setting are the columns to compare and to define what the logical primary key is.
Let's consider the column URI, the primary key of the source. This column should not only be compared, it is the key column for the comparison. In other words, the transform should execute something like "select * from compare_table where URI = Input.URI". Hence the URI column is not only added to the Compare Attributes but also marked as Primary Key=True.
All other columns are listed as Compare Attributes as well, hence the transform will compare the result of above "select * ..." column by column in order to find a change in the values. If all column values are identical, the transform will discard the row - no need to update a row that is current already.
The interesting part is what happens when one column is not part of the Compare Attribute list? Well, it is not compared but what does that mean in practice? Imagine the UPDATEDATE is not part of the list. If the transform find that the TITLE got changed, it will output the row. When the DESCRIPTION changed it will send the row. But if all values are the same only the UPDATEDATE column has a different value, the transform will consider that row is nothing-changed. Maybe somebody did open the row and saved it again without doing anything - all values are the same, only that UPDATECOLUMN is different.
For above to work a few obvious rules apply to the TC transform
- It is fine to have less input columns than the compare table has. These extra columns will be assumed to have not changed, hence the transform will output the current value of the compare/target table so that an updated will not modify the target table column value.
- It is not allowed to have input columns that do not exist in the compare/target table. The TC transforms compares the columns by name, it compares the URI input column with the URI column of the compare table, the AUTHOR with AUTHOR. If the source would have a column XYZ the transform does not know what to do with it. Hence you will find a filter transform upstream the TC transform often to prepare names and datatypes if needed.
- The input should have a primary key which truly is unique, else the transform does not know what to do. The transform will perform an outer join of the incoming data with the compare table and all rows where there is no match found in the compare table are marked as insert. If the input has two rows you will end up with two insert rows and either this results in a unique constraint violation in the target or you end up with two rows for the same logical primary key in the target.
- The target has to have the input primary key column as well, else above join does not work. This target column does not need to be the primary key, it does not even need to be unique. In that case you have to provide a hint however what row if the matching data set should be used - see below.
Above rules sound complex at first sight, but actually all of them are quite natural and what the user will do anyhow. But it helps to understand the logic in case of an error.
In our use case we have the problem that one URI returns potentially multiple matching rows from the compare table, all the various past versions. We need to specify which row to compare with.
We have two options for that, both are in the first tab. Either we filter the compare table or we specify a generated-key column.
The latter builds on the assumption that a surrogate key is always increasing, hence by specifying one, we tell the transform to compare with the higest one, that is the row that was inserted most recent.
The filter option would be to make the compare table appear as having the latest record only, e.g. by adding the filter condition CURRENT_INDICATOR='Y'. Assuming that there is only one current record per URI, that would work also, except for deletes. Deleted rows and not current, hence an incoming row would believe no such record was ever loaded before and mark it as brand new insert. So be careful when choosing this option.

Creating new versions, updating the old - the History Preserving Transform
The History Preserving transform gets all the information it needs from the Table Comparison transform, that is the new values from the input and the current values for all columns from the compare table and is using those to produce the output data.
In the most simple case, that is when neither a valid-from/to date is used nor a current indicator, all the transform does is comparing the new values with the current values for all columns listed in the Compare Attributes. If one or more is different, then it outputs an insert row with the new values and the table loader will insert that. If all these columns are the same and the input was an update row, it does send an update row. Insert rows are inserted.
If the input is a delete row, either a delete row is sent or in case the checkbox at the bottom called "Update Attribute on Deletion" is checked, an update is sent.
In case a valid-from/to column is used and/or a current flag, then the transform has to create a second row of type update to modify the current row in the target table. From the TC transform it knows the surrogate key of the compare row, it knows all the current values, hence it can update the row to the same values except for the valid-to-date and current-indicator, these should be changed to the new version's valid from date and the current indicator from 'Y' to 'N'.
Same thing happens for delete rows in case the "Update Attribute on Deletion" is set.

Generating the surrogate key - the Table Loader
The table loader should be a regular opcode writer, meaning its Writer Type option is left the default.
In the Sequence tab the surrogate key column is selected and the name of the Hana sequence to use is specified. This sequence has to exist already.
All rows that are inserted will get a new value in the surrogate key column, regardless of the input, but update/delete rows the surrogate key from the TC transform is used. That is the reason why the HP transform can output two rows, an insert for the new version and an update to alter the latest version currently in the target table. Both, insert and update, will have a surrogate key, e.g. SURROGATE_KEY=5, and therefore the update statement will look like "update table set current_ind='N', valid_to_date=...... where SURROGATE_KEY=5. But for the insert row, the 5 will be replaced by the sequence's next value.

Summary
A typical transformation is to retain history so we can query the data as if it was queried back then, something that is not possible with the source tables themselves - they do not contain history. The Hana time travel feature would be too expensive and is too limited as a generic method. Hence we need a transformation where we can define precisely what should trigger a history record, what should be just updated.
All of these setting can be made in the individual transforms and together they allow to build all variants of Slow Changing Dimensions Type 2.
- SAP Managed Tags:
- SAP HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- New webcast series on “SAP BTP DevOps and Observability in Action” in Technology Blogs by SAP
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Handling Mail Attachments in SAP Process Orchestration and SAP Cloud Integration in Technology Blogs by SAP
- SAP Inside Track Bangalore 2024: FEDML Reference Architecture for Hyperscalers and SAP Datasphere in Technology Blogs by SAP
- SAP Datasphere with Confluent --> Part 2 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |