
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Using Custom Dictionaries with Text Analysis in HA...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-25-2015
3:17 PM
Having done some work with the unstructured text engine within the SAP HANA Platform I wanted to capture and share how to do this. For this example I have used Twitter data looking at Formula One hashtags and F1 accounts.
The linguistic engine is just one of the engines in the HANA Platform but is not often talked about but it is very easy to use to extract structured information from unstructured text. This text could be held in a simple character field or it could be within a binary document, we support many binary formats including TXT, RTF, HTML, PDF, DOC, DOCX, XLS, XLSX, PPT, PPTX and MSG. The official Text Analysis, Text Search and Text Mining documentation can be found here and here.
To check the supported binary file formats you can query the system table M_TEXT_ANALYSIS_MIME_TYPES.
SELECT * FROM "PUBLIC"."M_TEXT_ANALYSIS_MIME_TYPES" For this example I have used the Text Analysis (TA) engine straight out of the box and yes it works, the results were OK, but as you would expect with any Industry, Line of Business or sport F1 has its own terms, the drivers and teams(constructors) being prime example of these so I wanted to create a custom dictionary to improve the understanding of these.
There's a good blog that shows the old way (HANA SP7) of doing this SAP HANA Custom Dictionary
With HANA 1.0 SP9, this is even easier, there's only really 3 steps.
- Create the XML dictionary
- Reference the dictionary in a TA configuration file
- Call the Text Analysis Configuration with SQL
1.1 HANA Web Development Workbench
Go to the HANA Web-based Development Workbench Editor, for me this is at
http://ukhana.mo.sap.corp:8001/sap/hana/ide/editor/
For others it would be
http(s)://<HANA HOSTNAME>:80<HANA INSTANCE>/sap/hana/ide/editor/

1.2 Create Dictionary File
Create a New "File" for the dictionary, I used the path sap.hana.ta.config
The file needs to end in .hdbtextdict, for later versions of HANA the file should reside within the content path sap.hana.ta.dict

1.3 Create the dictionary
Here's a snippet of mine, I have attached the full XML file below. Check your XML file opens in a web browser, also be careful of the double quotes " - sometimes you may find the "smart quotes" like “ and ” which are not smart for XML files!
<?xml version="1.0" encoding="UTF-8"?>
<dictionary xmlns="http://www.sap.com/ta/4.0">
<entity_category name="F1 Driver">
<entity_name standard_form="Lewis Hamilton">
<variant name ="Lewis"/>
<variant name ="Hamilton"/>
<variant name ="HAM"/>
<variant name ="@LewisHamilton"/>
<variant name ="#TeamLH"/>
<variant name ="LewisHamilton"/>
</entity_name>
<entity_name standard_form="Jenson Button">
<variant name ="Jenson"/>
<variant name ="Button"/>
<variant name ="#JB22"/>
<variant name ="@JensonButton"/>
<variant name ="JensonButton"/>
</entity_name>
<entity_name standard_form="Kimi Raikkonen">
<variant name ="Kimi"/>
<variant name ="Raikkonen"/>
<variant name ="Kimi Räikkönen"/>
<variant name ="Räikkönen"/>
<variant name ="Ferrari Kimi Raikkonen"/>
</entity_name>
</entity_category>
</dictionary>Full details of the dictionary syntax can be found here
Below you can see the full Dictionary XML file inside the HANA Web-based Development Workbench.
Once you click Save you should see in the black console as below that it gets saved and activated (compiled auto-magically) immediately.

2.1 Create configuration file
The easiest way is to chose one if the other .hdbtextconfig file that you see. Whichever one is the most appropriate.
This can be done easily - Right click copy and paste. I chose the VOICEOFCUSTOMER one as I was initially using some Twitter data for the unstructured analysis. Give the new file a sensible name, remember to keep the .hdbtextconfig extension.
2.2 Edit Configuration file
Open your newly copied file and scroll to the bottom.
Add, an entry that references your Dictionary file you created above for me I added
<string-list-value>sap.hana.ta.dict::F1.hdbtextdict</string-list-value>2.3 Save configuration file
You should see it also activates at the same time, which will check for any errors too.

