
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- You Can Only Manage What You Can Measure – The Tec...
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-20-2015
9:47 PM
By Bert Schulze and Ingo Sauerzapf
The subscription economy is all about usage and consumption. The expected agility and innovation cycles are at an unprecedented pace of change. Customers today are looking for ways how to transform their business to cater to our digitized, networked, and complex world.
In this chapter of the blog series we want to have a look at the technical part and what it would take to stand up an infrastructure and a service that would allow you to start measuring and serve the use cases, customers have today when it comes to subscription services.
Part 1 The Subscription Economy
Part 2 Every Day and Cloud and Networked Day
Choosing the right components with the use case in mind
All too often, I hear people saying: "We have this software, now let´s find a problem to solve." I believe this at best results in mediocre solutions, as you’re trying to squeeze the problem you find into the software you already chose, regardless of efficiency and effectiveness. As a software company, you will naturally gravitate toward building a service made out of your own software components.
Choosing the right components starts with the business view and ends with the business view - with technology in between as an enabler and facilitator.
Starting with technology will limit you. Instead start follow an approach that dissects a problem into its core components, work out which features a component needs to contribute as part of the overall clockwork and finally start to look for software that makes it all work.
Building core functionality from scratch is very hard and carries a high level of risk. This is especially true with the growing availability of viable open source alternatives. Primarily because many companies nowadays understand that it is better to collaborate on core components and leverage the collective genius instead of try to solve the problem on their own.
We therefore follow a simple approach:
1. Understand what I need for a core component
2. Try to find a solution within SAP
3. If not available, search for an open source project that solves the problem
Acquisition Of Information
Direct streaming of records from the application should be the preferred way of sending data. Typically this calls for libraries embedded into your application. That said we have to recognize that existing applications already create valuable information. That is typically stored either on the local file system or in proprietary ways. An infrastructure should therefore offer either the ability to deploy functionality that attaches itself to these files or local OS functionality to transport records to the service. In cases where a local library cannot be embedded, the service should offer standard interfaces for receiving records. Nowadays it is common sense to do this via either Web Socket or HTTP/REST and asynchronous calls.
With SAP software, a typical scenario for such interfaces would be clickstream capabilities built into SAP Fiori or requests sent directly in ABAP. It is worth noting, though, that implementing streaming capabilities in ABAP would result in kernel add-ons. This would make it very inflexible and it could only be extendable by the group responsible for
kernel development.
There are many different open source implementations available, including Fluentd, Logstash and Apache Flume. All of them come with a large number of inputs and outputs, and they are all easily extendable to handle data from proprietary sources. On top, Platform-as-a-Service frameworks such as Cloud Foundry typically come with their own implementations that can be the source that the service needs to collect data from.
The concept explained above deals with data coming from a running application server. Modern desktop UI technology and mobile applications, however, also have data that needs to be collected. A collection service would therefore not be complete without supporting clickstream and web analytics. A way to receive these kinds of messages also has to be put in place, just as much as gathering information from the application server directly, and it will ideally be built on top of an established API. PIWIK is one such established API that comes to mind here.
Decoupling Producers From Consumers
Now that we have covered the receiving end of collecting records, we need to look at the ability to scale receiving agents without having to scale all subsequent systems in the data pipeline. The typical functionality that is employed to solve this problem is a traditional message bus. Given that the architecture has to scale along with the number of producers sending records, we are looking for a message bus that has a scale-out distributed architecture with resilience to data loss, and that can dynamically scale and can do in-order delivery of messages to consumers.
Message queues like Rabbit MQ would be natural choices with quite good throughput, but they typically lack in-order delivery. Recently new types of systems have come up that take the qualities of a message bus but allow for in-order delivery with lower delivery guarantees over a traditional message bus. Apache Kafka is the most prominent one today, and it is well suited for this service if distribution into multiple data storage solutions is the primary objective.
