
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- 最优化Web Intelligence报表性能的技巧
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member21
Discoverer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-12-2015
6:33 AM
原文地址(英语):http://scn.sap.com/docs/DOC-58571
作者:jonathan.brown 现就职于SAP
最优化Web Intelligence报表性能的技巧
免责声明-本文本仍在编辑中,每次更新一个章节。请追阅、设置书签及更新提示以保证您能及时了解任何变动。
这是个动态文件,我们诚挚期待您的反馈及分享您的使用技巧。您可以通过留言或私信的方式,告知我们任何您想看到的、更改的、删除的内容。
文档更新详情:
| Date | Who | What |
|---|---|---|
| 12-18-2014 | Jonathan Brown | 在关于系统设置的部分,加入能够连接到Ted Ueda的文章的链接 |
| 12-15-2014 | Jonathan Brown | 完成了第六章 |
| 12-09-2014 | Jonathan Brown | 开始了第六章的写作 |
| 12-01-2014 | Jonathan Brown | 根据Matthew Shaw在评论中的建议,加入了一些关于关闭缓存的建议 |
| 11-14-2014 | Jonathan Brown | 完成了第五章 |
| 11-07-2014 | Jonathan Brown | 完成第四章,更新了原文 |
| 10-31-2014 | Jonathan Brown | 开始第四章的写作 |
| 10-24-2014 | Jonathan Brown | 添加了Tips 3.7 - 3.9 ,完成了第三章 |
| 10-22-2014 | Jonathan Brown | 添加了 Tips 3.5 和3.6 |
| 10-17-2014 | Jonathan Brown | 开始了第三章的写作,添加了TIPS 3.1 - 3.4 |
| 10-15-2014 | Jonathan Brown | 更新了关于和 SCN DOC http://scn.sap.com/docs/DOC-58532中重叠部分的讨论 |
| 10-09-2014 | Jonathan Brown | 完成了第二章 - 对格式问题进行完善 |
| 10-08-2014 | Jonathan Brown | 开始了第二章的写作 |
| 10-02-2014 | Jonathan Brown | 对格式做了细微调整,添加了一些链接 |
| 10-01-2014 | Jonathan Brown | 文本架构以及第一章- 客户端性能 |
简介
本文档将成为webi以及性能相关的指导手册。作为动态文本,本文将实时囊括最新的使用技巧、窍门及最优性能。我们欢迎您对本文内容提出宝贵意见及指出不适之处。愿我们同心协力,保证本文的正确性。
请自由设置书签、接收更新提示邮件。我期待您关于本文的任何反馈,所以不必有任何顾虑,请通过留言、私信或类似的方式联系我。评价下文本的质量并
反馈给我。
我是本文的作者,但文中所涵盖的技巧来源广泛。大部门内容来自SAP产品技术支持部门及SAP开发团队。一些来自于SAP 论坛的分享及类似网站。
本文志在使大家了解现存问题、解决方案及最优性能,以提高当前硬件的吞吐量,提升最终用户/ 客户的体验,节约报告设计/耗损的时间及资金。
这一想法来源于2014.9 月在美国举行的一次SAP用户会议。那次会议不仅催发了本文的形成,还孕育了另一个高质量的最优性能文档,
您可以通过这个链接查看 :Best Practices for Web Intelligence Report Design
链接文章着重于Webi 的性能,该最优性能指导文本大体上涵盖了高质量的Webi最优操作。因与本文皆出自 ASUG 用户会议报告,故两者有许多重合之处。
2014 ASUG 会议Webi 报告链接如下:2014 ASUG SAP Analytics & BusinessObjects Conference - Webi
第一章-客户端性能
提高客户端性能的技巧涵盖了能够影响到客户端机器的每一个具体部分。包括HTML,Applet,胖客户端接口,以及浏览器等。
TIP 1.1-使用HTML接口来加快查看/刷新报表的速度
HTML接口是一个轻薄的客户端查看工具。它是运用HTML来展现和编辑Webi报表。由于它只需要展现和收集HTML,对于想要在浏览器中
快速查看和刷新报表的客户来说是一个很好的选择。
HTML接口和Applet接口相比少了一些功能,您需要在系统性能和功能之间做权衡。
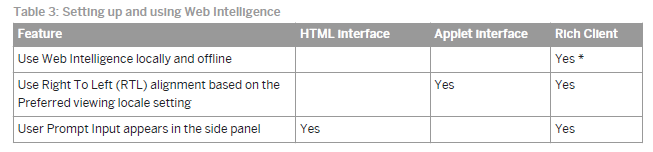
Webi用户手册的1.4章节对HTML,Applet还有胖客户端的接口进行了讲解。回顾这章能够帮助你确定是否HTML接口你能满足你的所有需求。
这里是手册中关于功能比较的部分截图:
下面是能够连接到我们的support portal上面Web Intelligence文档的链接。可以到最终用户手册的部分来找到Webi用户手册的最新版本。
PORTAL - SAP BusinessObjects Web Intelligence 4.1 – SAP Help Portal Page
下面还有一个直接连接到BI4.1SP04的链接。(目前大多数都使用这个版本)
GUIDE - BI 4.1 SP04 Web Intelligence User Guide - Direct Link
TIP 1.2-升级到BI4.1SP03或以上版本来使用有单独JAR文件的Applet接口
BI4.x为Applet接口介绍了一种新的架构叫做aka Java Report Panel/Java Viewer.之前的版本中使用的是叫做ThinCadenza.jar的一个单独的JAR文件。
BI4.0以及BI4.1早些的版本将这个架构分成了60多个jar文件。这样做是为了便于最初的维护和部署,但是java后续的更新却让此结构变得更加繁琐。
Java默认的强制性安全更新和限制使得这个新架构的性能在多数情况下变得很慢。
BI4.1SP03及其以上的版本恢复了采用单独.jap文件来部署。由于减少了在每个.jar文件中关于安全性和有效性的检查,这将会提高在客户端的性能。
下面是关于这个改变的What's new 手册。虽然这一点的改变最终用户应该是看不到的。但是这可能会提高性能。
GUIDE - BI 4.1 What's New Guide - Section 4.5
下面的KBA也在有限程度上涵盖了这个问题:
TIP 1.3 – 确保在线证书撤销检查没有使Applet接口减慢
在较新版本的Java Runtime Engine(JRE)中,在线证书撤回检查是被默认开启的。这个的主要作用是告诉客户端的JRE到在线的服务器上验证applet jar文件所签署的证书。在网络较慢的情况下,这将会花费很长的时间。
较旧版本的JRE没有将这个功能默认开启,所以不存在这样的问题。
因为BI4.x有60多个文件来加载Applet,这可能会占用更长的时间来对这60多个文件进行检查。在网络环境较慢的情况下,这可能相当于几分钟的延迟。
我在下面的Wiki和KBA中,对这个问题做了更加详细的阐述:
WIKI - Tips for Fine Tuning Performance for the Webi Applet
.
TIP 1.4 – 确保JRE客户端的缓存功能是正常运行的
当我们调查解决客户端JRE的性能问题时,首先需要检查的一项就是JRE的缓存功能是有效并且正常运行的。我们遇到过许多关于性能方面的问题都发生在缓存功能是无效的、设置不正确、或者因为某些系统和部署问题导致缓存功能无法正常运行。
其中一个例子是在一个Citrix的部署中。由于每个用户都可能有一个独特的、动态的“用户”文件夹,所以每个任务的缓存不可能一直保留。将缓存设置在一个公用的、可以永久保存的地方可能会解决这方面带来的性能问题。
在下面的Wiki中,我们还发现了更多关于怎样使JRE缓存生效的信息:
WIKI - Tips for Fine Tuning Performance for the Webi Applet
TIP 1.5 – 确保没有陷入已知的JRE安全性改变的问题
Java安全性更新和改变引起了许多Applet接口的问题。这些已知的问题已经被很好的总结记录并且可以在下面的Wiki找到:
WIKI - Web Intelligence and Oracle Java Runtime Engine Known Issues
针对XI3.1和BI4.x的不同版本,Wiki对这个问题做了分别的阐述。
这个link可以直接进入BI 4.0 和 BI 4.1已知问题的界面
虽然这些不是技术性能上的问题,但是他们也会增加用户体验时间,而且会在查看、编辑和刷新报表和实例上面导致延迟。
SAP只在每几个月发布新的Patch或者Support Packs,所以当Oracle安全性改变有了更新,有时在我们发布新的patch来修复这个改变之前会发生一些延迟。
所以当对您的客户端实行了Oracle JRE的最新更新时,不要忘记本节讲述的如何提高性能的方式。
TIP 1.6 – 选择正确的客户端- Webi胖客户端/HTML接口/Applet接口
每个接口都有利有弊。为Web Intelligence选择一个合适接口其实是在功能、性能、以及方便性方面做一个平衡取舍。
在Webi用户手册的1.4章节中,包含了对各个接口的不同点的阐述。阅读和理解这一章节,可以帮助您决定应该使用哪一个接口更为合适。尽管在任何一个接口的选择上并没有标准化的规定。一些用户喜欢用HTML接口来看报表,但是更喜欢用胖客户端来创建和编辑报表。这完全由用户自己的选择使用来决定。
您可以通过下面的Portal上的链接来找到最新的Webi用户手册。第1.4章节有对于各个接口不同点的阐述。
PORTAL - SAP BusinessObjects Web Intelligence 4.1 – SAP Help Portal Page
下面是直接连到BI4.1SP04版本的Webi用户手册链接。
GUIDE - BI 4.1 SP04 Web Intelligence User Guide - Direct Link
作为一般性的指南,我们对每个接口做了以下的用户推荐:
Webi HTML接口:
- 对于在大多数情况下只是运行初步设计的报表以及只做一些轻微改动的用户来说,这是最好的选择。
- HTML接口用64位的后端服务器,但是与Applet接口相比,缺乏了一些设计功能。
Webi Applet接口:
- 对于创建、修改、并且对报表和数据做高级分析的报表设计者以及超级用户来说,这个接口是最好的选择。
- 此接口利用64位的后端服务器,通常可以处理大数据量和大量的运算。
- 由于这是一个网络应用,所以当一个任务停滞一段时间或者执行了很长的操作时会发生超时暂停的问题。
Webi胖客户端接口:
- 这个接口几乎含有Applet接口的全部功能特色,同时还加入了一些自己的特点。这个接口应该被那些希望给大数据量的报表提供一个稳定的设计环境的高级报表设计者和超级用户使用。
- 可以用本地的数据源来设计报表,还可以使用一些桌面类型的数据源,例如Excel和Access。
- 同时还可以用三层结构的模式来利用后端服务器进行数据检索
第二章- 流程的最优实践
当我们谈到“流程”的最优实践时,我们其实是在说如何在我们的业务流程中使用Web Intelligence报表。
这章将会包含许多的最优实践方式,能够帮助您建立一个良好的业务流程来处理Webi报表。
下面就让我们开始吧!
TIP 2.1 – 计划报表来节省时间和资源
这个看起来很简单,但是我们确实看到许许多多的incident可以通过一个简单计划报表和按需查看的方式就可以避免发生。
按照最优实践方式,执行计划的临界值应该是五分钟。如果一个报表要花费五分钟以上的时间来刷新,那么这个报表就应该执行计划。
计划可以让一个用户或者管理员将执行报表的任务交给后台的服务器,这样他们就不用一直坐等报表执行结束。
计划报表的好处:
- 降低正确实施时的用户等待时间
- 可以将正在处理的内容放到到非高峰时间执行
- 减少并发请求
- 减少在高峰时段对数据库的影响
- 可以结合实例与报表链接,产生更小、速度更快的文件
研究表明,在当今世界上,用户不大可能等待5秒以上的时间让视频加载。例如,如果你是在YouTube上,点击播放按钮,你会等待5分钟让视频加载然后开始播放吗?我想大多数人会放弃或约10-20秒后,尝试再次刷新视频。
这也适用于Web应用程序的用户。如果报表没有在一两分钟之内查看到,用户很可能会关闭请求再试一次,或干脆放弃。再次提交请求的危险是,他们这样做时使用了更多后端服务器上的资源。这里有一个工作流程为例:
1、用户A登录到BI启动板并导航到“Monster Finance Report”的报表
2、用户A查看这份文件并单击刷新按钮来获得的最新数据
3、约2分钟后,用户A不知道是怎么回事,该报告似乎仍在被刷新,但鉴于用户A是个急性子,他怀疑刷新被“挂起”了,于是关闭浏览器。
4、用户A决定来碰碰运气并再次提交申请。这实质上造成对相同数据的新请求,而且这两个请求具有潜在的冲突,因为它们争夺BI服务器和数据库端上的资源。
5、又过了几分钟后,用户A放弃。与此同时,他并不知道他在后台浪费的资源和时间。
上述情况会带来一些不好的影响:
- 用户A一直没有得到他的报告,而且还有一个不好的用户体验
- 后端资源在没有得到任何有用的结果的情况下被浪费了
这两个本来是可以通过正确使用计划来避免的。
下面是关于如何最好地利用计划的一些技巧:
1、让你的用户将任何需要5分钟以上时间运行的报表进行计划。
2、鼓励用户在全天非高峰时段将他们知道需要用的报表提前进行计划。
3、将报表计划成用户将要用到的各种格式,例如Excel,文本或PDF格式。这可以节省白天的时间和资源
4、当多个用户对同一文件有不同要求时,可以使用publications。
想了解更多关于Schedule Objects和Publications的信息,请参照下面的链接:
DOC - BI 4.1 SP4 BI Launchpad User Guide - Chapter 7 - Scheduling Objects
.
DOC - BI 4.1 SP4 BI Launchpad User Guide - Chapter 10-11 - Publications
.
TIP 2.2 – 在计划自动运行重试时使用重试选项
虽然这不是一个关于性能的技巧,我发现它和计划一样是最佳实践方式。我常常很惊奇地发现有好多人不知道计划(只在CMC)对话框中的重试功能。此功能允许您配置在计划的实例发生故障时,您想在X秒之后尝试X次重试的这个X参数的设定。
下图是BI4.1中的这个选项:

这个技巧可以在计划由于数据库问题或者BI平台资源问题导致失败时,节省您寻找失败计划以及重新手动计划报表的时间。间歇性故障通常和过程中某处的资源相关,所以简单的设置相隔几分钟重试一次可以帮助限制在忙碌环境中真正失败的次数。
此选项可在计划对话框的默认设置/重现部分或计划/重现部分进行设置。两者之间的区别在于,默认设置选项将对任何失败的计划进行重试值的设置。在计划部分的设置只是针对一些特别的计划。
注:需要注意的是此选项仅在CMC中存在,目前还不能通过BI启动板实现。
TIP 2.3 – 使用实例限制来帮助减少您环境中实例的数量
这是另一种很少被知道的功能,你可以用它来帮助提高系统的性能。该功能被称为实例限制,你可以在一个文件夹或对象层次来设置它。
基本概念是,你可以对一个文件夹或者对象上保存的实例数量进行限制。如果超出限制,则CMS将清理最老的实例,以帮助减少存储在CMS数据库和文件存储磁盘上的元数据和资源量。
下面是在CMC帮助指南中找到的关于如何启用并设定限制的基本说明:
设置限制可以自动删除BI平台的报表实例。您在一个文件夹设置的限制影响文件夹中的所有对象。
在文件夹级别,您可以设置限制如下:
- 每个对象,用户或用户组的实例数
- 一个用户或一个组保留实例的天数
在CMC中设置实例限制的步骤:
- 进入CMC的文件夹管理区域。
- 找到并选择要为其设置限制的文件夹,并选择操作/限制。
- 在限制对话框中,选择删除多余实例当对象的实例数超过N这个选项,并输入在被删除前每个对象的文件夹能保留的最大实例数。默认值是100。
- 点击更新。
- 限制每个用户或组的实例数,点击添加按钮旁边的为以下用户/组删除多余的实例选项。
- 选择用户或组,单击>将用户或组添加到选定的用户/组列表,然后单击确定。
- 对于每个您在步骤6添加的用户或组,在每个对象每个用户框最大实例数的选项中,键入要显示在BI平台上的实例最大数量。默认值是100。
- 要限制每个用户或组的实例寿命,单击添加旁边的N天后为以下用户/组选项删除实例。
- 选择用户或组,单击>将用户或组添加到选定的用户/组列表,然后单击确定。
10. 对于在步骤9添加的每个用户或组,在保留实例最大天数的选项中中,键入他们从BI平台中删除之前的最长期限。默认值是100。
11. 点击更新。
下面是一个对话框的截图供您参考:

一旦启用实例限制,你将可以更好地控制你的CMS和输入/输出FRS的大小。一个赘余较多的CMS数据库和文件存储在一般情况下肯定会使BI系统运行较慢,所以这个方法绝对可以帮助保持您的系统以最快的速度运行。
TIP 2.4 – 对平台搜索进行调整
你遇到过一群资源(CPU/ RAM)正在使用您的BI平台服务器但是却没有任何用户活动的情况吗?如果有,这最有可能是平台搜索的持续抓取功能正在进行大批的索引。
什么是平台搜索?
平台搜索,可以让你搜索到BI平台资源库中的内容。它通过将它们进行分类和排序得到相关的细化搜索结果。
毫无疑问,平台搜索是一个伟大的功能!这仅仅是在为了性能设置系统环境时要考虑的一个因素。
以下管理员指南中有关此功能以及如何配置它的内容:
DOC - BI Platform Administrators Guide (BI 4.1 SP4) - Chapter 22 - Platform Search
当BI4.0刚出来的时候,技术支持看到的很多情况就是在客户将大部分内容转移到新的BI4.0系统后遇到的系统性能下降和资源问题。
经过广泛的调查,我们发现,在大多数情况下,这个问题是这个“新”的内容索引被添加到服务器了。
那么,这个是怎样影响性能的呢?增加新的内容到BI4.x为什么会使处理服务器和其他资源枯竭?
在后台,该平台搜索应用程序检测到有需要被索引和目录的新内容。这意味着,对于每一个新的对象(Webi报表,universe,水晶报表等)都需要被搜索服务分析、编目和索引。要做到这一点,这个基于AdaptiveProcessing server的平台搜索服务,将利用Processing server (Webi,水晶等)来阅读报表内容,并生成一个索引,可以用来将搜索条件映射到内容上。这是很酷的功能,但是面对包含大量数据、对象、关键字等的大型文档...这会给系统增加大量的负担。尤其是有很多新的对象被一次性添加的时候。
默认情况下,索引器被配置为连续抓取系统情况并索引对象的元数据。如果你觉得这占用了系统的大量资源,那么你可能要使用计划选项来控制它的运行。避开正常工作时间或高峰时段来运行索引会为您提供最佳的性能。
幸运的是,我们可以配置索引器的使用频率和详细程度。这些选项在管理员指南上面的第22章中有讨论。
总之,如果你的服务器上无法解释的资源消耗,一定要想到平台搜索。
更多信息请参考:
KBA - 1640934 - How to safely use Platform Search Service in BI 4.0 without overloading the server?
.
BLOG - What is the optimal configuration for Platform Search in BI 4.x? - By Simone Caneparo
第三章 – 报表设计的最佳实践
本章将讨论一些报表设计的最佳实践,可以帮助您优化报表性能。每当一个新的报表在设计时,这些技巧都应予以考虑。这些技巧中的很多部分也可以毫不费力地应用于现有报告。
NEW- 下面由william.marcy写的文档中,描述了报表设计技巧和诀窍,虽然不一定和性能相关。这是一个很伟大的文档,所有想要更好的设计报表的人都应该一看。
DOC - Webi 4.x Tricks - By William Marcy & various other contributors on SCN.
TIP 3.1 – 避免“巨型”文档的出现
一个“巨型文档”是指包含许多大报表在内的报表。一个Web Intelligence文档可以包含多个报表。当我们提到Reports,我们指的是在Webi document底部的每一页报表。我们常常使用术语report来指Webi document,但两者之间的区别是很重要的。一个document可以包含多个report。
当创建一个文档,我们需要从实际的业务需求出发。我们可以通过如下对利益相关者的提问做到这一点:
- 这个文档的主要目的是什么?
- 哪些问题是本文档必须回答的?
- 有多少不同的用户会使用这个文档?
- 这个文档可以分成多份文档来满足更小更具体的需求吗?
通过问类似于以上的问题,我们可以知道实际需求是什么并且可以使用这些问题的答案来避免浪费。如果我们创建一个巨型文档,包含每一种用户可能想看到的可能性,那么对于报表设计者和用户来说都可能浪费了大量的时间。例如,如果一个大文件只有10-20%是用户定期需要使用的,那么这意味着该文件的80-90%是浪费。
一旦我们知道消费者的业务需求,我们可以设计一个集中满足需求的文件,消除了许多浪费。
下面是建立一个文档时要记住的几个最佳做法:
1、避免在文档中使用大量分页报表
- i. 10或更少的报告是一个合理的数目
- ii. 在一个文档中超过20份报告的情况应避免
2、针对特定的业务需求创建更小的文件,可以更快的运行和分析
- i. 使用报表链接使一些较小的文档连在一起。这将在TIP3.2做详细讨论
- ii. 每个文档 满足1-2个业务需求。
3、只为文档提供满足业务需求的数据
- i. 每个文档50.000行数据是一个合理的数字
- ii. 每个文档不要超过500.000行的数据
4、不要添加额外的数据提供者,如果不需要或者超越文档的需求时
- i. 5个数据提供者是一个合理的数字
- ii. 每份文件不超过15个数据提供
当然,上述建议也有例外,但我希望大家在发现你的文件过大时,能找到其他方式调查设计文档。
通过只创建满足客户需求的、更小、可重复使用的文件,您可以看到下面这些好处:
- 减少查看报表时的初始加载时间
小的报表将会在查看器中加载更快。这是因为初始处理加载更小的报表所需的资源比较少。
- 减少刷新报表的时间
报表越大,刷新时所需的时间就越多。一旦报表工具从数据提供器那里接收到数据,它就得执行报表内容,并且基于报表设计进行一系列复杂的运算。带有很多变量以及大量数据的大型报表会在刷新时花费更长的时间。
- 减少在客户端和服务器共同需要的系统资源
大型报表比小报表所需要占有的资源要多很多。减小报表的大小,可以有效地节省CPU,RAM以及硬盘等系统资源。这样可以在现有的硬件资源基础上,得到更大的吞吐量。
- 提高编辑报表时的性能
当编辑大型报表的时候,客户端和服务器都得将报表的结构以及数据放入内存中。如果你再报表中进行添加/修改/移动等操作,这将会带来客户端/服务器的交互。这将会减慢分析的过程,因为这些处理需要重新添加进来。在一个报表中对象越多,执行每个编辑操作所需的时间就越长。
- 为用户需要做的特别查询和分析提高了性能
分割,过滤,钻孔等操作在小报表中也能更快进行。这将会加快给客户的响应时间,以便于客户做更具体的分析。
TIP 3.2 – 尽可能使用报表链接
报表链接是将两张报表连在一起的很好的方式。这可以代替向下钻取并且能够让报表设计者更好的控制报表的大小以及性能。报表链接能够帮助减小单张报表的大小。报表设计者可以通过将报表分为几个部分,并且把它们通过链接连起来。这可以非常有效的避免巨型报表的产生。
报表链接的概念非常简单。主要是通过在报表中插入一个超链接来连接另一张报表。这个超链接可以使用来自原报表中的数据来提供一个提示值指定到目标报表。下面是解释报表链接概念的一个例子。
- Sales_Summary是一份总结XYZ lnc公司100个销售点的销售业绩的报告
- Sales_Summary中有一个超链接可以让用户跳到第二张报表(Sales_Details)中去查看100个销售点中每一个销售点的具体销售情况
- Sales_Summary每天晚上都要执行计划,花费20分钟来完成
- 用户只需要花几秒钟的加载时间来查看Sales_Summary最新的实例
- 用户可以通过点击报表超链接来打开Sales_Details报表,查看每个销售点的具体销售情况
- 下拉菜单中的提示值可以用一个查询过滤,仅仅将用户需要看见的那个销售点的报表展示出来
从上面的内容中,我们可以看到许多的好处:
- Sales_Summary报表中只包含了总结信息。因此,与同时包含总结和具体明细数据相比,它在执行时会快很多
- Sales_Summary报表比较小,因此在自身加载或操作时会比较快
- 用户可以通过下钻来得到一个快速的响应时间,因为每个详细的报告只包含了用户感兴趣的那部分数据
在Webi Intelligence用户手册的Section 5.1.3 - Linking to another document in the CMS中,关于这个话题有更详细的阐述。
DOC - Web Intelligence User Guide - BI 4.1 SP04 Direct Link - Chapter 5 - Section 5.1.3
生成这些超链接的最简单的方式就是用超链接向导。这个向导只在HTML接口中可以获得。关于手动的创建超链接,您可以通过下面的链接参考Opendocument的用户手册:
DOC - Viewing Documents Using OpenDocument
下面的是这个向导的截图以及它在工具栏中的按钮。如果您以前没有使用过它的话,可能找起来比较困难:

有一点很值得注意的是,使用这个向导来制作超链接会在计划和设计报表的过程中增加一些时间。虽然使用了这个功能会节省用户的等待时间,同时也会减少对后台资源的需求。
当用opendocument或者HTML超链接向导设置了超链接时,你可以将报表设置为打开时刷新或者去看最新的实例。我们的建议是尽可能去使用最新的实例。这可以在数据库和后台服务器计划加载,从而缩短用户看到报表的时间。
TIP 3.3 – 在不必要的情况下,避免使用自动调整功能
自动调整功能能根据数据自动调整单元,表格,交叉表,或者图表等的大小。以单元为例,它具有根据数据的大小来自动调整高度和宽度的选项。下面的截图是在Applet接口中,对一个单元进行自动调整功能的例子:

这在展示报表时是一个很好的功能,但是在我们浏览页面或者生成一个完整报表的时候,这会带来性能方面的延迟。
注意:单元的默认设置是能够自动调整高度的。这会影响到报表的性能,所以知道它是如何影响性能的就十分重要。
这是怎样影响报表的性能的呢?
当将报表中的对象设置成自动调整,处理服务器必须得对每个实例中的那个对象进行计算来确定它的尺寸。这意味着为了跳到报表中的某一页,处理服务器需要计算在那之前的所有页中这个对象的尺寸。例如,如果在我的报表中有100000行的数据,我想要浏览1000页,那么处理服务器就必须生成1000页之前的所有页来显示那一页。这是因为每一页的对象尺寸是动态的和数据的行相关,所以如果不先计算出之前的每一页,是不能确定在第1000页中显示的是哪些行。
总之,这个选项使生成报表增加了更多的工作。设置一个固定的尺寸可以让处理服务器决定每页放多少个对象合适,并且可以允许它跳过生成那些不需要的页面的过程。
举另一个例子:如果我有100000行的数据并且将对象设置成固定的高度和宽度,那么处理服务器将会知道每页放置50行是合适的。如果我想要看第1000行,它就会知道第50000到50050行的数据会在那一页,然后它会将这些数据放在那一页中呈现出来。这比在它之前生成999页要快太多了!
------------
正如您可以想到的,这个主要是影响那些有很多行和很多页的报表。如果你的报表只有几页,那么可以不必在意这个选项。对于那些更大更长的报表,这点是值得研究的。
TIP 3.4 – 尽可能使用查询过滤器代替报表过滤器
查询过滤器是为报表添加一段SQL语句来进行过滤的工具。查询过滤器通过WHERE语句来限制从数据库中返回的数据。
报表过滤器是在报表层面上使用的过滤器,它只用来过滤显示在报表上的数据。所有来自数据库的数据仍然存在,只是报表本身只显示被过滤后的部分。
虽然有时候会同时使用查询过滤器和报表过滤器,但是了解它们之间的差别是一个很好的方式,能够让你确保在执行报表刷新的时候没有引起不必要的延迟。最好的方式是在语义层设计的时候就提前设计好查询过滤,但是你也可以在Web Intelligence的查询面板中手动添加。
下面是一个预先定义好的过滤器,在查询面板中被添加到一个查询中的截图:
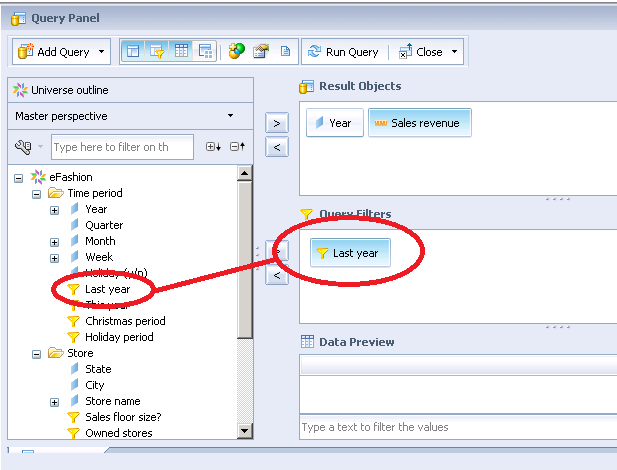
这里还有一个手动添加的相似的查询过滤器:

上面这两种情况都是用WHERE语句基于year进行过滤,从而减少返回到报表中的数据。
同时,您也可以选择如下图一样基于报表过滤来做这件事:

.
在这个报表过滤的例子中,展示的数据是经过过滤后被选中的年份,但是所有年份的数据都存在于cube中。这将会影响到性能,所以请尽可能去使用查询过滤器来限制数据。当然在有些情况下报表是更好的选择,但是为了报表性能,请大家注意一下尽量使用查询过滤器这一点。
TIP 3.5 – 避免使用含多数据点的图表
BI4.0介绍了一种新的图表工具模式叫做常见的可视化对象模型,或者简称为CVOM。这是一个通用的SDK,可以为Web Intelligence和其他的SAP产品提供强大的图表功能。Web Intelligence用CVOM来创建图表以及在Webi内部做可视化发现。CVOM服务依托于AdaptiveProcessing server(APS),并且被称为可视化服务。
这项服务已经默认添加到APS当中,但是根据你的部署中对可视化的使用,你可能想要根据系统配置向导或者APS拆分原则将APS服务进行拆分。
如果我们在CMC中右键APS菜单,选择编辑公共服务选项,我们会看到如下的列表:

这个服务和性能相关的原因是,当资源或者报表大小问题使图表生成花费大量时间时,这个服务就会成为一个障碍。因此确保正确设置这个服务而不会让它成为一种障碍是很重要的。我们会在指定标准的章节中详细讨论这一点。
当我们向负责CVOM模块的开发询问如何提高可视化服务的建议时,他们基于测试结果和开发经验给我们提出了建议。他们建议避免在报表中使用带有很多数据点的大型图表,而是采用带有少量数据点的多个小图表。
这是因为CVOM可以很快的产生图表,如果他们不必跟很多数据点匹配的话。当然,某些业务需求可能会必须要求多数据点,但是为了更好的性能,我们还是建议尽量采用数据点少的小图表。
DOC - Webi User Guide - Chapter 4.3 - discusses Charting with Web Intelligence
TIP 3.6 – 限制使用分析范围
引用Webi用户手册:
“查询的分析范围是你可以从数据库中得到的额外数据,可以为返回结果提供更加详细的信息。
这份额外的数据不会在初始报表中呈现,但是它一直保存在cube中,你可以随时把它们添加到报表中来获得更详细的数据。这种将数据精炼到下一层的过程称为向下钻取。
在universe当中,分析范围和查询对象的层次结构有关系。例如,如果年份下面的一个分析范围将会包含季度,这个会显示在年的下面。
在你创建查询的时候,你可以设置到这个层次。它允许对象下面的一个层次包含在查询中,而不需要这个对象出现在结果中。Universe中的层次结构可以让你选择分析范围以及相应的下钻层次。你还可以通过选择范围内具体的维度来创建分析范围。
分析范围是一个很好的方式,可提供向下钻取功能并将所需的有关下钻的数据“预加载”到cube中。会影响性能的地方就是这些额外的对象会被添加到幕后的SQL语句中。要注意的是通过将对象添加到分析范围,则基本上是将它们添加到将要对数据库运行的查询中。这会影响查询的运行时间,所以做这个决定的时候需要好好考虑清楚。”
作为分析范围的另外一种选择,报表链接可以被用来获得需要的下钻功能。这可以减少对性能的影响,因为它只是发生在需要额外数据的时候。由于一些报表的用户可能不想要对额外数据向下钻取,默认排除这个选项并且为需要下钻的客户提供OpenDocument的超链接来钻取到所需数据是有意义的。”
下面这个例子就是使用数据分析范围来添加季度、月份和周,尽管结果对象中只是包含了年份。
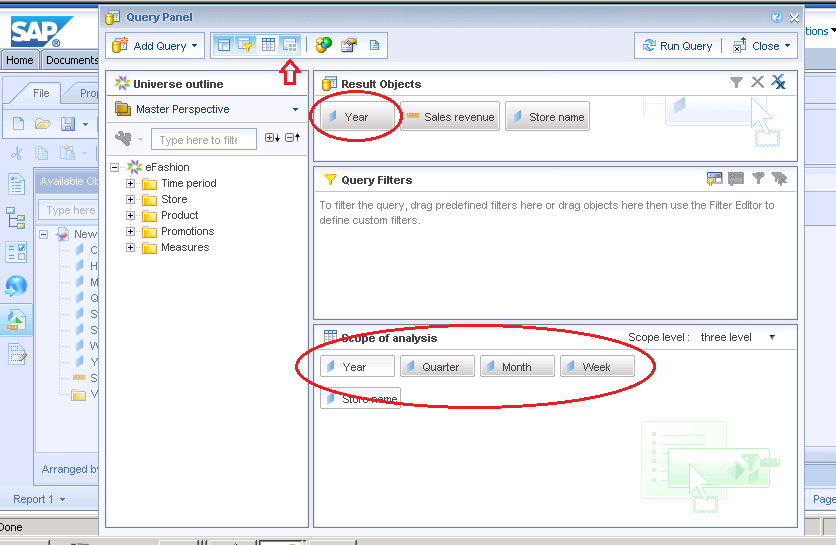
这个是通过编辑让查询中包含季度、月份和周。当然这将会返回更多的数据并能会花费更长的时间来返回。
总之,你应该确保分析范围是经过考虑而使用的,并且大部分报表的用户都能从中获益。另外一种替代方式报表链接已经在上面讨论过了。
TIP3.7- 限制使用的数据提供器数量
为了得到更好的报表性能,最好是将数据提供器的数量限制在15个以内。如果你需要15个以上的数据提供器,那么你可能想要尝试一个不同的方式将数据结合在同一个单一数据源中。运用ELT工具以及数据仓库是一个更好的方式来实现这一点,而且可以将数据的整合放入数据仓库服务器而不是BI服务器或者客户端。
Webi Processing server当前的设计是串联运行数据提供器。这意味着每一个数据提供器都是一个接着一个运行的,而并非我们期待的并行运行。所以,所有数据提供器的运行时间的总和就是报表得到数据需要花费的时间。
下面是运用多个数据提供器的报表需要花费的时间的展示:

对于一个有很多数据提供器的报表来说,另外一个需要考虑的就是在不同数据源中进行合并维度的时候,会增加更多的处理时间。所以,用少量的数据器会获得具有更好性能的报表。
TIP 3.8 - 不要禁用报表缓存
Web Intelligence使用硬盘和内存缓存来提高加载处理报表和universe的性能。在正确实施的情况下,这可以有效地提高常用报表和universe的初始加载时间。
有一个好消息就是在很多情况下缓存都是默认生效的,所以这可以自动被用户们使用。有一些情况下缓存是不可以被使用的,所以我们需要报表设计者们清楚这一点:
下面这些函数会让一个报表避开使用缓存:
CurrentDate()
CurrentTime()
CurrentUser()
GetDominantPreferredViewingLocale()
GetPreferredViewingLocale()
GetLocale()
GetContentLocale()
如果你在报表中使用这些,那么缓存就不会被使用。这些函数是很常用的,所以意识到它们对缓存的影响很重要。
目前,缓冲只作用在文档的水平上,而不是单独的每一个报表(tab)。因此,只要这些函数出现在文档中,那么对于这之后的所有请求,缓存都将不会被使用。
TIP 3.9 – 在向下钻取的报表中使用查询钻
什么是查询钻?下面是引用Web Intelligence用户手册:
“当你激活了查询钻,除了下钻过滤器之外,在对查询进行编辑以及改动的时候(增加和移除维度、查询过滤)也会执行下钻。
在报表中含有在数据库进行运算的聚合型数值时,你将使用查询钻。它是专门被设计用来提供的一种下钻模式,来适应如Oracle
9i OLAP这样包含Web Intelligence中不支持的聚合函数或者在下钻时不能做聚合运算的数据库。
查询钻对于减少下钻过程中储存在本地的数据量也有帮助。因为查询钻减少了下钻时的分析范围,它能清理不需要的数据。”
性能提高可以通过减少Webi报表存储在本地的数据量以及将一些聚合函数放在数据库端进行来实现。
通过这个选项获得的性能提高可能不会被察觉,但是它足够简单,我们可以测试是否能够提高性能。想要让这个选项生效,请到文档属性中,选择“使用查询钻”这个选项。下面是这个选项的截图:

.
第四章 – 语义层的最佳操作
下面最佳操作的大多数内容都包含了语义层,语义层我们也经常称之为SL。这些最佳操作可以帮助您设计更快的查询,从而得到运行更快的Webi报表。
TIP 4.1 – 只合并那些需要的维度
合并维度是一种机制,能将来自不同数据提供器的数据同步。例如,如果你的文档有2个数据提供器并且它们都有一个叫做“产品名称”的维度,你就可以将这两个不同的维度合并成一个包含每一个数据提供器中产品名称的完整列表,成为“合并的”维度。
BI4.x的Web Intelligence在默认情况下将自动合并维度,所以您可以通过查看合并的维度来评估是否有性能方面的提升。如果你不想让维度自动合并,你可以将您的报表文档属性的“自动合并维度”取消。
我们在Webi报表中有两个文档属性可以影响合并维度:
自动合并维度- - 将来自同一个universe中具有相同名字的维度自动合并
拓展合并的维度值- -此选项将会自动在一个维度中包含合并后的维度值,即使合并后的维度并没有在表中使用。
合并维度通常都会影响Webi报表的性能。如果您不需要某些维度在您的报表中被合并的话,您可以选择不合并它们。这样会避免由于合并维度而带来的性能问题。另外,如果之后您需要的话,也可以重新合并它们。
总之,为了在较大报表中提高小部分性能,我们可能有必要去尝试取消已经合并了的维度。
TIP4.2 – 为报表的业务需求建立universe和查询
和任何一个成功的项目一样,获得一个成功的Webi报表的关键就是一个良好的计划。这可以帮助避免设计出的报表出现范围/功能的蔓延。在设计阶段,清楚明确的确定报表的业务需求是很重要的。一旦你了解了业务需求,你就可以制作出一份只包含需求信息的倾向性文档来满足这些需求。
正如之前所说的关于“巨型”文档的一些技巧,我们同样也需要避免“巨型”查询/universe的产生。事实上,一个universe或者查询越大,性能就会越糟,而且会耗费过多资源。通过只满足业务需求,我们可以将查询的大小控制在最小范围,并且能够优化报表的运行时间。
举一个真实的例子,我曾经看到过一张报表建立在一个包含了300多个对象的查询之上。这个报表需要返回500000行的数据,并且花费45分钟以上的时间来完成。在检查报表的时候,我们发现只有1/4的对象被用到。当询问为什么会使用超过300多的对象的时候,他们却无法给出答案。如果我们按照数学方式来计算,300个对象x500000行=150万单元格。这张报表在设计时可能是考虑了查询可以满足的所有情况下的数据,而没有关注报表用户的实际需求。
总之,了解谁将会用到这些universe以及他们的需求是什么是非常重要的。在此基础上,你就能创建一个精简的、有倾向性的universe以及查询,能够以最优化的方式来满足这些需求。
TIP4.3 – 数组提取大小的优化
数组提取大小(AFS)是在执行Web Intelligence文档的时候能够同一时间提取的最大行数。例如,如果你运行一个查询返回100000行数据,你将数组提取大小设置为100,那么将会按照每次提取100行,一共需要1000次来提取所有的行。
在更新的Web Intelligence版本中,我们会根据查询中包含的对象的数量来自动确定一个最优的AFS。在大多数情况下,自动确定的结果会在返回数据的过程中获得优化。虽然有些时候,通过我们手动将这个数值调大能够得到更好一些的性能。
我在我的测试环境中做了一些测试,下面是不同AFS设置值产生的结果:
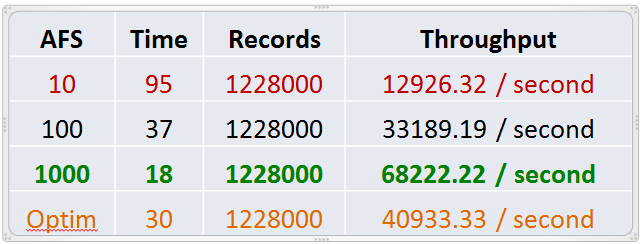
正如您所看到的,运行同一个查询的时间是基于AFS设置而发生变化的。最优值(我认为差不多是700左右)需要花费将近30秒的时间。不按照这个来设定,我将AFS设置为1000,我们能得到18秒的更优结果(又缩短了12秒)。这对于性能来说是非常好的事情,但是我们需要注意的是,这意味着为网络增加更多的负担,同时也需要额外的内存来容纳更大的提取。
正如我所提到的,在默认情况下,最优的数值会在新建连接和universe的时候被用到。想要无视这个最优值,而测试自己填写的数值,你需要在Universe的变量设置"DISABLE_ARRAY_FETCH_SIZE_OPTIMIZATION"中将AFS最优的选项设置为无效。
将这个设置成“Yes”会使最优值无效,之后你可以在连接中设置自己的AFS值。
关于这个的更多信息,您可以参考下面的Information Design Tool或者Universe Designer的文档:
DOC - Information Design Tool User Guide (BI 4.1 SP4 - Direct Link)
.
DOC - Universe Design Tool User Guide
TIP4.4 – 确保查询剥离是生效的
查询剥离是一个可以自动从查询中删除没有用的对象的功能,从而能够提高性能,减少存在cube中的数据。查询剥离原来只可以在基于Bex Query的BICS中使用,但是从BI4.1SP3开始,关系数据库的连接也可以使用。
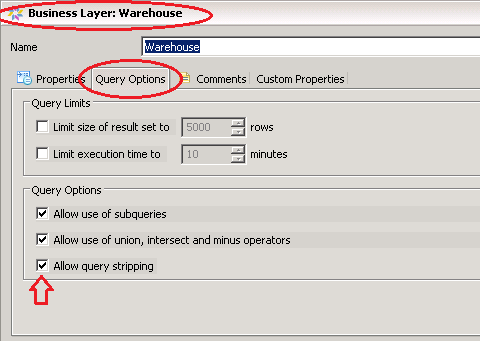
查询剥离可以通过设定三个选项在关系数据库中生效:
1. 在Universe的业务层中,选择“允许查询剥离”
2. 在Webi文档的属性中
 .
.
3. 在查询属性中
.

最好再三确认一下这三个地方是否都设定了查询剥离。如果其中的任何一个没有设置的话,这个查询剥离的功能就不会被使用。
还有另外一种方式来判断它是否生效。如果查询剥离生效的话,刷新查询然后去查询面板中点击看SQL的按钮。你应该可以看到只有一部分对象被报表使用。在这个例子中,我在报表中只使用了6个对象中的3个,所以查询就只选择了这3个对象。

从上面可以看出,SQL已经将没有用到的对象剥离了出去,所以结果会运行的更快。
基于BICS的报表,查询剥离功能是默认生效的。
总之,在刷新报表时,请确认报表使用了查询剥离的功能。
TIP4.5 – 遵循SAP BW(BICS)报表的优化建议
在下面的文档中包含了很多好的信息。它介绍了很多基于SAP BW 报表的最优做法。请参看下面的手册来获得更多有关基于BICS的报表的一些优化性能问题:
DOC - How to Performance Optimize SAP BusinessObjects Reports Based Upon SAP BW using BICS Connectivity
.
TIP4.6 – 使用索引感知来获得更好的性能
索引感知在Information Design Tool用户手册的12.7章节中有如下描述:
“索引感知是能够利用主列的索引来提高查询性能。
在业务层中的对象是基于数据库中对查询数据有意义的列。例如,一个叫做客户的对象,从客户表中将客户名的那一列的值取回。在很多数据库中,客户表都有一个主键(例如一个整数)来让每个客户区分彼此。这个主键值对于报表来说没有意义,但是对于数据库的性能来说具有很大的意义。”
当你建立索引时,你在业务层的维度和属性中确定了数据库的哪些列作为主键,哪些作为外键。建立索引的好处如下:
- 在主列上的连接和过滤比没有主列更快
- 因为在查询中需要的连接越少,因此会有更少的表被需要。例如,在一个星形数据库中,如果你建立的一个查询包含了一个在维度表中的过滤值,这个查询可以通过运用维度表的外键来从表中直接进行过滤
- 独特性可以再过滤盒值列表中得到体现。例如,如果两个客户具有相同的名字,程序只会取回一个客户,除非它知道每个客户都有一个不同的主键”
使用索引可以帮助提高性能,因为在查询中,主列会被用来进行更快的查询以及在数据库端的连接。
Information Design Tool用户手册的如下章节中包含关于索引意识的问题:
DOC - Information Design Tool User Guide (BI 4.1 SP4) - Chapter 12
TIP4.7 – 使用聚合感知来获得好性能
聚合感知在IDT用户手册中有如下的阐述:
“聚合感知是一个关系universe利用包含预先汇总数据(总表的)的数据库表的能力。设置聚合感知可通过处理更少的事实和聚合更少的行来加速查询。
如果一个聚合感知对象被包括在查询中,在运行时,查询生成器从与查询匹配的具有最高聚合层级的表中取回数据。
例如,在数据层中有一个事实表是关于事务级的销售细节的,另一个聚合表是每天的销售求和。如果查询请求销售细节,则该事务表被使用。如果查询请求每天销售,则该聚合表被使用。使用哪个表是对用户透明的。
在universe中建立聚集感知有几个步骤。可以参考相关的话题来获得更多的信息。”
用数据库来预先汇总数据可以帮助提高Webi报表的性能。这是因为Webi Processing Server不必在本地去做聚合,它只需要处理来自数据库的聚合数据即可。
在聚合数据有实现的意义的情况下,尽量使用聚合数据。
TIP4.8 – 运用JOIN_BY_SQL来避免多重查询
参数JOIN_BY_SQL决定了在SQL的自动生成过程中如何来处理多重SQL语句。在默认情况下,在SQL的自动生成过程中,多重SQL语句是不会被合并的。但在某些情况下,通过允许合并多重语句来得到性能的提高。
JOIN_BY_SQL参数可以在Information Design Tool的业务层(和/或)数据层被找到。下面是默认状态下这个参数的截图:

通过将它的数值改为“是”,在SQL的自动生成过程中,会尽可能的将多重语句合并起来,而加快查询的执行速度。
所以对于universe或者报表的性能改善来说,这个选项是值得考虑并测试一下的。
TIP 4.9 – 关于语义层的安全性能考虑
毫无疑问,在我们处理一些敏感性数据的时候,安全性是非常重要的。这一节的目的就是来帮助您尽可能地精简您所使用的安全性能模式。如果在语义层和BI平台(用户和分组)两个层面上同时设置了安全性能模式,在很多时候会使报表性能得到严重的影响。
举一个例子,在我最近处理的一个incident中,在我们分别使用管理员账户和另外一个用户账户打开一个webi报表的时候,我们能够看到性能上有10-40%的差距。通过调查,我们发现这个用户是70多个分组的成员,所以大量的加载时间全部都耗费在了权限的聚集和查询中。
与此同时,我们也发现了在我们产品的代码中存在一些没有用的部分,我们会在未来的Support Packages/Minor
Releases中进行优化。这些信息可以为那些没有意识到由于混合性的安全性模式所带来的性能影响的用户提供很好的优化性能方式。
因此,关于这个章节的内容,您可能会想要采取以下的一些行动:
- 重新检查一下您的业务需求,减少或者移除那些没有必要的数据,或者在universe层上没有必要的业务层安全性模式。
- 考虑在业务层使用Change State或者“Hidden”选项来隐藏那些你不想让其他用户看到的信息。
- 考虑在业务层设置使用权限来控制哪些用户可以使用哪些对象
- 减少用户所从属的用户组/角色的数量
- 用管理员用户来测试性能,并将它和那些有限制权限的用户进行对比,从而发现安全性模式对性能方面的影响。
第五章 – 关于公式和计算工具的技巧
这些技巧来源于产品开发关于后台的计算工具如何开展计算能提高性能的一些方式。
TIP5.1 – 对于带有条件的嵌套部分要警惕使用
一个嵌套部分就是一个部分套着一个部分。例如,你可能有一个国家部分,它里面包含着区域部分。这就被看做是嵌套部分。嵌套部分花费的时间是添加在报表的渲染/处理时间中的。尤其是当你添加了条件时,比如“当……的时候,隐藏这个部分”。这并不意味着你不应该使用嵌套部分,它们当然会使你的报表做成你想要的样子,但是在大量使用嵌套之前,你应该考虑一下它们对于性能的影响。
下面是一个基于eFashion的报表的四层嵌套:
下面是格式部分的选项,如果过多使用就会影响到性能:

.
当在嵌套部分中使用条件的时候,计算工具就需要指出哪些部分是要被展示的。有越多的嵌套,就需要更多的时间来指出都有哪些层次是真实可见的。所以,让我们再重述一次,虽然在大多数情况之下,嵌套是很有用的,但是对于在嵌套部分中有成百上千个维度以及和它们关联的条件时,这个会大大影响性能。
TIP5.2 – 尽量用IN来代替ForEach和ForAll
这个技巧是直接来自于我们从事计算工具开发工作的开发者。在这些模式的底层,相比于ForEach和ForAll的语句来说,当用IN的时候,代码的运行是更加有效的。
下面的文档可以在我们的help portal上面获得。它包含了关于Webi报表中的函数,公式,计算,语句等.更详细的信息:
DOC - Using functions, formulas, and calculations in Web Intelligence (BI 4.1 SP3)
4.3.1.1章节包含了“IN”上下文运算符的一些进行运算时的例子。总之,IN运算符明确指定在上下文中的维度。
4.3.1.2和4.3.1.3章节包含了ForEach和ForAll上下文运算符。总之,这两个函数能够让你编辑默认的上下文,通过从计算内容中添加和去除维度。
在很多情况下,IN可以获得和ForEach,ForAll一样的结果,所以如果你觉得用这可以帮助提高性能,可以尝试用IN公式来代替。
TIP5.3 – 尽量用IF...THEN...ELSE 来代替Where
在很多情况下,IF/THEN/ELSE语句能代替WHERE。根据开发者的意见,这对于计算工具来说是更加有效率的。如果你怀疑用Where语句年能够影响到报表的性能,那么尝试把它换成IF语句。
下面的文档关于这些语句做了更详细的描述:
DOC - Using functions, formulas, and calculations in Web Intelligence (BI 4.1 SP3)
.
6.2.4.14章节包含了Where 语句的用法以及一些例子
6.1.10.11章节包含了IF...Then...Else的功能
TIP5.4 – 分解(重复使用)变量
分解变量的本质是将它们在其他变量中重复使用。通过这个,你可以减少在得出结果之前运算工具所进行的计算数量。
下面是一个分解变量的例子:
v_H1_Sales= Sum([Sales Revenue]) Where ([Quarter] InList("Q1";"Q2"))
v_H2_Sales= Sum([Sales Revenue]) Where ([Quarter] InList("Q3";"Q4"))
现在,我们将这两个变量重新使用来获得Years sales (H1+H2 )
v_Year_Sales= v_H1_Sales + v_H2_Sales
通过重复使用变量,对于那些已经算出结果的变量,我们节省了需要重复计算的时间。上面是一个很简单的例子,但是如果把这种模式放在更复杂的运算中,这确实会节省很多计算的时间。
第六章 – 为性能做设定
得到更快的报表性能的一个关键就是为后端的组件做一个恰当的设定。通常情况下,我们看到系统初始第一天的使用被正确设定,但是从超过初始设定值开始,由于达到了资源的限制,出现了性能方面的问题。为系统今天和近期的使用情况作设定是很重要的。在一年中执行几次检查,看看是否超出了初始设定也是同样重要的事情。
更新:Ted Ueda写了一篇很好的文章,为这一点提出了一些很好的很具体的建议。下面是这篇文章的链接:
BLOG - Revisit the Sizing for your deployment of BI 4.x Web Intelligence Processing Servers!
下面的这些技巧可以帮你设定自己的系统来提高性能,同时可能还会帮助你避免一些在我们支持过的问题中经常出现的一些问题。
TIP6.1 – 用这些资源来帮助你设定你的环境
为了性能来设定BI平台并不是很容易。因为每一个安装都有一套不同的内容,用户,节点,权限,数据等……如果没有一些准备和实践练习的话,是很难做设定的。
下面的资源可以帮助你在你的环境中做一个设定的训练:
DOCSizing and Deploying SAP BI 4 and SAP Lumira
.
DOCSAP BusinessObjects BI4 Sizing Guide
.
XLS - SAP BI 4x Resource Usage Estimator
为了完成一个设定的练习,你会想要用到上面的设定手册和资源使用评估。你可能也需要了解一些关于硬件的知识和什么是良好的系统使用方式来做一个合适的设定。
TIP6.2 – 不要将XI3.1的设定重复使用在BI4.x的系统中(32位VS 64位)
一些管理员通常犯的错误就是将在XI3.1中的设定直接重复用到他们的BI4.x环境中。BI4.x并不是一个简单的升级,它同时包含了一些架构上的巨大改变,这些在正确设定一个环境的时候是需要被考虑的。在BI4.x中一个最大的改变就是对64位进程的包容。这克服了XI3.1的一个主要的设定变量限制,就是内存限制。
XI3.1都是32位的进程。在Windows系统中,这意味着每个进程可以获得的最大内存是大概2GB。在大多数情况下,这对一个系统来说是限制性的而且是可扩展的,尤其是对于Web Intelligence。Web Intelligence Processing server (WIReportServer.exe)在悬挂或者是崩溃之前只能够获得2GB的内存用于使用。在一个Linux系统中,这可以增加到大约4GB,但是通过几个大型报表的访问请求,同样可以很快就达到这个值。由于这个原因,我们的建议就是去在一个单一的节点上配置多个Web Intelligence Processing Server(WIPS)。例如,如果你有32GB的RAM,你可能会在机器上设置12个WIPS来获得24GB的RAM。这仍然有可能会使某一个单独的WIPS达到2GB的上限,但是通过平衡负载,到达限制值的几率大大降低了。
在BI4.x中,WIPS现在是一个64位的进程。这意味着2GB的限制不再是一个问题。在上面的例子中,你可能想要将WIPS的数量减少到2而不是12.在一个2x64位的服务器中,你可以用服务器上所有可获得的RAM,仍然可能产生故障和错误。从技术角度将,你可以只设置一个WIPS,但是如果因为某种原因这个服务器发生了故障或出错,你可能不会有第二个来顶替克服这个故障。
同时对于Adaptive Processing Server也有一些很主要的不同点。在设定BI4.x系统的时候应该被考虑。下一个技巧描述中会详细讲解这个问题。
总之,对于一个升级到BI4.x的系统,请重新进行系统设定。
TIP6.3 – 确保Adaptive Processing Server是被分割且正确设定的
当4.0刚发布的时候,有很多性能和稳定性的问题都是与Adaptive Processing Server(APS)和它所提供的服务资源不足相关的。很显然,BI4.x安装了一个APS并且配置了21+的服务在上面。这21个服务为BI平台提供了不同的功能,包含了从平台搜索到universe连接。如果你没有正确的分割和设定APS的话,那么在部署中肯定会遇到资源和性能相关的问题。
Web Intelligence中所关注的,有三个主要的服务都是基于APS的,并且能够直接影响一个Web Intelligence报表的性能。这些是:
- DSL桥服务 用来做BICS(SAP BW Direct access)和UNX(universe)连接
- 可视化服务 用来创建图表以及在Web Intelligence报表中的可视化
- 数据联合服务 被多数据源的universe和数据联合使用
平台搜索服务在使用Webi Processing server来建立webi数据索引时也可以影响到Webi的性能。
在BI4.0发布了不久之后,SAP发布了一个APS的分割手册帮助系统管理员如何分割APS从而更加适应于他们的系统使用。下面是连接到这个手册的一个链接。它包含了很多详细信息,对于负责BI4.x部署的每一个人都应该阅读。
DOC - Best Practices for SAPBO BI 4.0 Adaptive Processing Servers
这份文档阐述了APS进程的结构以及安装在上面的所有不同的服务。上面有一些关于如何将需要较少资源的进程和需要较多资源的进程分成一组。这将会有效的平衡APS服务数量以及性能。
在中央管理控制台(CMC)中同时还有一个系统配置向导。这个向导将会为APS做一些简单的分割来作为新安装时的基础。尽管如此,SAP仍然建议您为自己的系统做一个更加合理的系统配置。
TIP6.4 – 在设计环境的时候,请考虑地理位置和网络状况
网络传输的速度在BI环境的性能影响很大。了解什么时候会发生瓶颈,以及如何确保网络不会影响到性能是十分关键的。
在Web Intelligence Processing Server/APS(DSL桥服务)和报表数据库之间具有一个快速、稳定的网络是很重要的。这是因为从Webi 报表中恢复取回的数据必须通过网络从数据库服务器传到WIPS或者APS进程。在大多数情况下,最好将Processing servers和数据库放在同一个网络段中,但是如果不能做到的话,保证两者之间有高速稳定的网络仍然至关重要。
如果你怀疑网络情况导致了性能上的瓶颈,你应该运用BI平台、网络或者数据库的trace来判断究竟瓶颈出在哪里。
TIP6.5 – 用本地的快速存储来储存缓存和临时路径
有一些管理员将Web Intelligence Processing servers的缓存和临时路径文件放到一些网络附加存储设备当中。
在多数情况下,这样做是没有必要的,除非网络存储和本地硬盘存储一样快,或者更快一些,这可能成为瓶颈。Web Intelligence的缓存和临时文件并不是很重要的元素,所以没有必要去做备份或者保证它的高级可用性。如果一个WIPS没有找到它需要的缓存或者临时文件,那么它就会重新创建。重新创建文件会造成一点的性能影响,但是用本地存储有时可能会有一些丢失文件的几率。
用NAS,网络问题可能会引起整个文件系统或者网络传输的运行中断,这会降低系统性能。用本地磁盘来存储缓存和临时文件是更便宜更快捷的选择。
TIP6.6 – 确保你的CPU速度是充足的
BI系统所获得的处理器和内核的速度能直接对工作性能产生影响。我看见过一个客户的情况,客户的生产环境比他们的测试环境的性能慢一些。在调查这个问题时发现,这个问题决定于CPU的速度。在生产机中,他们有128个内核以1200MHz的速度在运转。这对运行在各个线程上的当前要求来说已经是很好的了。QA只有8个内核,但是CPU是2.8GHz的处理器。所以,当做一个简单的流程比较时,QA比生产机的反应更快。生产机可以处理一个高负载的用户使用,但是生产能力相对慢一些。
在现阶段,大多数的机器都有一个很快的处理器,所以这一点可能大多数人不会在意。出现这样的问题较多的是运用一些较旧的UNIX机器环境的情况。
TIP6.7 – 用BI平台支持工具来为设定做检查
BI平台支持工具(BIPST)是一个很好的可以收集BI4.x系统环境信息的工具。如果你还没有使用这个工具,我强烈建议你下载使用。下面是BIPSI portal的链接:
WIKI - BI Platform Support Tool
这个工具可以从上面的链接中下载,并且链接中包含了一个Webinar(网络研讨会议)来介绍工具的功能特点以及如何使用。这个Wiki本身也针对这个工具的特点给我们做了一个很好的描述。
对于设定检查,这个工具是十分有用的,因为它可以让你了解你所拥有和设定的所有服务器的情况。同时,它也让你知道在做设定练习时,环境中所有可用的用户和内容。
第七章 – XI3.1和BI4.x的架构不同点
即将发布- 请关注文章的更新
第八章 – 基于性能的改进和提高
即将发布- 请关注文章的更新
2 Comments
Related Content
- SAP Intelligent Clinical Supply Management goes CTS Europe 2024 – our key insights in Supply Chain Management Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- RISE with SAP Advanced Logistics Package in Supply Chain Management Blogs by SAP