3.1 Database Table
You can now use your new configuration. I loaded some Twitter data using the HANA Data Provisioning Agent that's also part of HANA SP9. I created a simple table F1-TWEETS with 3 columns, It must have a primary key and also a text field in either an NVARCHAR, VARCHAR, BLOB or CLOB

INSERT INTO "F1-TWEETS" (
SELECT "Id", "ScreenName", "Tweet" FROM "F1"."F1HANA-Twitter_Status");
3.2 Create FullText index with the new configuration
CREATE FULLTEXT INDEX "F1-TWEETS-FTI" ON "F1"."F1-TWEETS"("Tweet")
CONFIGURATION 'F1'
FAST PREPROCESS OFF
TEXT ANALYSIS ON;This creates a new table in my case $TA_F1-TWEETS-FTI which contains the structured version of the unstructured data.
When you use a dictionary the TA_NORMALIZED column is populated enhanced definitions that you have defined in the custom dictionary.
3.3 Visualisation of the Restults
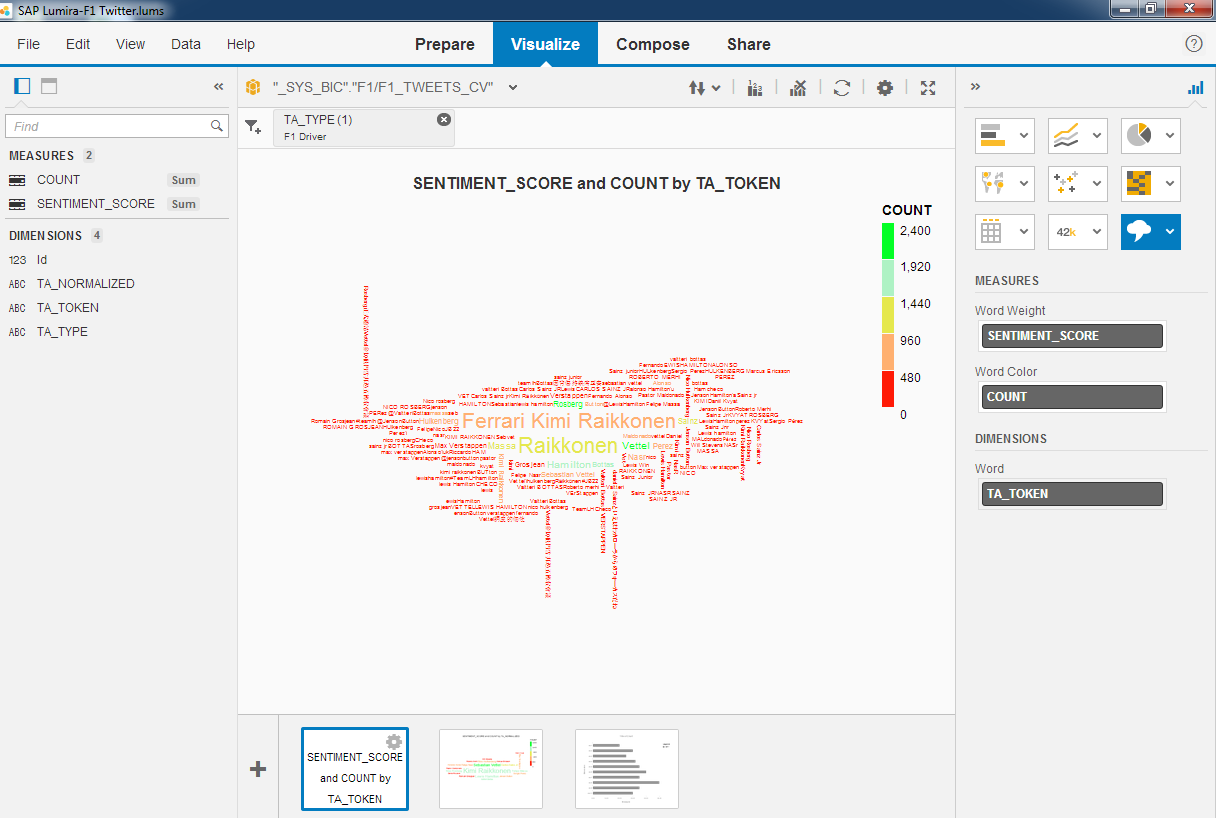
To illustrate the difference that the dictionary makes compare the 2 visualisations that I created with Lumira using a calculation view against the $TA_F1-TWEETS-FTI table.
Without the Dictionary - TA_TOKEN