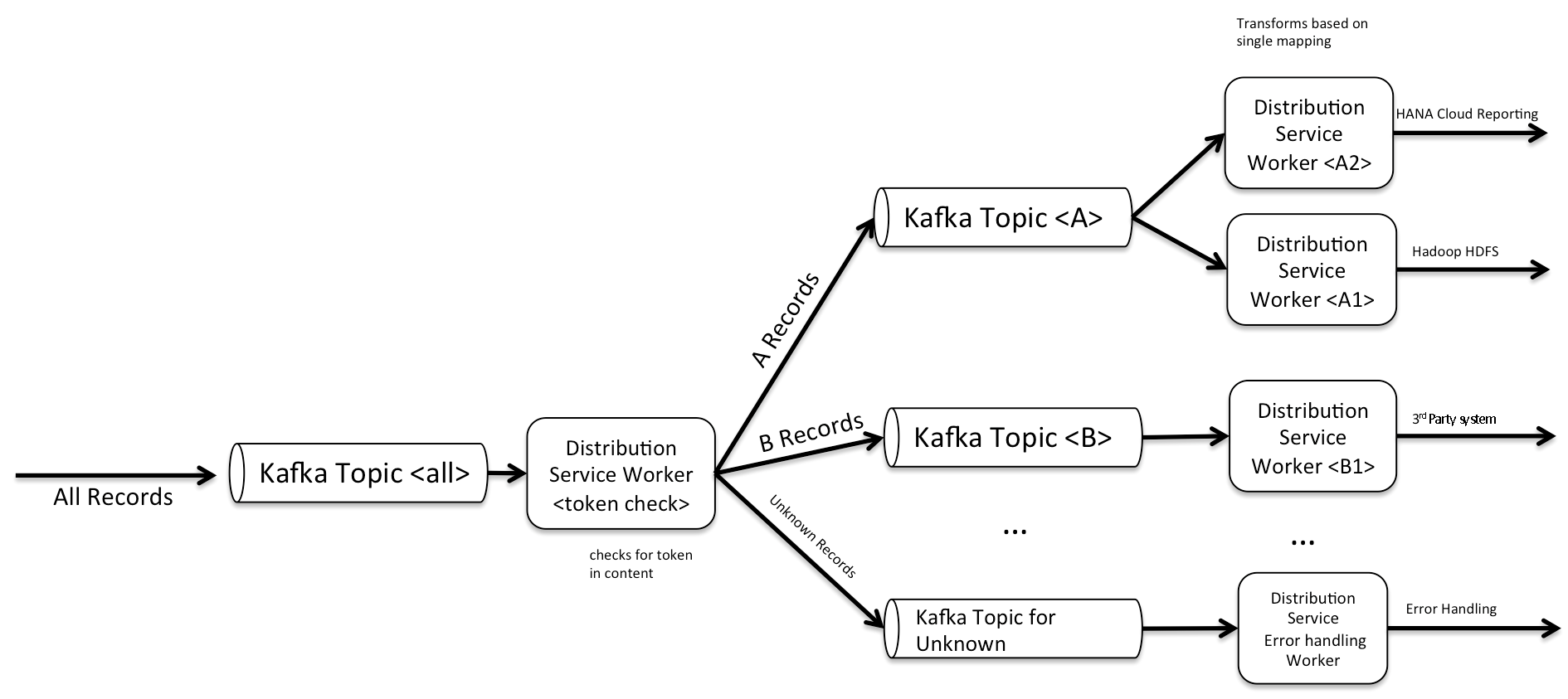
Distributing Messages
Once records are residing in the message bus, it is up to consumers to connect either permanently via streaming or in scheduled intervals
to read the new messages. Depending on the message content, distributors will then take action by making use of rules, mappings, aggregation algorithms or simple trigger settings. While the distribution service doesn’t necessarily have to scale to the volume of incoming records as it is shielded by the message
bus, it is still a primary objective to build it in a distributed fashion to allow for scale and fault tolerance. One primary requirement, therefore, is that the
service has the ability to connect many consumers consuming records of the same type to a single message bus, while allowing individual messages of different types to be sent to only one.
The Distribution Service is at the heart of the system as it knows all the senders, incoming types of messages, rules to distribute, models of schema based data stores and whatever else is necessary to be stored. As a baseline for a distribution service, one can again leverage many open source components and start building it from there. As the most robust libraries for Kafka, Hana and Spark are built in Java, it would naturally make sense to look for additional components needed that are also built in Java. Apache Flume seems to be a promising basis for this functionality, as it is built in Java and has configurable Kafka and HDFS read and write capabilities. It can also easily be extended to SAP Hana via the Hana JDBC driver. Furthermore, it is one of the components used by Cloudera’s Kafka Reference Architecture. The combination of Kafka and Flume now allows for a variety of configurations in which Kafka Topics and Flume processes can be chained together to build a sophisticated data distribution network. Such a network would have the ability to alter the messages as needed before storing them in one or multiple data stores like SAP HANA and HDFS.
Storing records
With collection and distribution mechanisms in place that allow for the decoupling of persistency from the applications that are sending the data, the service has full freedom to store the data based on relevance and price per storage for the individual records. The primary objective of the service is to store each individual record and to not throw away any collectable data point along the way.
Hadoop clusters have proven to be the most cost effective solution while maintaining the capability to easily query the data. That said, aggregates of data or individual data points are, for fast access and analysis, better kept in a data store like SAP HANA where warehousing models can be built on top and a vast selection of analytical toolsets already exist to present the data. In order to build meaningful analytics from the large number of collected records, information has to be available that can be used to build dimensions or simply aid in the query process.
Even more simply, it can be used to enrich reporting with human readable text instead of cryptic id’s. Most of the time, this additional data is coming from transactional systems like SAP ERP, CRM etc. where it is kept in a relational form. Keeping it in SAP HANA is therefore a more natural fit.
One crucial point in storing records, however, will be the question of what to do when queries are made that span multiple data stores. Today we are starting to see the first capabilities that allow querying of a Hadoop Cluster from HANA. We will, however, also need the capability for queries to be initiated in Hadoop that traverse to SAP HANA and back. Such a seamless interaction between data stores will broaden the analysis toolset even further, allowing for deeper analysis of the collected data.
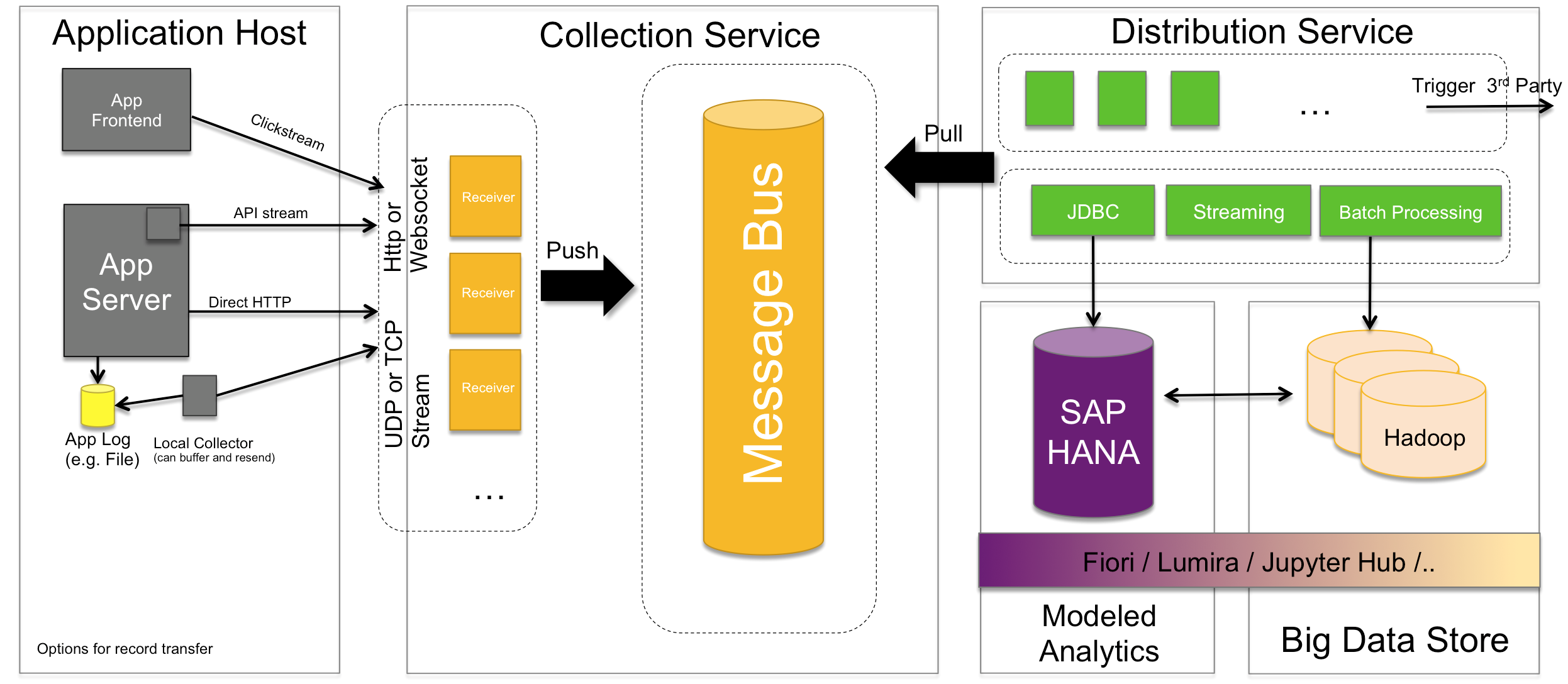
Technical boundaries of the infrastructure
At the front is the Collection Service, which is responsible for publishing end-points that applications can send data to and scale along with the incoming load. It also has a component that shields the services behind it from that load. The Distribution Service takes on the data, determines what needs to happen to it and where it should be stored. Functionality can range from enriching data to modifying records or creating aggregates from the raw data send. Behind the Distribution Service are multiple storage solutions. On top of these data stores there will be an analytical toolset that can interact between the data stores to build analytics visualizations of different kinds to fulfill customer´s need as described in the 1st blog of the series.
If done right, you are now ready for scale.
Let us know your thoughts here and follow on (@BeSchulze) and on LinkedIn
- SAP Managed Tags:
- SAP S/4HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
20 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
23 -
Expert Insights
114 -
Expert Insights
150 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
415 -
Life at SAP
2 -
Product Updates
4,687 -
Product Updates
202 -
Roadmap and Strategy
1 -
Technology Updates
1,502 -
Technology Updates
85
Related Content
- The Role of SAP Business AI in the Chemical Industry. Overview in Enterprise Resource Planning Blogs by SAP
- Business Rule Framework Plus(BRF+) in Enterprise Resource Planning Blogs by Members
- SAP ERP Functionality for EDI Processing: UoMs Determination for Inbound Orders in Enterprise Resource Planning Blogs by Members
- Deep Dive into SAP Build Process Automation with SAP S/4HANA Cloud Public Edition - Retail in Enterprise Resource Planning Blogs by SAP
- SAP Fiori for SAP S/4HANA - Technical Catalog Migration – Why and Getting Ready for Migration in Enterprise Resource Planning Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 |