With the Dictionary - TA_NORMALIZED
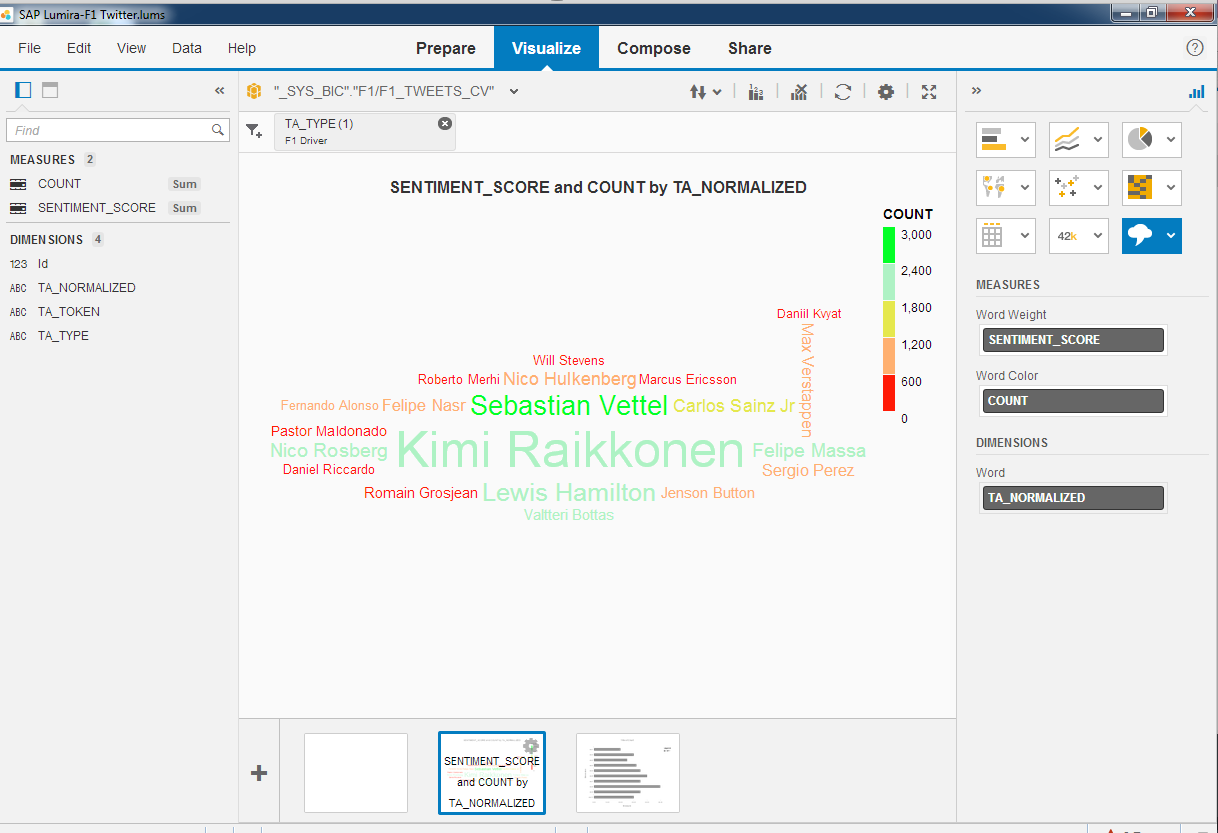

For me, it is clear that there's enormous benefit to using the Text Analysis to turn unstructured data into meaning information and when you combine that with the custom dictionaries you have a very powerful tool.
- SAP Managed Tags:
- SAP Lumira,
- SAP HANA,
- SAP Text Analysis
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- SAP Partners unleash Business AI potential at global Hack2Build in Technology Blogs by SAP
- Analyze Expensive ABAP Workload in the Cloud with Work Process Sampling in Technology Blogs by SAP
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |